







VIT(Vision Transformer)来自于google 的一篇文章《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》原文地址: https://arxiv.org/pdf/2010.11929.pdf 使用transfomer解决分类问题。
一说图像分类,大家想到的都是经典的CNN,Resnet,MobileNet
VIT是最近提出的模型2020年10月挂到av上面,2021年正式发表。在所有公开数据集上都超过了Res,前提是在大的数据集上做预训练,数据越大效果越好。transformer使用在NLP上的模型。在2017年 VIT本身没有新的地方,Transformer encode的网络。
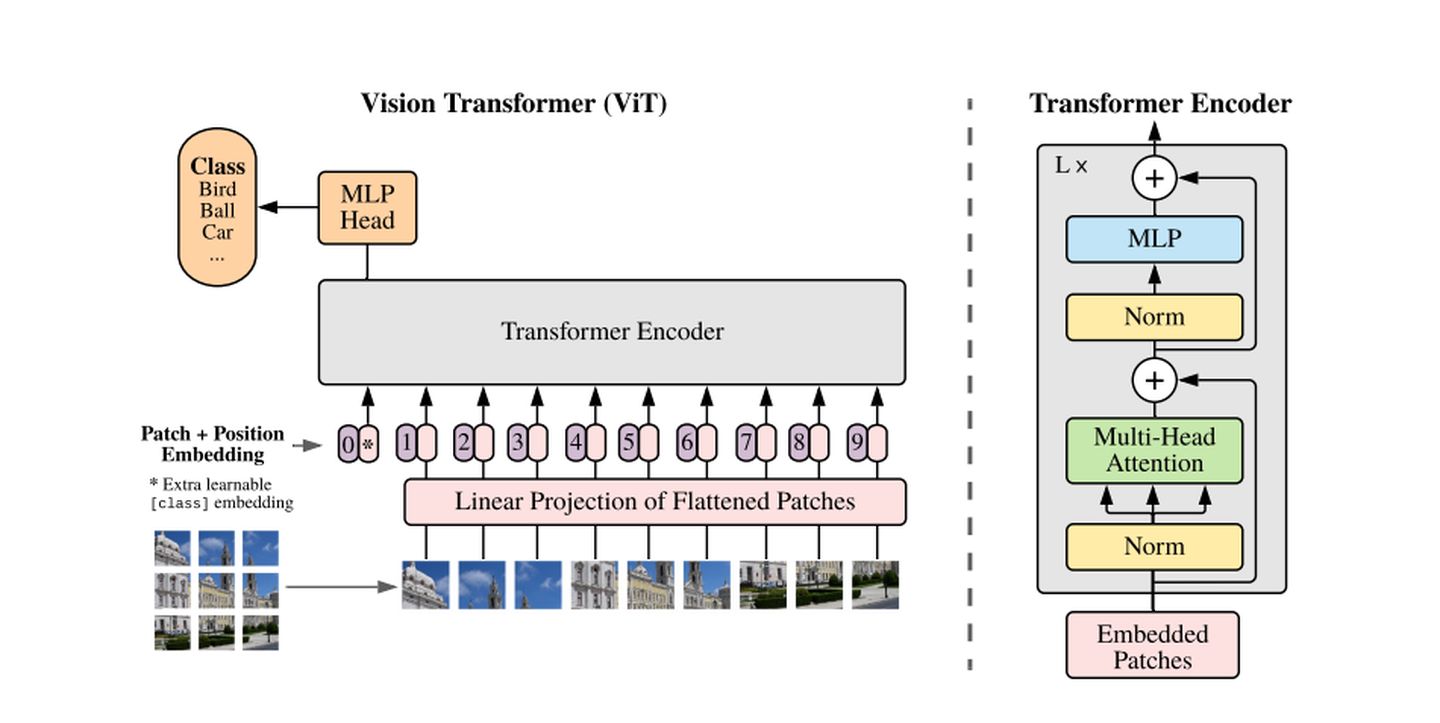
VIT网络是什么:
1)分隔图片
将图片划分成大小相同patches
用户指定patch大小(16x16)stride(滑动窗口的步长),stride越小,分隔的pathes数量越大,计算量越大。论文中没有重叠分隔图片。重叠也可以。
2)向量化(vectorize)
数据向量化,降低维度。
3)
如果图片被划分为n个向量 x1 .. xn

首先用相同全联结层对n个向量进行线性变换。不使用激活函数。共享参数 w和b
zi = dense(xi) = w * xi + b + positionencoding(xi)

此外对向量的位置进行编码 positional encoding。图片被划分为N块,那么位置就是1~n的整数。每个位置就是一个向量,加到Z向量上。z就是内容的表征也是位置的信息。
为什么使用positional Encoding,因为图片的特征跟patches之间的位置是强相关的。所以位置信息是强的特征信息。
最后用CLS符号表示分类。对CLS做Embeding得到向量Z0,Z0和其他Z大小相同。
将Z0 ~ Zn输入到多头子注意力层(Multi-Head Self-Attention)这层的输出也是N+1个向量。在上面加一个全链接层。输出还是N+1个向量。可以继续加Multi-Head Self-Attention 和 全联结层。
transformer还用到了Skip Connection 把每层的输入加到输出上。

Transformer Encoder network用到了很多多头子注意力层和全联结层,用多少都可以。输出N+1的向量。输出是向量C0 ~Cn
但是有用的事C0,可以看作是图片中提取的特征向量。用于分类任务。把C0输入到Softmax分类期,输出向量P,用P做分类的loss梯度,来训练神经网络。
训练方法:
1)随机初始化网络,在数据集A上做训练,数据集一定要大的预训练模型。
论文中使用imageNet(small)训练 resnet和transformer的时候,transformer的效果会低于resnet。用imageNet-21K做预训练数据集,transformer的效果resnet差不多。用JFT(3亿数据)数据集做预训练,transformer比resnet准确率高1%左右。
用更大的数据集作预训练
2)使用pretrained model在数据集B上finetunel。
















 3259
3259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









