









 缓存失效是确保系统缓存只包含最新和相关数据的过程。文章详细介绍了各种缓存失效类型,如时间、事件、命令和组基失效,以及如何在实际应用中选择合适的策略。此外,还强调了设置适当的过期时间和考虑数据依赖的重要性,以维护系统的性能和数据一致性。
缓存失效是确保系统缓存只包含最新和相关数据的过程。文章详细介绍了各种缓存失效类型,如时间、事件、命令和组基失效,以及如何在实际应用中选择合适的策略。此外,还强调了设置适当的过期时间和考虑数据依赖的重要性,以维护系统的性能和数据一致性。
What is Cache Invalidation?
Cache invalidation is the process of invalidating cache by removing data from a system’s cache when that data is no longer valid or useful. In other words, you’re getting rid of old or outdated cached content that’s stored in the cache. This ensures that the cache only contains relevant and up-to-date information, which can improve cache consistency and prevent errors.
Cache invalidation is crucial for maintaining cache consistency. When a change is made to the original data, such as updating profile information, the corresponding cached files should be invalidated to ensure that the updated data is reflected. If the cache is not invalidated, there is a risk of displaying outdated information to users, which can cause confusion or even privacy issues. Cache invalidation involves synchronizing several data copies across multiple system layers, such as a web or application server and database, to ensure that the cached content remains consistent with the source of truth. This synchronization process can be complex and requires careful coordination across various system components.
>Learn how Redis is used for caching.
What is a Cache and What Does Caching Mean?
A cache is a hardware or software component that temporarily stores data used by apps, servers, and browsers.
In a website, the cache allows you to load specific resources from the server, such as fonts, images, or icons, without downloading them whenever you access the page. Instead of retrieving data from the actual storage or source of truth, the cache is accessed to retrieve the data upon request.
Since the main storage often cannot keep up with client demands, the cache is used as a provisional storage for frequently accessed data, making it faster to retrieve, reducing latency, and improving input/output (I/O).
When an application requires data, it first checks the cache to see if the data is available there. If it is present, the application accesses it directly from the cache. However, if it’s not present in the cache, the data is either obtained from the primary storage or generated by services. Once the data is obtained, it is stored in the cache to enable faster access in the future. This process of storing and retrieving data from the cache is known as caching. Consequently, when subsequent users access the same site or server, the cached data allows for quicker loading times, as the cache essentially “recalls” the data.
The more content requests the cache can fulfill, the higher the cache hit rate.
As an example, one popular caching strategy is the cache-aside pattern. In this pattern, the application first checks the cache for the requested data. If the data is not found in the cache (cache miss), the application fetches the data from the primary storage, stores it in the cache for future use, and then returns it to the user. Subsequent requests for the same data can be served from the cache, improving performance. To achieve cache-aside, a cache key is typically used to uniquely identify the data in the cache.
>Learn more in our Enterprise Caching: Strategies for Caching at Scale paper.
How Does Cache Invalidation Work?
Suppose you enter a website that stores web pages with a caching mechanism. If you change your profile information and the cache isn’t invalidated for the page, the old information will still be displayed. This can cause confusion or even privacy issues. Cache invalidation compares the data stored in the app’s cache to the data stored on the server. If the two differ, the cache is marked invalid and updated with the server’s most recent data.
Cache invalidation involves synchronizing several data copies across multiple system layers, such as a web or application server and database. This synchronization process can be complex and requires careful coordination across various system components. A change made to one layer may need to be propagated to several other layers, and the order in which updates occur can be critical to maintaining system consistency.
Once one input changes, there will be an invalid result in the cache. Additionally, the program may continue working, which makes it difficult to pinpoint where the problem is to fix the cache invalidation logic.
Think of it like a library where you can borrow books. Instead of going to the original bookstore each time you need a book, you can check if the library has a copy. If the book is available in the library, you can borrow it directly without going to the bookstore. The more books the library has that fulfill your requests, the higher the chances of finding the book you need without the need for additional trips to the bookstore. Similarly, the cache stores frequently accessed data, making it faster to retrieve and reducing the strain on the original storage or source.
When an application requires data, it first checks the cache to see if the data is available. If it is, the application can retrieve the data directly from the cache. However, if the data is not present in the cache, the application needs to fetch it from the primary storage or generate it through services. Once the data is obtained, it is stored in the cache, allowing for faster access in the future. This process of storing and retrieving data from the cache is known as caching. Consequently, subsequent users accessing the same site or server can benefit from quicker loading times, as the cache essentially “recalls” the data.
It’s worth noting that cache invalidation can be influenced by various factors, including the use of cookies. Cookies are small pieces of data stored on the user’s device and can be used to manage cache invalidation by associating specific cache entries with user-specific data. For example, if a user’s profile information is updated, a cookie can be used to invalidate the cache entries associated with that user.
Benefits of cache invalidation
As mentioned above, not invalidating cache can cause issues, such as inaccuracies and security problems. Here are some of the benefits of cache invalidation and the risk of not invalidating caches:
Better Performance
Cache invalidation removes old data from the cache, freeing up space and boosting the cache hit rate. This, in turn, retrieves frequently accessed data faster. On the other hand, if the cache isn’t invalidated, it may continue storing old data, resulting in decreased performance and efficiency.
Improved System Scalability
Clearing up unnecessary data reduces the load on the server or database. As a result, this can help improve the system’s reliability and scalability.
Lower Costs
Constantly needing to fetch data from the source of truth requires significant system resources, time, or exclusive access to a large amount of data. Cache invalidation reduces the need for such resource-intensive tasks. This can help save server resources and reduce the overall system cost.
Improved Security
When sensitive data is left in the cache and not invalidated, it may become exposed to unauthorized access and data breaches. Cache invalidation reduces this risk and other security vulnerabilities by ensuring that sensitive data doesn’t remain in the cache longer than needed.
Enhanced User Experience
Users almost always crave a faster experience. According to research by Google, a page load time of 10 seconds on mobile can increase the bounce rate by 123%.
In addition, serving users with different versions of the same data requested can lead to privacy issues and an inconsistent experience. As a result, properly invalidating the cache can minimize latency and provide users with the newest data, improving user experience.
For Compliance
Many applications, software, and websites are subject to regulatory requirements. These government-imposed compliance regulations differ depending on the software or location. Failure to invalidate cached data may result in non-compliance.
By storing only authorized and correct data in the cache, invalidation can help you comply with government regulations CCPA, GDPR, and HIPAA.
Types of cache invalidation
There are several types of cache invalidation techniques. Implementation of each type will depend on the specific requirements of the application. Before we go on, let’s explain what a dependency ID is, as we’ll mention it often in the following paragraphs.
A dependency ID is a label that identifies which cache entries to invalidate. The same label can be attached to one or more cache entries, creating a group used in an invalidation rule to invalidate an entire group of entries.
Now, let’s look at the most common types of cache invalidation:
Time-based invalidation
Time-based invalidation is one of the simplest types of cache invalidation, but it also has drawbacks. It invalidates data based on a predetermined time interval. Although there are different methods of accomplishing time-based invalidation, it is often done by adding a <timeout> value within the cache entry in cache configuration files like the cache-spec.xml. The value represents the amount of time in seconds that the entry is kept. However, the timeout period can be customized based on the application’s specific needs and the data it displays. A cache can be invalidated hourly to ensure the data in use is not outdated.
Examples of scenarios where time-based invalidation may be used include news sites that display the latest news hourly or a weather forecasting application that updates its forecast hourly. Other scenarios include stock trading applications to update stock prices every few minutes and a travel planning application that displays changes in flight availability and prices every few hours.
Event-based Invalidation
Event-based cache invalidation happens when the cache is invalidated when a specific event is triggered in the system. This type of invalidation is useful when the cached data is associated with a specific event or state change and must be updated properly. For example, an event-based invalidation may occur when a blog post is updated. The previous cache data must be invalidated to ensure users see the updated information on the post.
Command-based Invalidation
Command-based cache invalidation happens when a user triggers a specific defined command or action, resulting in an invalidation ID. A dependency ID is typically generated and associated with a cached object. So, when a command with an invalidation ID is executed, any objects in the cache with matching dependency and invalidation IDs are invalidated. An example is when a user deletes a file from storage. The cache for that file must be invalidated to ensure that the user does not see the file listed again.
Group-based Invalidation
Group-based invalidation happens when the cache is invalidated based on a group or category. This is particularly useful when the cached data is associated with a larger group of cache entries, so invalidating each entry separately is inefficient. Simply, group-based invalidations are necessary when a larger group of data must be invalidated at once. We’ll use the same news website example as before. But this time, if a section of the website, such as politics, is being updated, all section’s articles should be invalidated in the cache. This ensures users see the latest news under politics. For eCommerce sites, group-based invalidation can be triggered when a product category is updated. All the above types of cache invalidations can be used together depending on the specific needs. This can help create an effective and efficient caching strategy.
Strategies for cache invalidation
Many strategies can be used to ensure that cache invalidation is done effectively. Below are some of these strategies:
Least recently used (LRU)
When the cache is full, the LRU algorithm defines the policy for invaliding elements from the cache to create space for new elements. This means it discards the least recently used items first. LRU assumes these least recently used items are less likely to be needed in the future, so it clears them out first. For example, when a computer’s RAM is full, the OS may invalidate the least recently used memory pages first to make room for new data.
==> as computer programs are sequential execution of instructions, temporal ordering is natural.
Pseudo-LRU
https://en.wikipedia.org/wiki/Pseudo-LRU
Pseudo-LRU or PLRU is a family of cache algorithms which improve on the performance of the Least Recently Used (LRU) algorithm by replacing values using approximate measures of age rather than maintaining the exact age of every value in the cache.
PLRU usually refers to two cache replacement algorithms: tree-PLRU and bit-PLRU.
Bit-PLRU
Bit-PLRU stores one status bit for each cache line. These bits are called MRU-bits. Every access to a line sets its MRU-bit to 1, indicating that the line was recently used. Whenever the last remaining 0 bit of a set's status bits is set to 1, all other bits are reset to 0. At cache misses, the leftmost line whose MRU-bit is 0 is replaced.[1]
==> obviously a very simple alg. in concepts, while scales linearly with number of cachelines; it will be compared later in an example with Tree-PLRU
Tree-PLRU
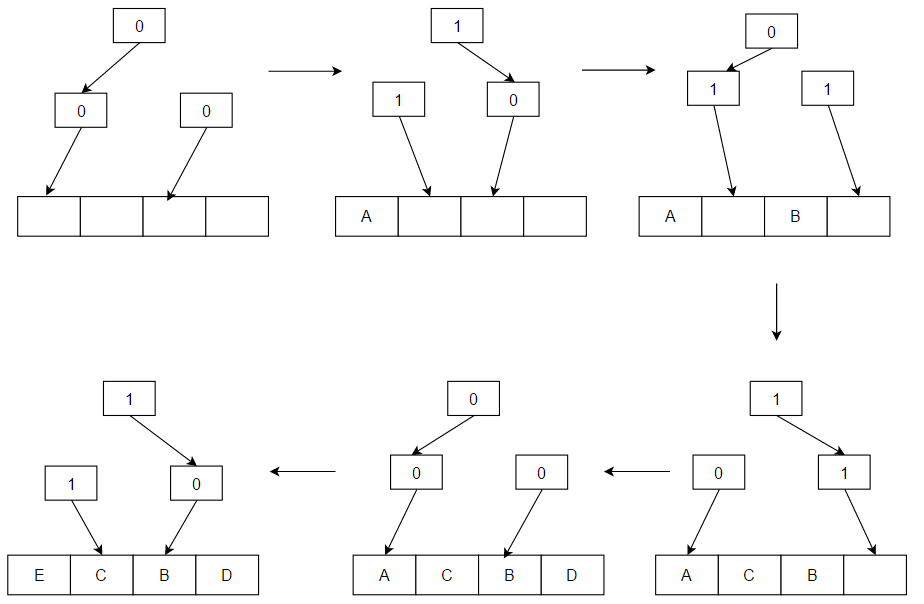
The algorithm works as follows: consider a binary search tree for the items in question. Each node of the tree has a one-bit flag denoting "go left to insert a pseudo-LRU element" or "go right to insert a pseudo-LRU element". To find a pseudo-LRU element, traverse the tree according to the values of the flags. To update the tree with an access to an item N, traverse the tree to find N and, during the traversal, set the node flags to denote the direction that is opposite to the direction taken.
This algorithm can be sub-optimal (==> not sub-optimal, but not equivalent to LRU) since it is an approximation. For example, in the above diagram with A, C, B, D cache lines, if the access pattern was: C, B, D, A, on an eviction, B would chosen instead of C. This is because both A and C are in the same half and accessing A directs the algorithm to the other half that does not contain cache line C.
Tree-PLRU vs. LRU
as noted above, Tree-PLRU only approximates LRU; the benefit for approximation is easier implementation, smaller overhead and lower hardware resource cost.
Consider the following example of a 4-way set associative cache:
https://people.computing.clemson.edu/~mark/464/p_lru.txt
we need 3 bits in a T-PLRU scheme for the 4 cachelines:
each bit represents one branch point in a binary decision tree; let 1 represent that the left side has been referenced more recently than the right side, and 0 vice-versathen
(the first "if no", is generally referred to as "under Invalid First", i.e. the entire scheme is called T-PLRU under Invalid First)
while
note that there is a 6-bit encoding for true LRU for four-way set associative bit 0: bank[1] more recently used than bank[0] bit 1: bank[2] more recently used than bank[0] bit 2: bank[2] more recently used than bank[1] bit 3: bank[3] more recently used than bank[0] bit 4: bank[3] more recently used than bank[1] bit 5: bank[3] more recently used than bank[2] this results in 24 valid bit patterns within the 64 possible bit patterns (4! possible valid traces for bank references) e.g., a trace of 0 1 2 3, where 0 is LRU and 3 is MRU, is encoded as 111111Tree-PLRU vs. Bit-PLRU
obvious, with the same setup, we need 4 bits for the BPLRU scheme, while the both costing on average 1 bit flip per state update;
as for determination of cacheline, BPLRU pick the leftmost 0 out of 4 bits, this is more complex than a simple 3 bit pattern comparison required by TPLRU.

Least frequently used (LFU)
(LFU) is a caching algorithm that removes the least frequently used cache block when the cache is full. That is, the cache entry that has been accessed the least number of times is evicted. This strategy implies that items that aren’t accessed regularly have the lowest chance of being used in the future. So, these cache entries are the first to be evicted. Search engines use this caching strategy to invalidate query caches. On the one hand, the query stores search results of frequently executed queries. However, the least frequently used queries are invalidated first.
Random replacement
As the name suggests, the random replacement algorithm is an invalidation strategy that picks any cache entry randomly and replaces it. This algorithm requires no data structure and doesn’t monitor the history of the data contents. The random replacement model assumes every cached data is equally likely to be used later. So, it doesn’t matter which one is cleared out and replaced. Load balancers invalidate their session caches using random replacement cache invalidation. The session cache saves a user’s session data, and when the cache overflows, the LRU or LFU sessions are invalidated randomly.
Random replacement may also occur when a computer system’s physical memory is full. The OS may choose to replacer some memory pages to the hard disk. And if a memory page has to be swapped back to physical memory, but there’s no space, the OS may invalidate a memory page at random.
First in, first out (FIFO)
First in, First Out is a strategy that is applied in many industries and businesses besides caching. The logic here is that the oldest data or inventory items should be the first to be cleared out. In a cache invalidation context, FIFO is when the first cache entry is invalidated first. This is because they are more likely to have been in the cache for the longest time, meaning they’re less likely to be used in the future. For example, a printer uses FIFO to choose which print jobs it performs first. Users who send their data in are more likely to be at the front of the print queues.
Additionally, database systems use transaction logs to track database changes. When the transaction log is full, the oldest log entries are invalidated first. Ultimately, your cache invalidation strategy will depend largely on the system requirements, such as cache size, frequency of data access, and data types. In some cases, different cache invalidation strategies may be used. This can optimize cache performance and enhance system efficiency.
Cache invalidation best practices
Although cache invalidation is an excellent way to save server resources, improve speed, and reduce latency, it’s important to do it right.
Avoiding Over-caching
Caching is useful for improving system performance and speed. However, over-caching can harm performance because it may consume valuable memory resources and increase server load. This means the server is forced to continuously update and manage the cache, which can lead to regular downtimes. If your website or online platform accepts user-generated content (UGC), caching content for longer periods may lead to inconsistencies that may harm your website’s reputation. As such, you must balance caching frequently accessed data and allowing less regularly used data to be invalidated.
Setting Appropriate Expiration Times
Setting the right cache expiration time is vital to website optimization. It helps reduce the load on the server and also improves user experience. You must consider the content type on a page when setting the cache expiration time.
For instance, if the page contains dynamic content like eCommerce products or UGC, which are updated regularly, the cache expiration time should be shorter. On the other hand, if the page displays static content that’s not frequently updated, the cache expiration time can be extended. Google recommends a minimum cache time of up to one year for static assets like CSS files, images, or JavaScript files. For frequently updated content like stock prices, news articles, weather forecasts, and social media feeds, the cache expiration time should be between a few minutes to an hour. This ensures users receive the latest information.
Consider Data Dependencies
Cached data sometimes depends on other data or resources, meaning a change to dependent data may require data in the cache to be invalidated. It’s essential to ensure that cached data is consistent with the source of truth. If the dependent data is changed, the cached data may become stale, resulting in outdated data being displayed to the user.

















 1276
1276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









