







记录一下这周看的论文。
论文名称–《通过有向图神经网络的基于骨架的姿态识别》
1.引言:
对于现在来说,最主要的有3中方法,RNN,CNN,GCN,分别通过序列向量,伪图像,和图来表示各个关节之间的联系。就是说对于骨架,分为关节和骨头,所以如果我们能够在姿态识别的过程中,把关节和各个骨头之间的关系都考虑进去,其实我们会发现对识别有很大很大的提高。现存的基于图的模型,它的关节和骨头的模型是2个相互分离的网络,所以并不能完全表示出关节和骨头之间的相互依赖性。为了解决这问题,作者提出了把骨架作为一种有向无循环图的方法,其中把关节作为节点,把骨头作为边。在这个模型里面,通过图的有向边,完美的结合了关节和骨头之间的依赖性。这个模型就是DGNN(a novel directed graph neural network),在这个模型里面它能够传播邻接关节和骨头之间的关联信息在神经网络的每一层中。最后精炼出的特征不仅仅包含了每一个关节和骨头的信息,而且也包含了关节和骨头之间关联性的语意信息,让姿态识别更加的高效。
另外一个问题就是在设计的原始手部结构之中,它可能并不能够很好的去完成姿态识别的任务。比如,双手在拍掌和拥抱的时候会有很强的依赖性,但是在最开始直接根据人体结构构造的图结构之中并没有包含这其中的依赖性(就比如说传统之中我一个姿态识别出了双手,可能我还会进一步提取特征信息,然后才能预测出是在拥抱后者拍掌,但是现在的模型的话,如果预先识别出了双手,那么模型就会直接大概率的预测,姿态有很大的可能是拥抱或者拍掌,或者对双手有很强依赖的动作)。所以通过在另一篇论文的启发,我们通过自适应图去解决了这个问题。就是把图的这种拓补结构作为一种参数,通过学习过程进行优化。
双流结构,一种广泛的方法在基于RGB的姿态识别之中。在框架之中建立一帧一帧的时间依赖关系就是说在一个视频中每一帧都是一个动作信息嘛。通过这个方法我们精炼出动作信息。通过空间信息和动作信息的双流框架结构,我们是效率得以更加的提升。
主要贡献:
1.第一次用有向无循环图模型去表示骨架数据去模拟骨头和关节的依赖性。
2.把图结构作为一种参数通过学习优化,让图结构更加适用于姿态识别的任务。
3.通过时域模型中每一帧之间的信息提取出动作信息,然后将动作信息和空间信息放入双流框架结构之中进行最后的操作。
4.在当前的2个基于骨骼的数据集之下,获得了目前的最好效果。
2.相关工作。
2.1基于骨架的姿态识别
之前说过了现在流行的三中姿态识别的方法。相比之下,基于图的方法更加优于其他2中方法,因为图的能够更加直观的表现人体的结构,因为就人体而言首先就会被看做是一个图结构而不是一个序列或者伪图像
2.2图神经网络
这个就不多说了,就是在图神经网络之中的话,每个节点都可以聚合邻居节点的信息,随着研究的深入,现在也有很多模型可以同时聚合边的信息。
3.方法
通常,这个给予的骨架数据是一系列的序列框架,我个人的理解为就是这个骨架动作的每一帧把,就是每一帧都会有一个骨架,就相当于是那种图像把,就是骨架图形静态的。然后就是很多很多就是构成一个序列那种。然后我们通过各个关节的2D或者3D的坐标来提取骨头的信息。然后再每一帧之中,这个关节的信息和骨头的信息,就被节点或者边通过有向无循环图表示出来。(以上就是空间信息),然后输入DGNN提取特征用于姿态识别。最后,动作信息和空间信息一同输入之前说过的双流框架结构,进一步提高性能。所谓双流框架结构我个人的理解是,其实就是一个融合把,就是把空间信息和动作信息做一个融合得到融合之后的语意信息,然后做预测,进一步提高性能。
3.1骨头信息
之前我们说够关节信息和骨头信息一起考虑对于姿态识别的重要性。然后的话骨头信息用两个链接的关节的不同坐标表示。例如一个3D的骨架数据之中:两个关节V1=(X1,Y1,Z1),V2=(X2,Y2,Z2),那么这条边的话就可以表示为Ev1,v2=(X1-X2,Y1-Y2,Z1-Z2)
3.2图结构
对于图结构定义Vi进来的边为e-,出去的边为e+.对于一个边ej,其源节点为vs,j.目标接地为vt,j。很好理解。然后有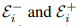
对于一个节点i,代表进入的边的集合,和出去的边的集合
对于每一帧有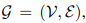
这是图的基本定义,点的集合,边的集合。
所以有对于一个视频骨架数据有因为有很多帧嘛。就是有
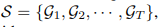
之前说过每一帧都是一个骨架信息。(静态骨架图),T代表视频的长度。
3.3有向图神经网络
神经网络包含很多层,输入的图中包含节点和边的属性,输出为更新之后的图属性。在每一层之中这个节点和边的属性都可以根据邻接边和节点的属性更新。在底层第一个节点和边只能根据邻居节点和边进行更新。因为有很多层嘛,在顶层的时候节点就能够累积到远处的节点信息。
3.3.1
有向图神经网络块
包含2个更新函数和2个聚合函数
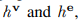
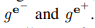
聚合函数聚合节点边的信息,更新函数根据聚合的边的信息之后更新节点的信息,用公式表达如下
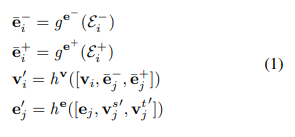
公式1,2就是聚合节点i的边的信息。公式3,4就是更新节点和边的信息。公式3的参数是指节点i和节点进入的边和出去的边,公式3的参数后面的j应该是i作者写错了。公式4的参数是边j和边j的目标节点和源节点。
整个过程就是更新节点和边的信息。在广泛的实验中,我们选择用平均池化函数去聚合边的信息,然后选择用一个单一全连接层用于更新函数。
3.3.2有向无循环图的实现
实现DGN块,输入节点数据实际上是一个CT N的一个张量f,张量就是一个单位。C是指通道的数量,T是帧数的数量,N是图中的节点数。一样边数据CTN,f。这种方法输入的形式实际上是一种不太满意的输入形式。实现DGN的关键是找到每个节点的输入边和输出边,和去找到每个边的目标节点和源节点。最后,作者使用了图的关联矩阵。
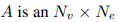
以上为关联矩阵
如果V是e的源节点,则Aij为-1,是目标节点,则Aij=1.如果没关系则是0
为了去分离源节点和目标节点。我们用。As,和At,来表示。As的意思是在关联矩阵中为-1的为1,其他为0.At的意思是在关联矩阵中为1的为1,其他为0。
以下举例。
如图
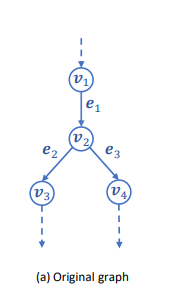
那么其关联矩阵为
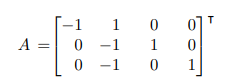
源节点矩阵

目标节点矩阵

以上矩阵根据之前的阐述不难得出。
现在给定输入的张量和关联矩阵,我们就能够分离出需要的边和节点了。例如:
如上图就得到的是一个CT*Ne的张量。
所以根据矩阵相乘的定义有了,每个张量元素就包含了源节点和其边的信息。得到的就是每个边的源节点乘以对应节点张量的和。然后对于关联矩阵需要进行标准化,定义为
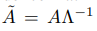
其中
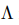
是对角矩阵。
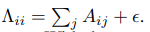
就是每一行的和。后面那个是一个非常小的数,是为了避免其值为0。然后的话公式一就可以转换成
.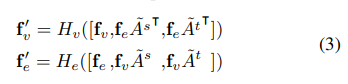
H是一个全连接层,就像是公式1的更新函数。在更新完节点张量和边张量之后,我们再加一个BN层和一个ReLU层,在每一个DGN之后。
3.3.3自适应DGN块
自适应块我们之前讲过,就是图结构当做参数通过学习进行更新。具体方法是输入A然后学习A的参数。这里的A是指关联矩阵。在每一次训练循环之中都去修改A的参数。这就让图结构更加的灵活。
3.3.4时域信息模型
在每一个DGN块更新完空间信息之后,作者会加一个时域的1维卷积的时域信息,具体是现实就是用每一帧的序列向量,就相当于是RNN里的方法吧,这里作者就是变相的将RNN的方法和DGNN的方法结合了。一维卷积层也一样后面接一个BN层和一个RELU层。叫做TCN。每一次DGNN都包括9层。每一个都包含一个DGN块和一个TCN块,然后最后再加一个sof tmax 层用作预测。
3.3.5双流框架模型
如之前说的一样,会有空间信息和动作信息两部分进入两个一样的网络进行训练,然后将两个网络输出的结果输入一个sof tmax层做最后的预测。空间信息就是之前以上的操作。然后的话就是动作信息了,那动作信息如何得到呢。就是每个相邻帧之间的差具体操作就是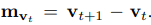
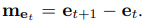
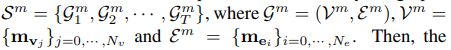
将以上参数按照空间信息的操作一样通过DGNN得到一个基于动作信息的预测值然后。动作信息和空间信息一起进入sof tmax 层,输出值做出最后的确定的预测。
最后的话,由于本文没有框架图,我就大致简单的画一个吧。

因为文章没有框架,然后就是自己大致画的一个框架。
讲一下吧,就是首先的话输入是骨架数据节点的张量,和边的张量。然后看DGNN的上面的话,里面会有2个网络,一个是聚合更新节点信息的网络,一个是聚合更新边信息的网络,然后其中函数H的公式表达为公式3.然后进过一个BN层进行标准化,然后再经过一个激活函数。这是DGN块,之后又要进入一个TCN块,这个块的作用是把经过图神经网络之后节点边数据和一个时域信息相结合,按照我的理解其实就是把经过图神经网络之后的信息和之前的方法基于RNN对序列向量处理之后的数据进行合并,一起来评估姿态,当然肯定效率更加好。但是相应的时间耗费必然更大。在经过TCN之后最后经过一个softmax函数,把数据映射到0到1之间,用来预测姿态。然后看下面的一部分实际上是和上面一样,就是输入的数据不一样。这个输入的数据就是2个帧之间的差值,节点值,边值都是2个时刻之间的差值。用来表示为其动作信息,就是我2个骨架数据,通俗点就是2个图片之间的不同嘛,也就是动作信息,最后也会得到一个0~1的值,然后在最最后把2个值均输入一个softmax函数,得到最终的一个预测值,用以预测姿态。
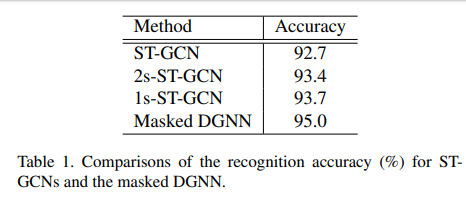
4.Experiments
















 1217
1217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









