










official documentation:
multiprocessing — Process-based parallelism — Python 3.10.4 documentation
breakdown of the API:
Python multiprocessing - process-based parallelism in Python
Barebone Example:
#!/usr/bin/python from multiprocessing import Process import time def fun(): print('starting fun') time.sleep(2) print('finishing fun') def main(): p = Process(target=fun) p.start() p.join() if __name__ == '__main__': print('starting main') main() print('finishing main')
Multiprocessing vs. Threading in Python: What you need to know.
What Is Threading? Why Might You Want It?
By nature, Python is a linear language, but the threading module comes in handy when you want a little more processing power. While threading in Python cannot be used for parallel CPU computation, it's perfect for I/O operations such as web scraping because the processor is sitting idle waiting for data.
Threading is game-changing because many scripts related to network/data I/O spend the majority of their time waiting for data from a remote source. Because downloads might not be linked (i.e., scraping separate websites), the processor can download from different data sources in parallel and combine the result at the end. For CPU intensive processes, there is little benefit to using the threading module.
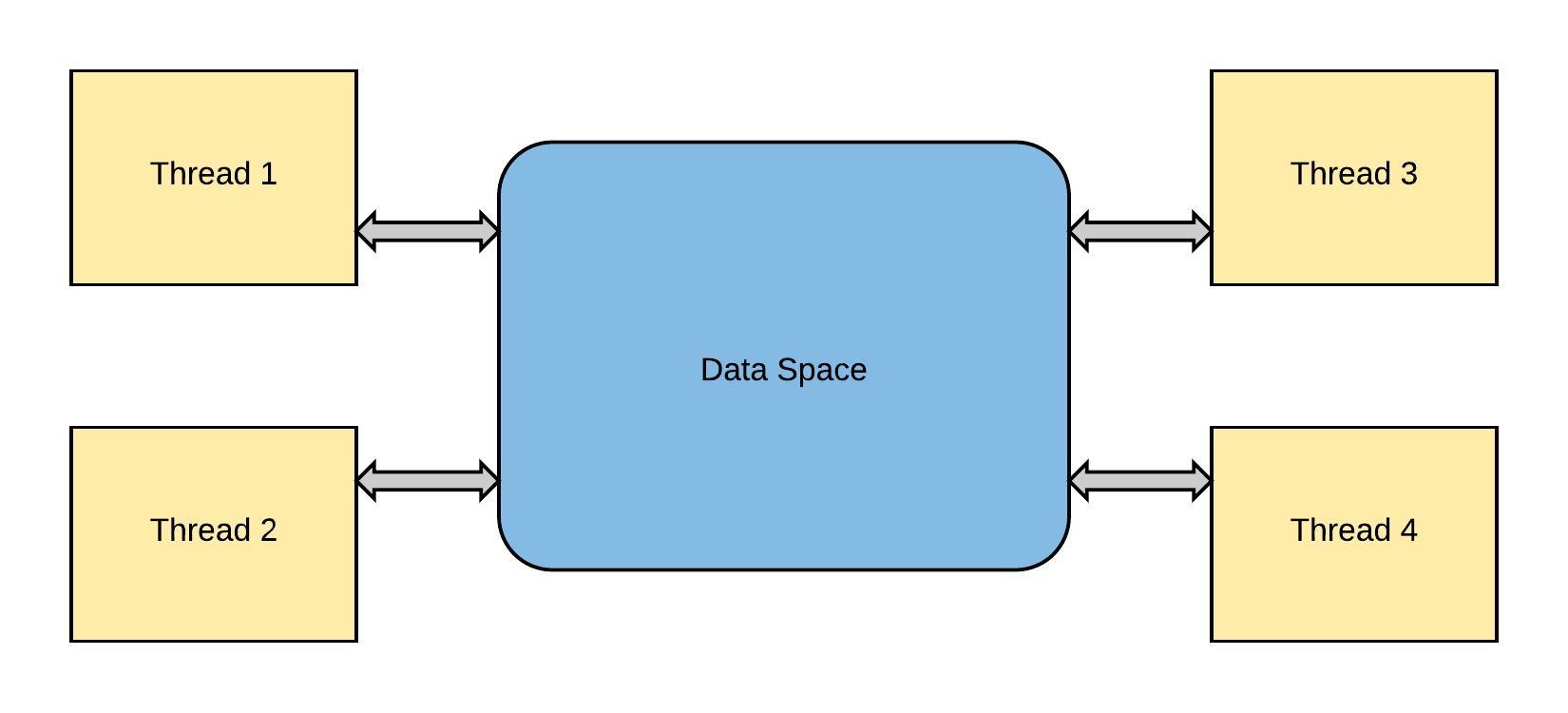
What Is Multiprocessing? How Is It Different Than Threading?
Without multiprocessing, Python programs have trouble maxing out your system's specs because of the
GIL(Global Interpreter Lock). Python wasn't designed considering that personal computers might have more than one core (shows you how old the language is), so the GIL is necessary because Python is not thread-safe and there is a globally enforced lock when accessing a Python object. Though not perfect, it's a pretty effective mechanism for memory management. What can we do?Multiprocessing allows you to create programs that can run concurrently (bypassing the GIL) and use the entirety of your CPU core. Though it is fundamentally different from the threading library, the syntax is quite similar. The multiprocessing library gives each process its own Python interpreter and each their own GIL.
Because of this, the usual problems associated with threading (such as data corruption and deadlocks) are no longer an issue. Since the processes don't share memory, they can't modify the same memory concurrently.
Keynotes
Shared variable in python's multiprocessing - Stack Overflow
==> for a mutable object to be updated by all processes, it must be declared as a shared object by Value(), Array(), or their respective Manager. variant nad dict(), list().
When you use Value you get a ctypes object in shared memory that by default is synchronized using RLock. When you use Manager you get a SynManager object that controls a server process which allows object values to be manipulated by other processes. You can create multiple proxies using the same manager; there is no need to create a new manager in your loop:
manager = Manager() for i in range(5): new_value = manager.Value('i', 0)The
Managercan be shared across computers, whileValueis limited to one computer.Valuewill be faster (run the below code to see), so I think you should use that unless you need to support arbitrary objects or access them over a network.import time from multiprocessing import Process, Manager, Value def foo(data, name=''): print(type(data), data.value, name) data.value += 1 if __name__ == "__main__": manager = Manager() x = manager.Value('i', 0) y = Value('i', 0) for i in range(5): Process(target=foo, args=(x, 'x')).start() Process(target=foo, args=(y, 'y')).start() print('Before waiting: ') print('x = {0}'.format(x.value)) print('y = {0}'.format(y.value)) time.sleep(5.0) print('After waiting: ') print('x = {0}'.format(x.value)) print('y = {0}'.format(y.value))To summarize:
- Use
Managerto create multiple shared objects, including dicts and lists. UseManagerto share data across computers on a network.- Use
ValueorArraywhen it is not necessary to share information across a network and the types inctypesare sufficient for your needs.Valueis faster thanManager.Warning
By the way, sharing data across processes/threads should be avoided if possible. The code above will probably run as expected, but increase the time it takes to execute
fooand things will get weird. Compare the above with:def foo(data, name=''): print type(data), data.value, name for j in range(1000): data.value += 1You'll need a
Lockto make this work correctly.I am not especially knowledgable about all of this, so maybe someone else will come along and offer more insight. I figured I would contribute an answer since the question was not getting attention. Hope that helps a little.
Multi-processing Communication by Queue
multithreading - How to use multiprocessing queue in Python? - Stack Overflow
Check Available Cores
from above, either share a counting variable, and lock/atomicize it properly or open up communication channels; but you can also rely on the os to handle the bookkeeping:
Python | os.sched_getaffinity() method - GeeksforGeeks
OS module in Python provides functions for interacting with the operating system. OS comes under Python’s standard utility modules. This module provides a portable way of using operating system dependent functionality.
os.sched_getaffinity()method in Python is used to get the set of CPUs on which the process with the specified process id is eligible to run.Note: This method is only available on some UNIX platforms.
Syntax: os.sched_getaffinity(pid)
Parameter:
pid: The process id of the process whose CPU affinity mask is required. Process’s CPU affinity mask determines the set of CPUs on which it is eligible to run.
A pid of 0 represents the calling process.Return Type: This method returns a set object which represents the CPUs, on which the process with the specified process id is eligible to run.
Tips and Caveats
Things I Wish They Told Me About Multiprocessing in Python
Tip #1
Tip #2
Always clean up after yourself
Tip #3
Always handle TERM and INT signals
Tip #4
Don’t Wait Forever
Tip # 5
Python’s
mutliprocessingmodule allows you to take advantage of the CPU power available on modern systems, but writing and maintaining robust multiprocessing apps requires avoiding certain patterns that can lead to unexpected difficulties, while also spending a fair amount of time and energy focusing on details that aren’t the primary focus of the application. For these reasons, deciding to use multiprocessing in an application is not something to take on lightly, but when you do, these tips will make your work go more smoothly, and will allow you to focus on your core problems.














 4808
4808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









