






关于编码的一些概念,自己开始模模糊糊的知道些,却不是十分明白,这里看了些资料总结了一下,若有不正确的地方,不吝赐教。
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
*字符集
首先要明白字符集的概念,字符集就是一类字符,图形,标点符号的集合。简单理解就是所有英文用的字母,字符,标点符号时一个字符集。同理,中文有中文的字符集,日语有日语的字符集等等。
*编码&解码
是一套法则,使字符集与数字系统之间建立对应关系,它是信息处理的一项基本技术。对于这里的编码来说,简单可理解为给一个字符集中的所有元素一个唯一的ID(二进制存储)号。相反通过这个ID号找到某个元素的过程就是解码。这里需要注意一下几点:
1.一个字符集下可能有多个编码规则,如对于大陆简体中文字符集来说有GB2312,GBK等编码格式。
2.一个编码格式只属于一个字符集,但可能在一定的范围内一个编码会兼容另一个编码,也就是两个字符集某些字符的ID号两种编码都一样,如很多编码格式都是兼容ASCII编码。
3.字符串的编码和解码一定要一致,否则很有可能会引起乱码的情况。
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
下面看一些常用的字符集和编码。
*ASCII字符集&编码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码):是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,使用7位(bits)表示一个字符,共128字符。简单理解位ASCII编码就是英语编码,所以除了英语以外的字符它是无法编码解码的,这样做的后果就是乱码。
*ANSI字符集&编码
随着计算机发展,ASCII编码的不足很快被发现,很多国家的语言都无法表示,所以对ASCII编码做了扩展,刚开始的时候使用8位(bits)表示一个字符,共256字符,这样像法语,西班牙语等语言都能正常表示了,但像中文,日语,朝鲜语等8位肯定是不够的,远不止256个字符。所以不同的国家和地区制定了不同ANSI的标准,这才是我们今天所说的ANSI字符集编码的概念。所以ANSI不是具体的某一个语言的字符集和编码的概念,它是所有不同国家语言字符集和编码的一个集合。针对具体的一个字符串,如果说它是ANSI编码,那到底是用GBK,BIG-5,ASCII或其他语言的哪一个编码格式进行编解码呢?在windows上这个默认和系统设置有关,如图:
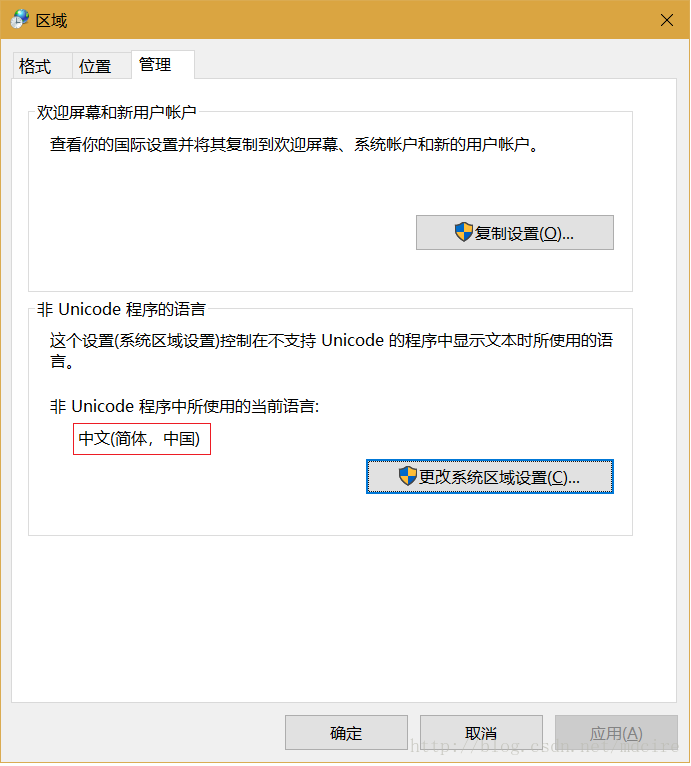
如果在控制面板这里是简体中国就是GB2312编码,如果是繁体台湾就是BIG-5编码。所以说ANSI编码,一定要意识到它会最终对应到某一个语言的编解码,ANSI字符集编码是随着设置而动态变化的。
这里可以看到ANSI字符集编码的不足了,它很有可能引起乱码,每个国家的语言有一种编解码,而很多也都是重复的。比如像中文,有简体中文,繁体中文之分,简体中文有大陆的简体中文和新加坡的简体中文。繁体中文有台湾,香港,澳门的繁体中文。光一个中文字符集都分了这么多,每个字符集下面又有不同的编码,稍有不慎,就可能会乱码,这样很麻烦,所以就有了我们常说的Unicode字符集。
*UCS,Unicode字符集
UCS(Universal Character Set,通用字符集):由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。
Unicode:由统一码联盟制定的基于UCS的标准发展而来。现在与UCS基本兼容。(这个统一码联盟就是众多软件厂商组成的一个联盟,如微软,IBM,苹果等)
Unicode和UCS就是只使用一个字符集来表示世界上所有语言及其符号等。这样可去除重复性操作简单,优势很明显。如果不做深入研究简单可理解Unicode和UCS是同一个东西,但其实它们是有些差异的,只不过平常我们碰不到罢了。
UTF-8(8-bit Unicode Transformation Format):针对Unicode的可变长度字符编码,UTF-8使用一至四个字节为每个字符编码,也就是说可能对字符串中的每个字符,它会根据不同字符使用不同字节数进行编解码,UTF-8有自己的规则和算法。UTF-8在网络传输编码中很常见,因为它比较省空间。
UTF-16(UCS2) :使用定长两个字节表示Unicode字符集中的每个字符。简单理解UTF-16和UCS2一样,但其实有一定差别。
UTF-16对每个字符都是按2个字节进行编解码,所以它最多表示65535个字符,超过65535个字符可以表示吗?当然可以,它会对一定比特位做位运算来表示65535外的字符。
UTF-32(UCS4) :使用定长四个字节表示Unicode字符集中的每个字符。简单理解UTF-32和UCS4一样,但其实有一定差别。
注意:
1.我们有时候会说使用unicode编码,但其实这句话是不准确的,unicode只是字符集的概念,不是编码的概念。如果使用UTF-8编码再使用UTF-16解码,虽然他们都属于unicode编码,但最后出来的还是乱码,所以一定要指明具体的编解码格式。
2.UTF-16和UTF-32会有一个BOM(BYTE ORDER MARK)字节序的概念,因为使用2字节或4字节存储会有这个问题,如一个字符id为0xABCD,那它在内存中是0XABCD还是0XCDAB呢,所以要指名的字节序。Windows上使用0xfffe表示小端UTF-16,使用0xfeff表示大端UTF-16。默认使用小端的UTF-16。测试方法,新建一个txt,使用记事本打开另存为unicode,看看它的大小,虽然没有输入任何字符,但看它的属性,大小是2个字节,就是因为写入BOM,用winhex查看内容为FFFE。UTF-32类似。这里还有个问题UTF-8是否需要BOM呢,因为UTF-8是字节流,它可以不需要的,但Unicode标准没有说一定要有或没有,所以这里就有了问题。使用相同测试方法把刚才的txt另存为UTF-8格式。它的大小位3个字节,其内容为EFBBBF,这就是UTF-8的BOM。但是LINUX貌似UTF-8是没有BOM的,所以跨平台传输的时候可能要注意UTF-8的字节序的问题。
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
Windows上使用char所表示的字符串默认编码格式为ANSI。使用wchar_t所表示的字符串编码格式为UTF-16。下面是用VS2010对它们一个简单的测试,很明显,使用wchar_t编码的字符串更适合我们使用。所以在程序中使用wchar_t是避免乱码的最好的解决方法。否则就要使用WideCharToMultiByte和MultiByteToWideChar进行转换,如果ANSI的code page填的不正确的话结果很有可能是乱码。
| OS Lan:简体中文 | "中a" | |
| char(GB2312 ) | wchar_t(UTF-16) | |
| sizeof | 4 | 6 |
| strlen(wcslen) | 3 | 2 |















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









