







神经网络架构演进(经典论文)-Alexnet
这一篇是 Alexnet : Imagenet classification with deep convolutional neural networks 。
1 Introduction
当前目标检测主要采用机器学习的方法。为了改善性能,我们可以收集更多的数据,学习更强大的模型,使用更好的技术防止过拟合。目前有标记的图片数据库还比较小,简单的识别任务足够应付,尤其是我们还可以采用 保留标签图片变换的方法人工扩增这些数据。 例如: MNIST 数字识别率可以媲美人类。 但是,现实中的物体是复杂多样的,这就需要更大的已标记数据集。人们早就意识到训练数据太小是个严峻的问题,直到最近才得以收集到百万级别的标记图片数据,这些大数据集包括 LabelMe , ImageNet 等。
从百万级的图片数据中学习数千个物体,我们需要一个具备强大学习能力的模型。但是,对于大量物体识别的复杂任务,ImageNet这样的大数据集依然不够用,因此我们的模型也需要具备一些先验知识来补偿那些不知道的数据。卷积神经网络(CNN)就是一类满足要求的模型,它可以通过改变深度和宽度调整学习能力,它也会做出 很强但是近乎正确的假设(先验知识 例如:统计稳定性,局部像素相关性) 。 相比于 同样大小的标准前馈神经网络( standard feedforward neural networks ) 卷积神经网络有更少的神经元连接和参数,因此它可以更快的训练(学习)但是性能上只有轻微的降低。 不过仅有自身的良好特性还是不够的,还得加上GPU(高度优化的2D卷积实现)来加快训练CNN网络 , 大数据集(例如 ImageNet)的解决过拟合(外因)。
2. 数据
ImageNet:固定大小256x256。先把最小边缩放为256然后从图像中间扣取256x256图片。
3. 结构
3.1 ReLU Nonlinearity
激活函数一般采用tanh 或者 sigma 但是它们会出现饱和现象(函数图像的两边梯度变得很小,不利于反向传播梯度下降法学习)。ReLU不会出现饱和现象,它在大于0时的梯度是恒定的(只要大于0就可以学习)。
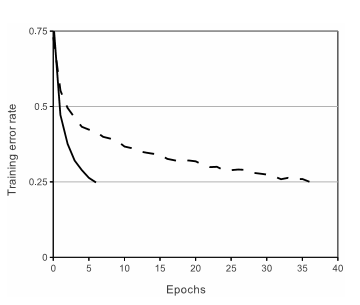
图:实线表示ReLUs 很快就收敛到0.25,虚线代表 tanh 很难收敛
3.2 Training on Multiple GPUs
一个 GTX 580 GPU 只有 3GB内存, 这限制了可训练神经网络的最大容量。所以作者把网络放在两个GPU中训练。当前的GPU很适合跨GP并行,它们可以互相直接读写不必经过主机内存。作者采取的并行化方式是 每个GPU放一半的核,另外还有一个小技巧:GPU只在特定层之间通信。例如 第三层的核以全部第二层的的特征图作为输入,第四层的核仅以第三层中同一GPU的特征图作为输入。选择这种链接方式不利于交叉验证,但是可以精确的调整通信的数量直到达到可接受的计算量。

3.3 Local Response Normalization
ReLU 不需要输入归一化解决饱和问题。只要ReLU的输入大于0就可以学习。但是 局部正则模式( local normalization scheme )有利于增加泛化能力。 表示 首先应用第i个核 在位置(x,y) 然后运用ReLU非线性化 再 响应归一化 的神经元输出,
表示 首先应用第i个核 在位置(x,y) 然后运用ReLU非线性化 再 响应归一化 的神经元输出, 表示局部响应归一化。
表示局部响应归一化。

下面是 两种 局部响应归一化的示意图,上面公式对应的是下面左图。

局部归一的动机:在神经生物学有一个概念叫做 侧抑制(lateral inhibitio),指的是 被激活的神经元抑制相邻神经元。归一化(normalization)的目的是“抑制”,局部响应归一化就是借鉴 侧抑制 的思想来实现局部抑制,尤其当我们使用ReLU 的时候这种“侧抑制”很管用。因为ReLU的响应结果是无界的(可以非常大)所以需要归一化。
参考: What Is Local Response Normalization In Convolutional Neural Networks In neurobiology, there is a concept called “lateral inhibition”. Now what does that mean? This refers to the capacity of an excited neuron to subdue its neighbors. We basically want a significant peak so that we have a form of local maxima. This tends to create a contrast in that area, hence increasing the sensory perception. Increasing the sensory perception is a good thing! We want to have the same thing in our CNNs.
3.4 Overlapping Pooling
相比于正常池化(步长s=2,窗口z=2) 重叠池化(步长s=2,窗口z=3) 可以减少top-1, top-5分别为0.4% 和0.3%。重叠池化可以比避免过拟合。
4 Reducing Overfitting
4.1 Data Augmentation
两种方式人工扩增数据。第一种是 抠图(从256x256抠出224x224)加上水平反转。第二种是 改变RGB颜色通道强度。 有效增加数据量,减少过拟合现象。
4.2 Dropout
组合多个模型的预测结果是一种非常有效的减少过拟合方法,但是代价太高。 而dropout是一种有效的组合模型的方法,只需要两倍的训练时间即可实现模型组合(类似取平均)的效果。
Dropout解决过拟合问题 - 晓雷机器学习笔记 - 知乎专栏
5. 结构


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









