







/**********************************************************************************************************
*文件说明:
* 运行caffe自带Mnist示例----过程详解
*时间地点:
* 陕西师范大学----2016.10.27
***********************************************************************************************************/
(一)概述
为了程序的简洁,在caffe中是不带练习数据的,因此需要自己去下载相应的训练集和测试集数据.但是,在caffe的根目录下的
[data文件夹]中,作者已经为我们编写好了下载数据的[脚本文件],我们只需要联网,运行这些shell脚本就可以了。
(二)Mnist简介
mnist是一个手写数字库,由DL大牛YanLeCun进行维护.mnist最初备在美国被用与支票上手写数字识别,现在成了DeepLearning
的入门练习示例,针对mnist识别的神经网络的专门模型是Lenet,算是最
早的CNN模型了.
1---mnist数据的---训练样本为60000张
2-----------------测试样本为10000张
3-----------------每个样本为28*28大小的黑白图片
4-----------------手写数字为0-9,因此分为10类
需要注意的是:
Mnist数据库中的每张图片都进行了:
1---尺寸的归一化处理(所有的图片均为28*28像素大小的图片)
2---数字进行了居中处理
第三点需要注意的是:
利用shell脚本get_mnist.sh下载下来的数据不是图片数据(三)mnist的具体运行过程
[1]下载Mnist的训练和测试数据集
1--sudo sh ./data/mnist/get_mnist.sh(提前切换到caffe的根目录下)#下面我们来看一下get_mnist.sh这个脚本文件的代码,这个脚本文件在/home/wei/caffe/data/mnist/目录下:
#!/usr/bin/env sh
# This scripts downloads the mnist data and unzips it.
DIR="$( cd "$(dirname "$0")" ; pwd -P )"
cd "$DIR"
echo "Downloading..." #[1]输出提示信息,进行训练样本数据和测是样本数据的下载
#[2]下面的这个shel脚本中的循环语句就循环下载了下面四个文件:
#1---train-images-idx3-ubyte
#2---train-labels-idx1-ubyte
#3---t10k-images-idx3-ubyte
#4---t10k-labels-idx1-ubyte
for fname in train-images-idx3-ubyte train-labels-idx1-ubyte t10k-images-idx3-ubyte t10k-labels-idx1-ubyte
do
if [ ! -e $fname ]; then #[3]使用wget下载工具在下面这个网址下,进行数据文件的下载
wget --no-check-certificate http://yann.lecun.com/exdb/mnist/${fname}.gz
gunzip ${fname}.gz #[4]由于下载下来的文件是gz压缩文件,所以在这块进行解压缩
fi
done
2--运行成功后,在./caffe/data/mnist/目录下有四个文件:
1--train-images-idx-ubyte-----训练样本集合
2--train-labels-idx1-ubyte----训练样本对应的标注的集合
3--t10k-images-idx3-ubyte-----测试图片集
4--t10k-labels-idx1-ubyte-----测试样本对应的标注的集合
下载下来的这些数据不是图片形式,也不能在caffe中直接使用,需要转换成LMDB数据库的数据的形式(caffe中使用的
数据库形式之一)
[2]转换成LMDB数据
1---sudo sh ./examples/mnist/create_mnist.sh 现在我们来看一下/home/wei/caffe/example/mnist/create_mnist.sh这个shell脚本文件的代码:
#!/usr/bin/env sh #[1]这一行是你用vim创建一个shell脚本默认生成的
# This script converts the mnist data into lmdb/leveldb format,
# depending on the value assigned to $BACKEND.
set -e
#[2]定义路径变量
EXAMPLE=examples/mnist #[1]转换成功之后的LMDB数据存储的位置
DATA=data/mnist #[2]我们上一步下载的原始数据的位置
BUILD=build/examples/mnist #[3]执行数据转换的程序所在的位置
BACKEND="lmdb" #[3]转换成功之后的数据类型:LMDB形式
echo "Creating ${BACKEND}..." #[4]输出提示信息,$在shell编程中,表示引用变量
rm -rf $EXAMPLE/mnist_train_${BACKEND} #[5]如果已经存在转换成功的数据,删除
rm -rf $EXAMPLE/mnist_test_${BACKEND}
#[6]开始进行数据转换
$BUILD/convert_mnist_data.bin $DATA/train-images-idx3-ubyte \
$DATA/train-labels-idx1-ubyte $EXAMPLE/mnist_train_${BACKEND} --backend=${BACKEND}
$BUILD/convert_mnist_data.bin $DATA/t10k-images-idx3-ubyte \
$DATA/t10k-labels-idx1-ubyte $EXAMPLE/mnist_test_${BACKEND} --backend=${BACKEND}
echo "Done." #[7]执行完毕,输出Done
#[1]第一部分---$BUILD/convert_mnist_data.bin----调用/home/wei/build/examples/mnist/文件
# 夹下的convert_mnist_data.bin可执行程序,这个程序将原始数据转换为LMDB格式的
# 程序,起作用相当于windows下的exe可执行文件,这个可执行程序所对应的源文件为
# /home/wei/caffe/examples/mnist/convert_mnist_data.cpp
#[2]第二部分---$DATA/train-images-idx3-ubyte----$DATA/train-labels-idx1-ubyte----要进行
# 转换的原始数据
#[3]第三部分---$EXAMPLE/mnist_train_${BACKEND} --backend=${BACKEND}---指定转换之后的数据
# 格式和数据存储的位置2---此块需要注意一下:
/********************************************************************************
*1---我刚开始运行的时候,出现了错误
*2---错误的类型是:大概的意思就是,在抓换数据格式的时候,找不caffe/build/examples/mnist
* 的cpnvert_mnist_data.bin或者找不到其他文件
*3---错误原因:1--你在编译caffe源码的时候有问题2--也有可能是你的执行权限的问题
*3---千万不要按照网上的操作:什么剪切caffe目录下的build文件夹到桌面,再新建build,camke
*4---正确的做法是:
* 切换到caffe根目录下,重新编译一下caffe源代码,所有问题迎刃而解
********************************************************************************/
3---如果这条命令执行成功,即数据格式转换成,那么就会在/home/wei/caffe/examples/mnist
文件夹下生成两个文件夹,分别是:
1---mnist_test_lmdb
2---mnist_train_lmdb
如下图所示: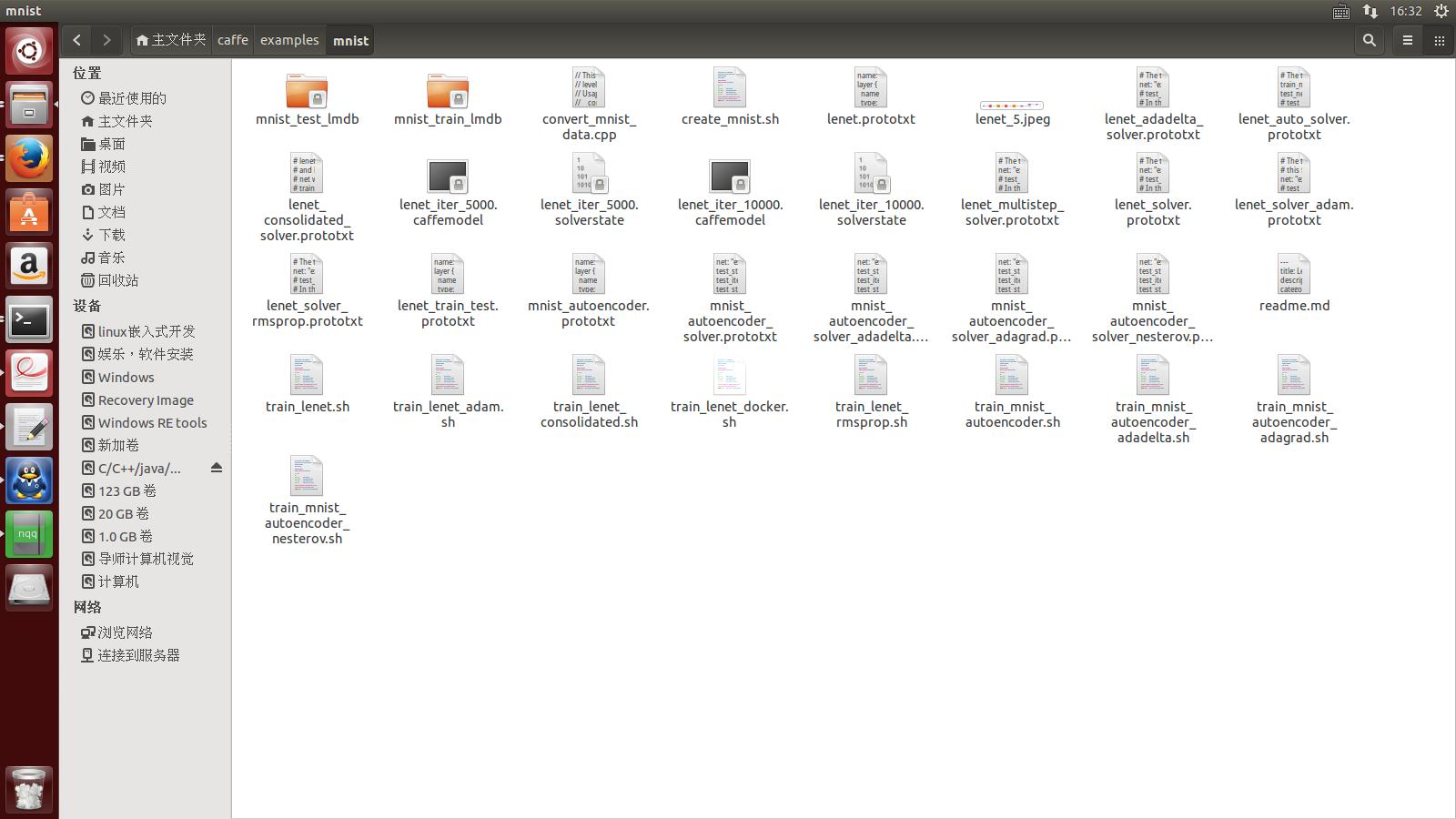
mnist_test_lmdb,mnist_train_lmdb这两个文件夹的大小如下所示:
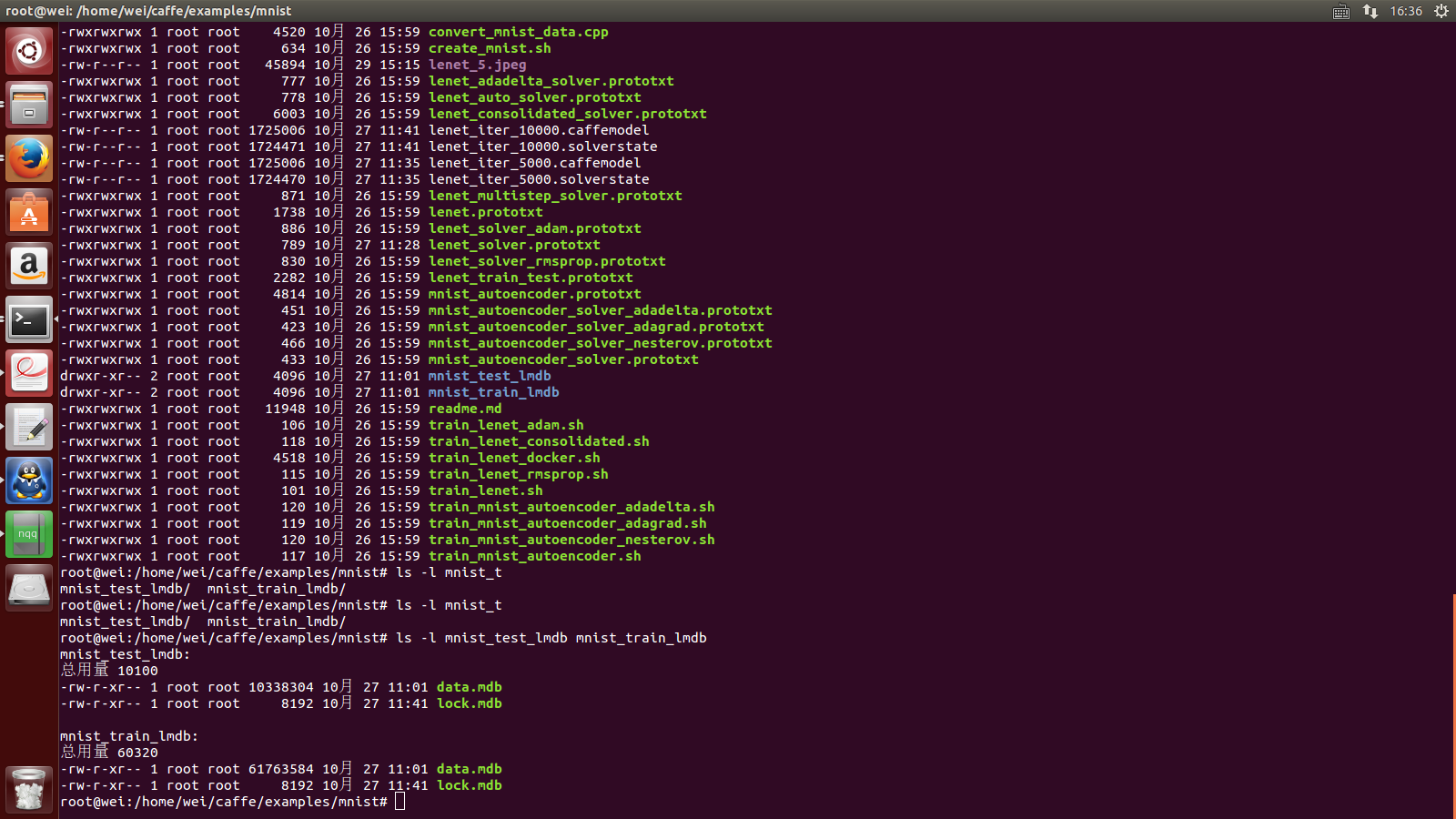
[3]如果你的电脑没有GPU的话,修改lenet_solver的配置文件
/********************************************************************************
*注意:
* 此块需要说明的是:
* 如果有GPU,怎不需要修改配置文件;如果没有GPU则需要修改lenet_solver.prototxt
********************************************************************************/
1---sudo vim ./examples/mnist/lenet_solver.prototxt
2---将这个文件的最后一行:
solver_mode:GPU------->solver_mode:CPU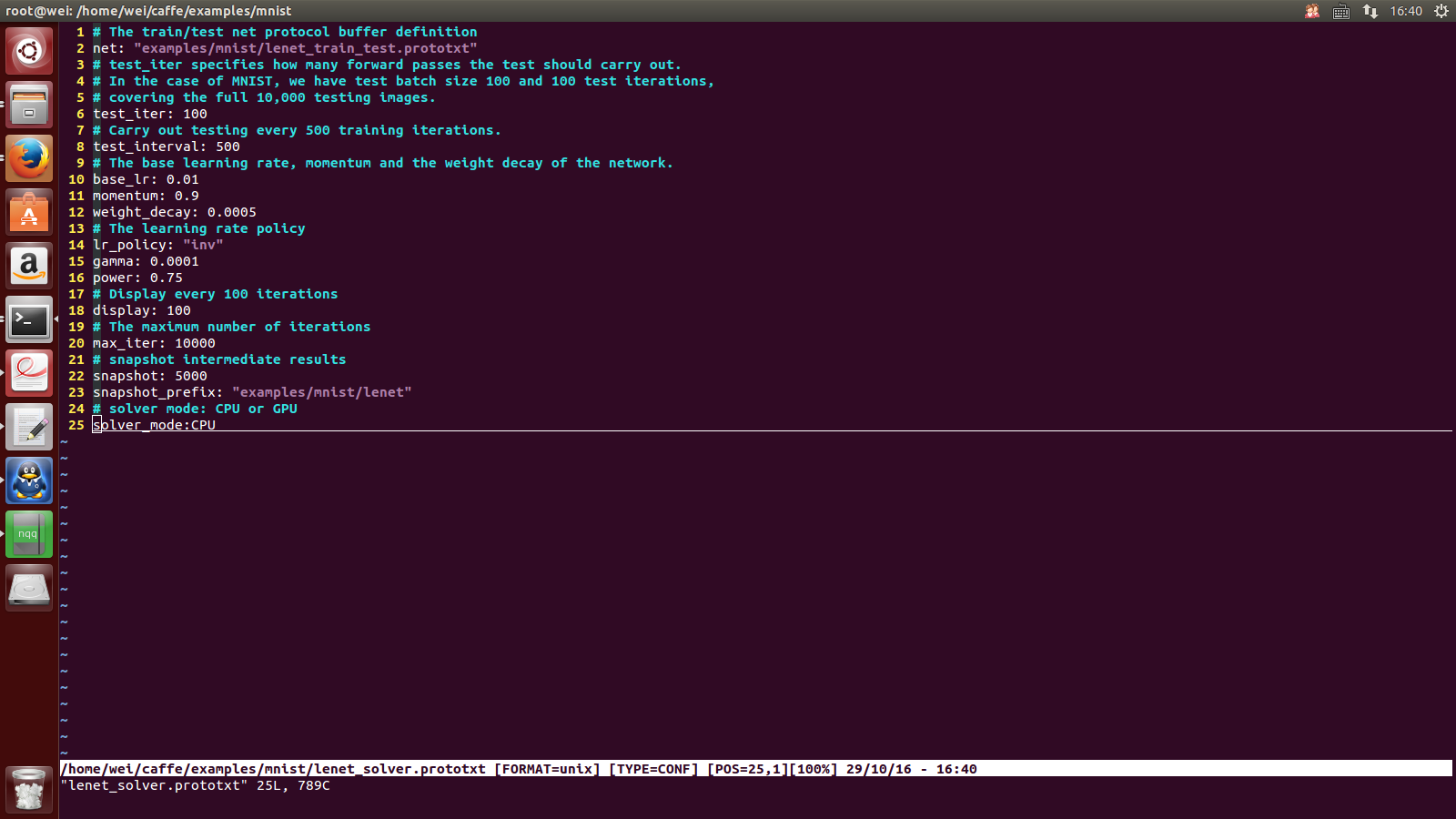
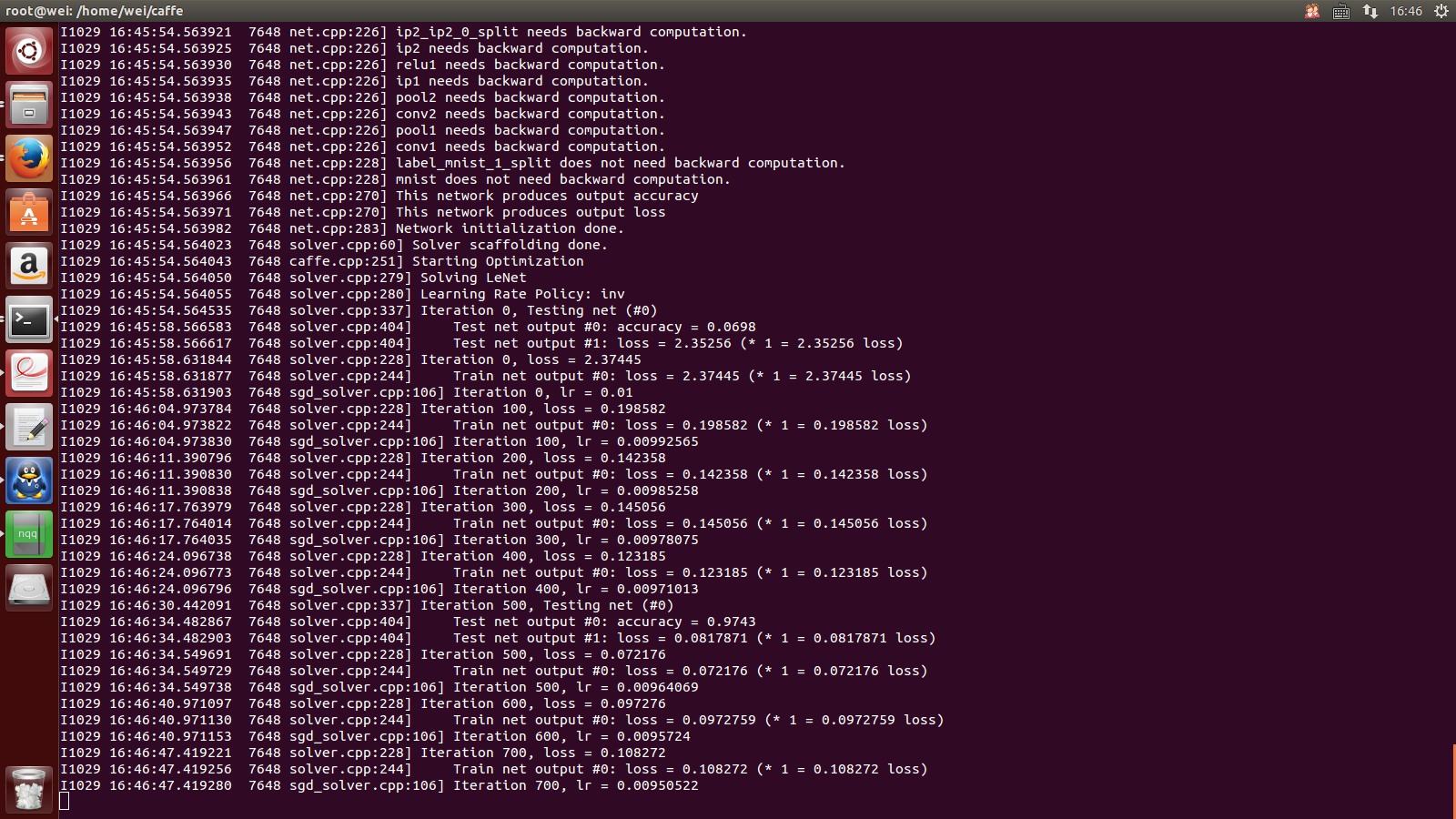
[4]训练网络模型:
1--一切准备好之后,就可以训练这个网络模型了
//[注意]:
// 1---运行下面命令的时候,一定要在caffe的根目录下,不然会出现报错情况
// 2---训练的时候,主要有三个参数输出需要注意:
1---Iteration:迭代次数,这个网络默认的设置是迭代10000次,每迭代100次输出
一次
2---lr----learing rate----网络学习率
3---loss-------损失
// 3---后面,最好结合caffe的可视化,然后就会深刻理解这些参数后面的意义
2--sudo time sh ./examples/mnist/train_lenet.sh
3---成功运行的话,没有GPU的电脑,训练时间大搞12分钟左右;
GPU的话,大概就3分钟左右
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









