







论文原文链接:
本博客根据博主对本论文的阅读和理解所写,重点关注个人理解方便,非逐句翻译,望周知。如需深入了解论文详情,请阅读原文。
作者:He Huang, Philip S. Yu (University of Illinois at Chicago) and Changhu Wang (ByteDance AI Lab);
发表位置:Arxiv 2018;
摘要:GAN在许多领域展现出强大能力,比如计算机视觉和NLP。在众多GAN的应用中,image synthesis是研究地非常深入的领域,充分展示了GAN在生成方面的潜力。本文对image synthesis方法进行分类,回顾text-to-image, image-to-image的各种模型,并且讨论图像生成中的一些evaluation metrics,以及image synthesis未来可能的研究方向。
关键词:深度学习,GAN,图像合成,计算机视觉;
一、引言:
“What I cannot create, I do not understand”, said the famous physicist Richard Feynman. 因此机器为了要理解它的输入数据,必定要(学习)能够create这些数据。因此需要生成模型来发现数据的本质并用一个分布来表示数据,这样的话,甚至还能从该分布中采集训练集中没有的数据。
相比于其他生成模型,GAN生成的image更好,因此GAN成了最流行的研究方向。对其进行的研究一般有两方面:理论方面,致力于减弱传统GAN公式的instability和mode collapse问题,或者从其他角度重新定义GAN,比如信息论、基于能量的模型等;应用方面,致力于探索更多GAN的应用场景。
文章[14](见论文参考文献)这篇综述介绍了生成模型的重要性,解释了GAN如何工作,将GAN和其他生成模型做对比,并且分析了GAN的目前工作。另一个篇综述[15]则回顾了GAN的许多结构和训练技巧,介绍了一些GAN的应用。(对GAN感兴趣的人可以去重点看看这两篇综述)。但是他们都是从通用角度介绍的GAN,没有深入到具体某一个GAN的应用中去。所以,本文专注于image synthesis应用,探索GAN在生成图像方面的能力。除了合成,在CV中,GAN在image in-painting,image captioning (图像描述),object detection (目标检测), semantic segmentation (语义分割)等任务中也有很强大的应用。
GAN在NLP中的发展也有很多,比如text modeling,dialogue generation (对话生成),question answering (问答),neural machine translation (机器翻译)等。但是将GAN应用于语言任务更困难,需要更多技术,因此有关这个方向的研究和探索也很吸引人。
本文的目标是对image synthesis中使用GAN的方法做一个overview,并且指出他们的优缺点。本文将最要的方法分为三类:直接方法,层次化方法,迭代方法。除了这些最常见的方法,还有一些其他方法本文也做了简要的提及。然后本文从image synthesis的两个重要任务方面来进行具体的分析:text-to-image synthesis, image-to-image translation。同时本文还讨论了GAN在特定的任务中为什么表现非常好的原因,以及在AI中GAN所扮演的角色。本文的目的是为想使用GAN解决他们的问题,以及想为GAN的发展进行研究的同学做一个简单的引导。
本文的组织如下:第二章简单回顾了GAN的重要概念和一些GAN变种及其训练问题;第三章介绍三种主流image synthesis方法和其他非主流的方法;第四章介绍text-to-image方法,和该方向未来可能有提升的地方;第五章介绍监督的和无监督的image-to-image方法,并且分析一些特定的应用;第六章回顾合成的图像的评价指标;第七章讨论判别器的角色问题;第八章进行总结。
二、GAN的概念
GAN通常分为两部分:生成器G和判别器D。生成器G是GAN的生成部分,其输入一个随机噪声z(该噪声通常来源于某一个分布 p_z ,比如正态分布等),输出一个生成结果G(z)。这个过程也可以看做是从一个分布 p_g 中进行某种方式的采样,得到了G(z),也就是 G(z) ~ p_g。生成器的目标(也可以说是GAN的目标)就是让它生成的结果尽可能真实(比如像现实生活中的图像)。如图1所示。给定训练数据 x 代表真实的数据,其来自于现实生活中(假定 x 服从真实数据分布 p_data),那么生成器G的目标就是让它生成的G(z)尽可能像 x,也就是说GAN的目标是用分布 p_g 拟合真实分布 p_data。
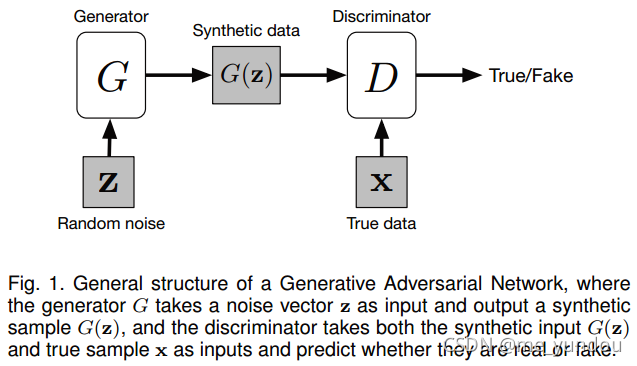
与此同时,判别器D输入一个数据 x 或者 G(z),判断其是真实数据(打高分)还是虚假数据(打低分,由生成器生成的synthetic数据)。判别器的目标就是尽可能分辨虚假数据。
其中,生成器和判别器各自的实现可以用任何神经网络,最初的作者使用了全连接网络,然后DCGAN提出使用CNN来实现并取得了更好的结果。
因此,GAN的训练目标就是:对生成器G而言,它希望自己生成的数据尽可能像真实数据,也就是D(G(z))的分数尽可能高;而对判别器D而言,它希望自己能尽可能分辨真假,也就是对D(x)打高分,对D(G(z))打低分。所以,GAN的总目标是一个最大最小的博弈游戏,公式如下:
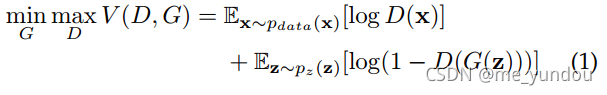
但是,原始的GAN存在一些问题。
2.1 conditional GAN (条件GAN)
原始的GAN是从随机噪声中生成数据,我们没有办法控制生成的东西。因此,条件GAN引入了一个条件输入 c ,与 z 拼接起来然后一起输入生成器。除了拼接之外,还可以有其他数据增强的方式作用于 c 和 z。利用 c,就可以一定程度上实现对生成数据的控制,比如 c 可以代表图像的类别、目标的属性、或者是文本向量(用来生成相应的图像)。
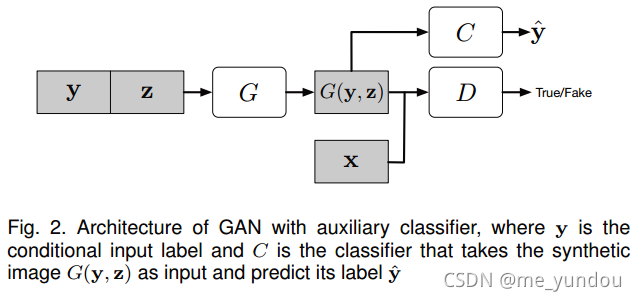
2.2 带有 Auxiliary Classifier (辅助分类器)的GAN
为了利用更多额外信息,以及进行半监督的学习,可以在GANde 判别器上加一个辅助分类器,如图2所示。比如用来判断图像的类别,目标的属性等。辅助分类器可以直接使用预训练好的模型,实验表明,这样的方法对GAN生成sharper图像以及缓解模型崩溃的问题很有帮助。使用辅助分类器对 text-to-image synthesis, image-to-image translation 等应用也有很大帮助。
2.3 带有 Encoder (编码器)的 GAN
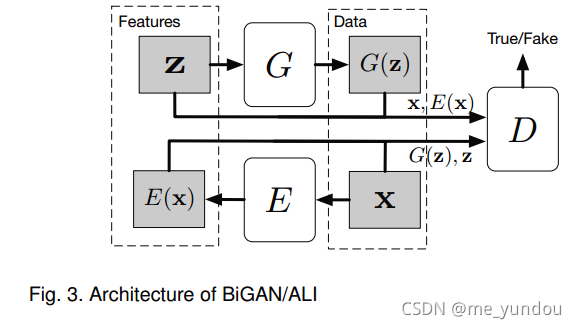
虽然GAN可以从随机噪声 z (假定 z 服从分布 p_z ,且将该分布看做一个隐式向量空间)生成数据G(z),去近似真实数据 x,但是GAN没办法反过来将真实数据 x 映射到 z 所在的隐式向量空间中去。为了实现这个映射,BiGAN和ALI在原始的GAN中增加了一个编码器E,如图3所示。E以真实数据 x 为输入,得到它在隐式向量空间( z 所在空间)中的编码E(x),实现将 x 映射到z所在隐式空间的目的。然后调整判别器,使它同时以隐式向量空间中数据 z (或者E(x)),以及合成数据 G(z) (或者真实数据 x),为输入,来进行真假性的判断。他们的目标公式如下:
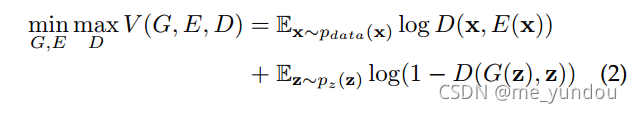
2.4 带有 VAE (变分自编码器)的 GAN
VAE-GAN可以联合VAE和GAN两种较好的生成模型的优点,其结构如图4所示。GAN生成的图像精度更高,但是mode太少(不够多样性?),而VAE生成的图像多样性好,但是很模糊。VAE部分通过施加一个正则分布的先验来正则化编码器E,VAE的loss定义为:
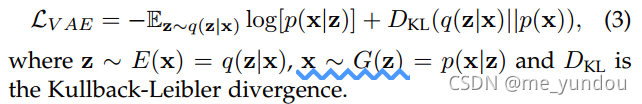
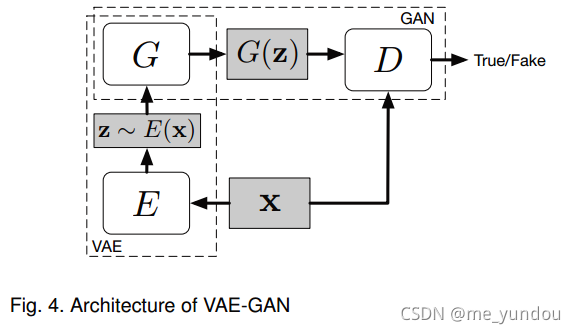
然后VAE的loss和GAN的loss联合,就是总的loss了。实验证明VAE-GAN相比单独的GAN或者VAE能生成更好的图像。
2.5 处理mode collapse (模式崩溃)
原始的GAN有训练不稳定、需要许多训练技巧才能训练出一个较好的结果、模式崩溃等问题。最原始的G只需要能骗过D就行,而不需要满足多样性等其他条件。比如手写数字生成,G只需要将某一个数字生成地非常好就可以一直骗过D,导致G停止训练,无法学到别的数字,这种称为inter-class模式崩溃。intra-class模式崩溃是数字有很多书写风格,对每种数字G只学一种风格就行。但是这样学出来的生成器显然不是我们想要的。
研究者们提出了很多办法解决mode collapse的问题。一个技巧是minibatch features,该方法在D判别真假样本的时候,将样本同时与一个minibatch的真实数据和生成数据都做对比,防止该次生成的样本和已有的生成样本太近似(通过测量样本间距离,使之大于某一个值)。这个方法很好,但是结果依赖于用来度量样本之间距离值的features选择。另一个技巧是在生成器G部分添加一个编码器E,如BiGAN,联合训练E和G的loss,可以对mode进行正则化。同时将重构的样本也作为D的输入,对D的训练也是一种正则化。还有一个技巧是WGAN使用Wasserstein 距离代替原始GAN的JS距离,来度量真实数据分布和学到的数据分布之前的相似性。该方法从理论上避免了mode collapse的问题,但是在训练过程中会花费比原始GAN更多的时间达到收敛状态。为了解决时间问题,WGAN-GP提出了梯度惩罚,WGAN-GP能够生成非常好的图像,且避免了mode collapse的问题,同时该训练方法还可以灵活运用到其他GAN模型中去。
如果还想知道更多关于GAN的训练技巧,可以看NIPS 2016的论文:How to train a GAN
三、使用GAN做image synthesis的常用方法
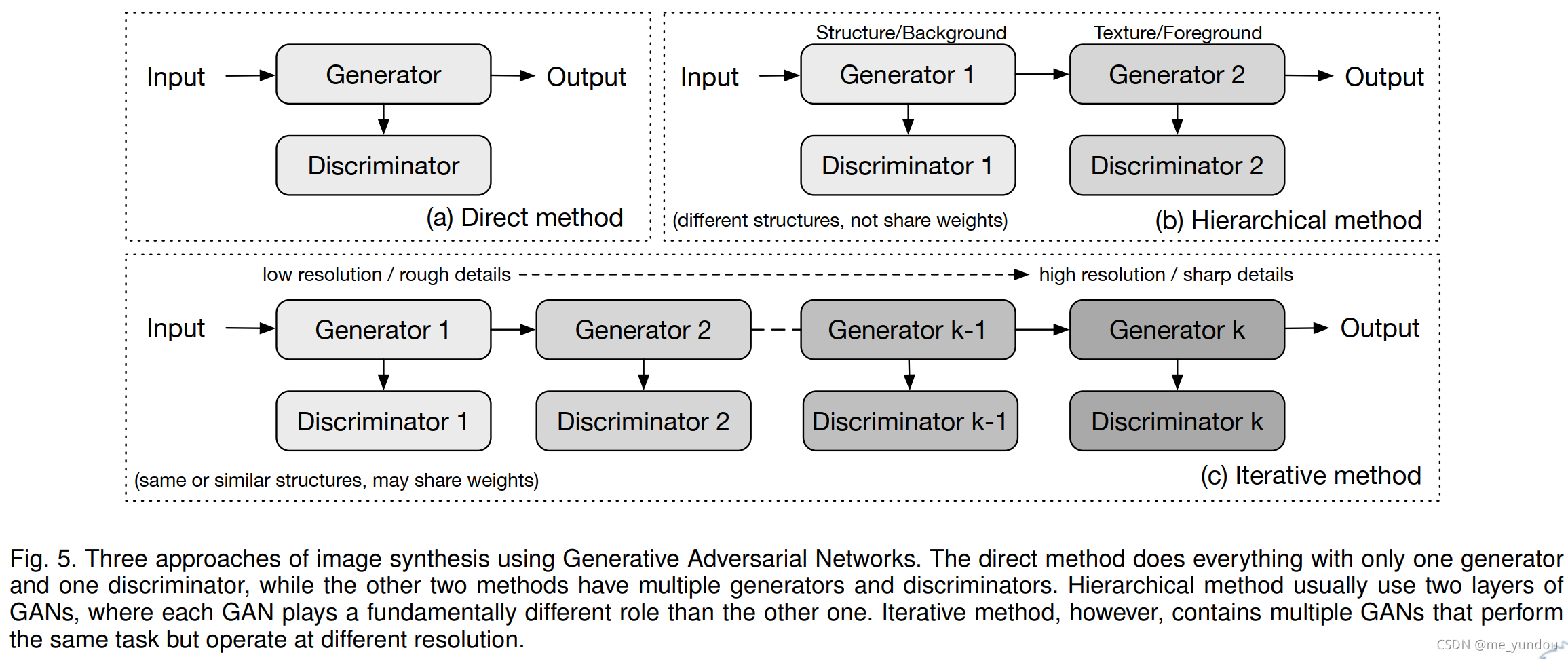
本章将生成图像的主要方法大致分为三种类别:direct methods (直接方法),iterative methods (迭代方法),hierarchical methods(层次化方法)。如图5所示。
3.1 直接方法
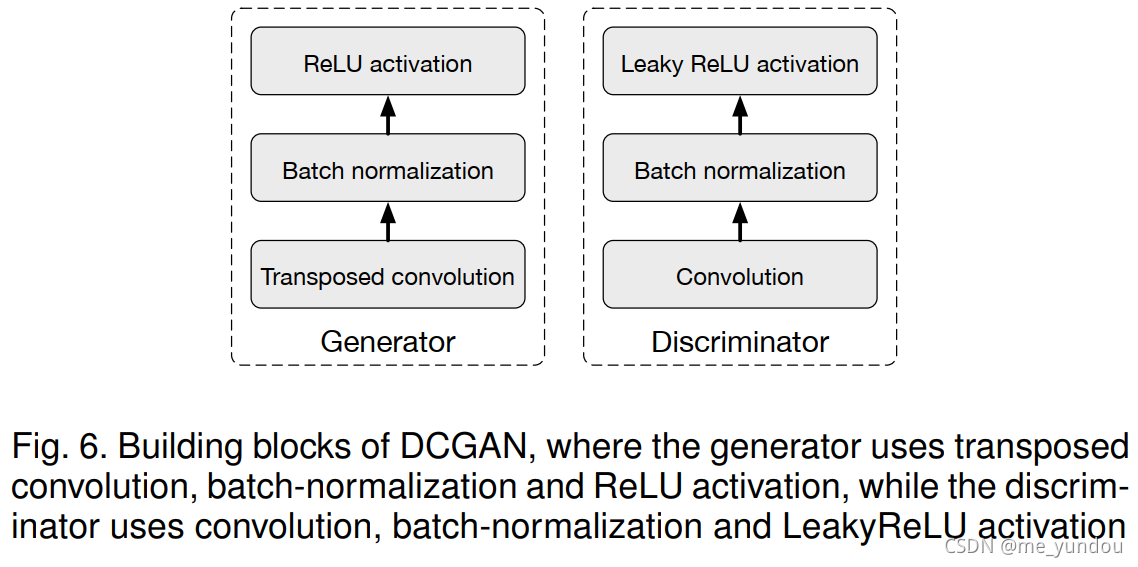
这类方法中GAN结构只有一个生成器G和一个判别器D,且他俩的实现方式都是straight-forward的,没有分支。早期GAN大多是直接方法,其中DCGAN是比较经典的方法,其结构如图6所示,GCGAN的block设计在后来的许多模型中也多有使用。
直接方法是好处是模型设计和实现都很straight-forward,且模型效果较好。
3.2 层次化方法
该方法一般有2个生成器和2个判别器,不同的生成器有不同的目的。该方法的思想是将图像的生成过程分为两个部分(或者不同层次,比如前景和背景,结构和风格等)。这两部分可以是并行或者顺序的关系。经典方法SS-GAN由两部分组成:Structure-GAN用来生成图像的surface normal maps (表面法线贴图);Style-GAN以前者的生成结果和随机噪声作为输入,生成最终的图像。Structure-GAN的结构使用DCGAN的结构,而Style-GAN则不同。Style-G先分别对随机噪声和表面法线贴图做卷积(或者转置卷积),然后将他们的输出拼接后输入后面的神经网络层。Style-D同时以表面法线贴图和它对应的图像作为输入。除此之外,SS-GAN认为一个好的合成图像应该能够重构它的表面法线贴图,所以使用了一个全连接网络将图像转换到其对应的表面法线贴图,然后使用pixel-loss让重构贴图尽可能接近真实的表面法线贴图。该方法的一大缺陷是它需要使用Kinect来获取图像的表面法线贴图的真实值,作为标签。
该类方法中的一个特例是LR-GAN,它有两个生成器和一个判别器,生成器分别用来生成图像的前景和背景。实验表明,该方法确实可以分别生成图像的前背景且得到sharper的图像。
3.3 迭代方法
该方法与层次化方法的主要区别在两点:该方法的多个G一般有相同或者近似的结构,从coarse到fine这样生成图像,后一个G接收前一个G的输出图像作为输入,然后输出更精细的图像。第二点,迭代方法中结构相同的G通常共享参数,而层次化方法不会共享。
LAPGAN是第一个迭代方法,使用拉普拉斯金字塔,用多个结构相同(只有输入输出的size不同)的G来逐渐精细化图像。每个G以前一个G输出的图和噪声作为输入。本方法比原始GAN好,体现出迭代方法能比直接方法产生更sharper的图像。
StackGAN有两个G,G1输入(z,c),输出较模糊的图像,显示目标的大致形状和模糊细节;G2输入(z,c)和G1的输出图像,得到更大更photo-realistic细节。
SGAN的一系列G都以前一个G的输出(lower level features)为输入,得到higher level features。每个G都有一个编码器E,判别器D,Q网络,来限制和改进其生成的features的质量。
GRAN所有的G都是一样结构且共享权重(类似传统RNN),当前G接受前一个G的输出作为输入。
3.4 其他方法
这里介绍了两个不属于上述分类的方法。
PPGN使用activate maximization(激活最大化)来生成图像,它基于对先验的采样,该先验是使用去噪自动编码器学习的。
ProgressiveGAN的目标是生成高分辨率的图像。它先用一个G和一个D生成4*4的图像,然后不断增加额外的层最终生成1024*1024的图像。该方法使得模型可以先学粗粒度的结构,然后再专注于细节,而不需要同时关注不同scale下的所有细节。
四、text-to-image synthesis
当我们在图像合成中使用GAN的时候就是想要能控制生成的图像的content。虽然目前的cGAN已经能够生成特定class的图像,但是从文本生成图像还是很难得。而如果能够成功从文本生成高质量图像,就说明计算机真的理解了文本和图像内容。毕竟CV的目标就是教会计算机去see和understand实际生活中的visual content。
GAN-INT-CLS是第一个将GAN应用于文本生成图像的,它的结构和条件GAN类似,改变是它用文本的embedding代替类别标签与随机噪声拼接起来作为输入。该方法的文本embedding是用一种从文本和图像对中学习文本和图像vector的方法中学习到的。该方法的生成器结构和DCGAN一样。在判别器中,将长度为K的文本vector复制为 形状为 [W*H*K] 的向量,然后和经过一系列处理之后的形状为 [W*H*C] 的图像向量拼接,得到的形状为 [W*H*(C+K)] 的向量再经过判别器的最后几层神经网络。该方法的思想是:让图像的每一个pixel都包含全部的文本信息,然后卷积层就会自动学习对齐文本内容和图像内容。GAN-INT-CLS的详细结构如下图2所示(该图来源于GAN-INT-CLS论文原文)。
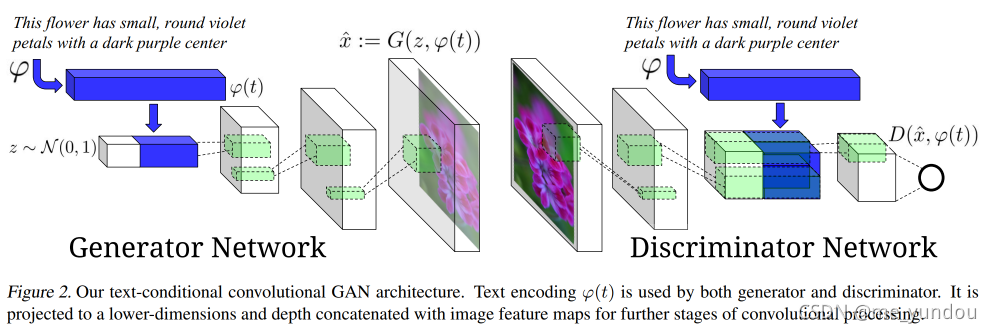
为了能够生成与文本对应的图像,该方法的判别器的输入数据分成三类:{real image, right text}, {real image, wrong text}, {fake image, right text}。
由于一个图像对应的caption有限,于是该方法使用manifold interpolation来获得 额外的文本embedding,让模型可以学习训练集中原本没有的文本内容,并且也不需要给这些文本打标签。
4.1 位置限制
虽然GAN-INT-CLS和StackGAN可以从文本生成图像,但是他们不能捕获图像中目标的位置信息。GAWWN提出了两种方法来编码图像中空间信息。一个是学习目标的bounding box信息:首先将长度为T的text emb同GAN-INT-CLS一样做空间复制为[M*M*T]的向量,然后将除了bounding box之外的位置都置为0.然后该向量通过若干卷积层得到一个1维的vector,与随机噪声z拼接之后作为生成器的输入。这个vector既包含了文本信息又包含了object的位置信息。并且该方法是端到端的,不需要额外的输入信息。
另一个方法是用人工定义的若干个keypoints来限制图像中目标的不同part(比如头,尾巴,脚等)。对每个keypoint,定义一个mask matrix [M*M],其中keypoint的位置置为1,其他位置置为0.然后K个keypoints拼接在一起得到 [M*M*K] 的向量。然后将该向量flatten成一个 [M*M] 的二元matrix,其中1代表keypoints的存在。虽然该方法使得对位置的定义更加细致,但是需要额外的人工来确定keypoints。即使GAWWN提出了一种方法能够从已有的keypoints里自动生成未见过的keypoints,但是该方法所需的人工cost还是不可忽视。
GAWWN的其他部分结构和GAN-INT-CLS一样,区别在于处理bounding box或者keypoint的部分是独立的。使用bounding box方法的GAWWN的详细结构如下图2所示,使用keypoints方法的如图3所示(该图来源于GAWWN论文原文,这里不详细说明,想了解的去看原文就好)。
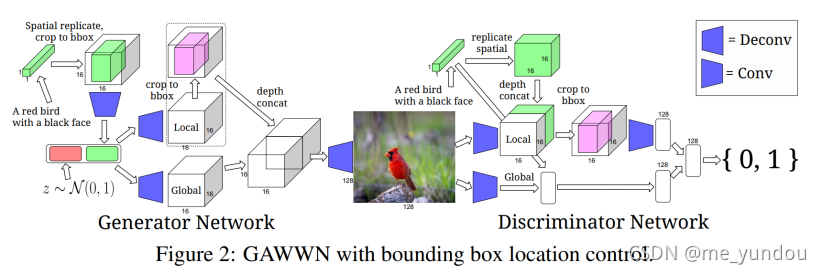
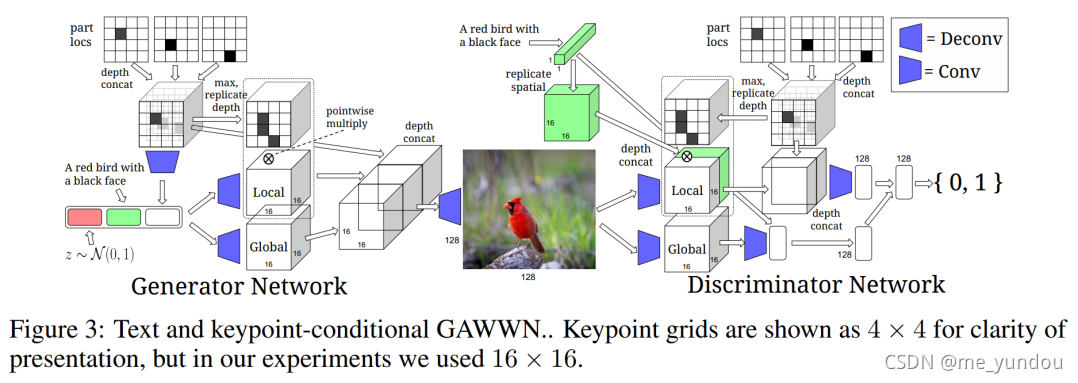
虽然GAWWN提供了两种方法来限制图像中的位置信息,但是它只能处理单目标的图像,目前也没有办法可以处理图像中有several objects的情况下的位置问题。从结果来看,GAWWN在数据集CUB上表现很好,但是在上生成的图像就很模糊并且让人看不懂content是什么。这可能是因为站立的鸟儿动作基本一致,而站立的人类动作有无数种。
指定图像中位置信息的最大好处是提供了更多的可解释性,并且模型能够understand图像中不同objects的内容了(但是目前还是单目标定位吧,多目标不可呢),这就是CV的最终目标啊。
4.2 使用堆叠GANs
StackGAN提出使用两个不同的生成器来做text-to-image synthesis。第一个生成器用来生成低分辨率的图像,包含大致的形状和目标颜色等。第二个生成器以第一个G的输出作为输入,生成更高分辨率更精细的图像。每个G都有对应的判别器D。除此之外,StackGAN还提出了一种数据增强技巧来产生更多的text emb。对于文本编码t,它不是直接使用 t 作为相应的text emb,而是学习一个t所在分布,从分布中采样得到文本输入。如下图2所示(图像来自StackGAN原论文)。
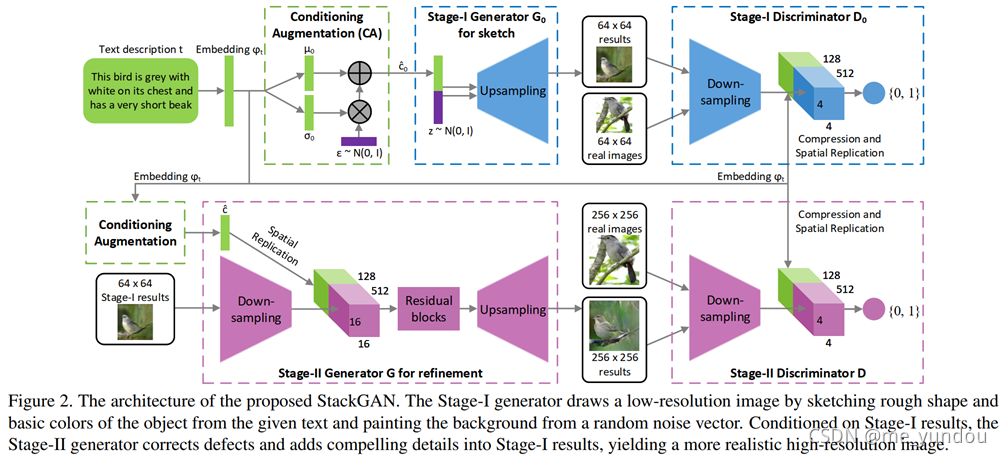
作为StackGAN的改进版,StackGAN++使用更多的生成器和判别器(超过两个),并且在判别器loss上增加一个unconditional图像合成loss(不知道是什么样的),并且使用一个颜色一致性loss。
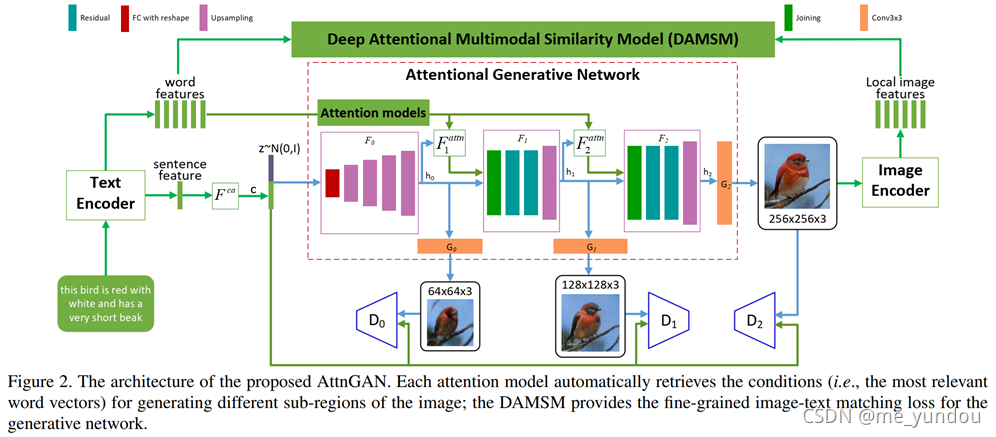
AttnGAN在StackGAN++的基础上又增加了注意力机制。它将文本表示成一个global sentence vector以及若干word vectors。第一个生成器G以噪声和sentence vector为输入,得到低分辨率的图像特征,然后该图像特征和word vectors一起结合注意力机制作为后一个生成器的输入;其他的生成器依次进行。除此之外,AttnGAN还提出了DAMSM来度量文本和图像的相似度,作为text-image 的匹配loss加在G的loss上。DAMSM使用sentence vector和word vectors以及最后一个生成器得到的图像encoder之后的local image features,用两个角度(分别将word vectors和image features作为注意力的query)的注意力机制来计算text-image相似度。如下图2所示(图像来自AttnGAN原论文)。实验体现了在图像合成中使用注意力机制的有效性,同时让模型更加具有可解释性。
通过使用堆叠的GAN,StackGAN,StackGAN++,AttnGAN比GAN-INT-CLS和GAWWN生成的图像更sharper,在CUB 和 Oxford-102数据集上。而在COCO数据集上,并没有体现出明显更好的结果。(个人理解,作者说这段话的意思是想要说明堆叠的GAN其实不一定能带来更好的结果吗?因为在不同数据集上结果有差异啊)
4.3 通过iterative sampling (迭代采样)
不同于直接在生成过程中使用text信息的上述方法,PPGN使用激活最大化方法来以迭代采样的方式生成图像。假定图像分布是p(x),文本分布是p(y),那么图像生成可以看做是从联合分布p(x, y)中采样得到的。通过变换使得:p(x, y) = p(x)p(y|x), 其中p(x)就是生成器的工作,p(y|x)就是image captioning的工作。PPGN使用一个预训练的image captioning model和一个image generator model来实现。
虽然这个采样方式在生成图像上花费时间更多,但是它生成的图像具有更高的分辨率和better quality,比前面那些方法。并且他的性能是基于class和基于text的图像合成中最好的。
4.4 目前text-to-image方法的局限
当前的text-to-image方法在single object图像生成上表现较好,虽然某些不够sharp。但是在多objects的图像生成上badly。一个可能的解释是model只是学到了图像的整体特征,而没有理解其中objects的concept。比如在区分卧室和客厅的时候,对床和桌子的学习可能只是学到了形状和颜色等,其实并没有理解它们的区别。
GAN是目前生成模型中能得到sharper图像的一类方法。但是未来想要生成更好的text-to-image图像,模型就一定要理解concept of things(也就是解决多objects的问题吧)。可能的方法是先训练能够学习不同objects的模型,然后训练一个整合这些objects到一张图像上的模型。这样的方法需要大量的不同objects数据以及包含这些objects的图像训练数据,也是很困难的。另一个可能的方法是用胶囊capsule思想,但是这样的胶囊如何训练也是问题。
五、image-to-image translation
一般意义上的image-to-image,就是以图像作为条件输入,然后将一种场景下的图像转换成另一种场景下的图像。这和style transfer一个意思,将content image的content和style image 的style结合成新的图像(新图像具有原来的content和新的style)。但是更广泛一点的概念还可以包含对objects的属性修改,比如人脸面部调整等。本文主要对一般的监督和无监督的t2t方法做介绍,后面还介绍了一些objects修改的内容,比如face editing(面部调整),image super resolution(图像高分辨率),image in-painting,video prediction等。这里的监督信息指的是source domain中的图像有对应的traget domain中的ground-truth image用来做训练。
5.1 监督的方法
Pix2Pix使用一个cGAN的loss和一个L1正则化loss一起做风格转移,来保证生成器不仅能生成骗过判别器的图像,而且生成的图像更像ground-truth的图像(也就是另一个风格的)。其中cGAN的loss如下面公式,x和y是训练集图像,分别来自不同风格,y是target domain。z是随机噪声。
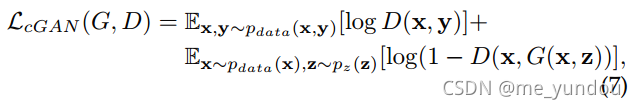
用来限制生成图像与target domain 相似性的L1 loss定义如下:
![]()
然后总的loss如下:
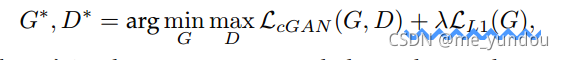
Pix2Pix的作者发现噪声z对输出的结果没有太大影响,所以他们去掉了z,在训练和测试过程中做dropout来代替从随机分布中采样噪声。
Pix2Pix的生成器结构基于U-Net,属于编码-解码框架,其中添加了从编码器到解码器的skip connections 来允许模型绕过一些瓶颈来共享low-level的信息(比如objects的edges)。
其判别器结构是PatchGAN,不是直接对整个图像进行真假判别,而是将图像分成一个个的patches来做判别,然后将patches的分数做平均作为整图的判别结果。这样做的原因是,L1和L2正则化得到的图像比较模糊,不能得到高分辨率的图像,但是他们在低分辨率上结果较好。Pix2Pix认为它们在生成小的patch上是足够有效的,所以通过处理多个小的patches来实现对大的高分辨率的整个图像的生成。
虽然Pix2Pix生成的图像非常好,它最主要的缺点是需要成对的训练图像作为监督信息,就是公式(7)中成对的x和y。(而实际上,这样的训练数据是非常难得到的)
六、合成图像的评估指标
对生成图像质量的评估是很难的。直接比较合成图像和对应的真实图像的RMSE指标不能再用了,因为更多的合成图像没有对应的真实图像了。现在,一个常用的主观标准是AMT,就是雇佣人对合成和真实图像打分,反映人对这些图像的真实程度的看法。(但是这方法太主观了,不同人的感觉不一样)。所以我们需要更客观的指标来评估生成的图像质量。
Inception score (IS)是基于对合成图像进行分类来做图像质量评估的。该评估方式的内涵在于如果一张合成图像越真实,那么分类器(已经预训练好的)对该图像进行分类的条件概率p(y|x)的entropy应该越低,也就是说,分类器非常能够确定该图像的类别。同时,为了让模型能生成更多类别的图像,marginal distribution(边缘分布)p(y) 的entropy应该越高越好(就是说生成的全部图像的类别应该多一些)。IS评估指标就是上述两个方面的结合,它对标签的前验分布和适当的距离度量都不敏感。但是这个评估标准仍然有intra-class 模式崩溃的问题,即生成器只要能够生成某一类别的高质量图像,就能得到非常高的IS值。
和IS类似,FCN-score也是基于用真实图像训练出的分类器对越真实的合成图像分类正确率应该越高,这样的思想。但是对图像进行正确地分类通常不需要图像非常sharp,所以基于分类的合成图像评估指标无法分辨两个不同图像之间的细节差异(也就是说如果合成图像和真实图像只是在一些detail地方有不同,基于分类器的指标就没办法区分它们,不能很好地评估合成图像的真实性)。另一方面,[96]的研究表明,图像的分类结果并不是完全依赖于视觉内容,反而会极大地被一些人类不可见的噪声影响。因此,基于分类的评估方法问题还是很多。
Fre´chet Inception Distance (FID)的思想和上述方法不同。FID将合成图像编码到一个隐式特征空间,然后合成图像和真实图像的embeddings就可以看做是从两个连续的多元高斯分布中采样得到的。通过计算这两个高斯分布的Frechet Distance就可以度量合成图像和真实图像之间的差距(也就是合成图像的质量)。[97]的作者表明,FID的评估结果和人的判断结果高度一致,FID结果与合成图像的质量好坏密切相关(就是说能够直观反映合成图像的质量情况)。并且相比于IS,FID受噪声影响较小,而且可以detect intra-class 的模式崩溃问题。
除了上面这些,还有许多其他的合成图像质量评估方法,比如 Gaussian Parzen Window [4], Generative Adversarial Metric (GAM),MODE score等。在这些方法中,IS使用最广泛,FID虽然是新提出的,但是已经被证明比IS效果好。

















 411
411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









