







摘要:
当前最好的检测器和跟踪器正在往越来越快方向发展。跟踪的计算量一般小于检测,但是有漂移的问题。利用现有的检测/跟踪器在给定的计算条件下来提高精度。最常用的做法是隔N帧进行一次检测,检测之间做跟踪,但是检测的频率取决于跟踪的精度。本文提出一个调度网络,确定当前帧做检测还是做跟踪,虽然调度网络比较轻量,但是比隔真检测更有效。
一. 引言:
跟踪器在效率和精度上一般比检测器要高一些,但是存在不能长时间跟踪的问题。常见的做法是一旦置信度不高的时候就停止跟踪。而且跟踪都面临漂移的问题。在检测和跟踪之外,也有一些视频检测的工作,和单帧检测相比更所的是利用了时间信息,常见的方法比如管道提取、光流和基于跟踪的回归。然而这些工作是对单帧检测性能的提高,并没有实现不同帧之间目标轨迹的生成,并且比较耗时。
本文工作的出发点来自实际视频分析场景的限制,比如自动驾驶和视频监控。本文认为这些场景的算法应该具有这些能力:
关联帧间的检测生成轨迹
实时性强
低延迟
本文为了处理任务的实时限制,提出了DorT框架,将问题转化为序列的决策问题,决定刚进来的每一帧检测还是跟踪,整个架构如图1所示

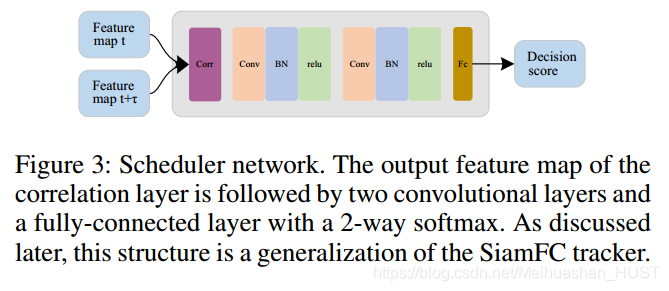
调度网络是本框架中最重要的部分,他是轻量的去确定当前帧检测还是跟踪。而不是用经验性的规则,他本质是一个小的CNN结构用来评估跟踪质量。他可以看做是Siamese tracker的一种通用形式,是强化学习的一种特例。
本文的贡献在于
提出DorT框架,将视频视为检测和跟踪的决策问题
提出轻量的调度框架,这是siamese tracker的推广和强化学习的特例
二. 相关工作:
视频检测/跟踪
作者主要diss 两点,首先是方法繁琐实时性差。然后没有做帧间的关联
多目标跟踪
大多数多目标跟踪集中在数据的关联,寻找最优的检测结果的轨迹。当前的MOT分两种,一种是批量的,做局部的最优,有一定延迟,一种是在线的,做当前帧的最优,是实时的。在线的方法[2015]将数据关联视为马尔科夫随机场。[2017]RNN用作特征表达和数据关联。自从提出MOT challenge,当前最好的MOT算法都是致力于提高数据关联的性能。然而本文着眼于序列的决策,
虽然使用匈牙利算法比较起来比较公平,但是我们相信结合MOT方法会进一步提高准确率。
关键帧调度
在关键帧调度方面已经有一些工作,比如根据评估光流的质量确定关键帧,这依赖于耗时的光流网络,chen,2018提出的easiness measure 考虑小目标的运动和大小,他是手工设计的特征,而且是检测之后确定,不能在之前确定检测还是跟踪。Li Shi Lin;Xue 2018 学习预测当前帧和关键帧之间的分割结果的差异,但是他只能应用在分割领域。这些方法都解决了额外的问题,光流的质量,分割结果的差异,但是并没有给出直接的分类结果,这一帧是不是关键帧,相比之下,本文提出的方法直接学习当前帧是不是通过评估跟踪的质量判断关键帧,本文的方法可以看做是强化学习的特例和Siamese的推广。
三. DorT框架
视频目标检测/跟踪形式化为,给定一个视频序列F={f1,f2,f3,f4…Fn}。目标是获得B={b1,b2,b3…bn},这里bi={rect,fid,score,id}其中rect为目标的坐标,fid为帧号,score为置信度,id为目标编号。
3.1 单帧目标检测
R-FCN
3.2 多box跟踪
本框架中使用2016年SiamFC tracker,传入一个区域,然后响应最大的位置为跟踪位置,在原文中可以达到86fps。虽然他比较快,但是是单目标跟踪,而R-FCN输出的一般有30-50个目标,自然的想法是跟踪置信度最高的,忽略低的,但是由于R-FCN并不一定检测结果那么准,造成错误拒绝一些准确位置。为了优化速度,本文提出ROI Convolution layer,代替原本的cross-correlation layer实现特征计算共享,如图2所示
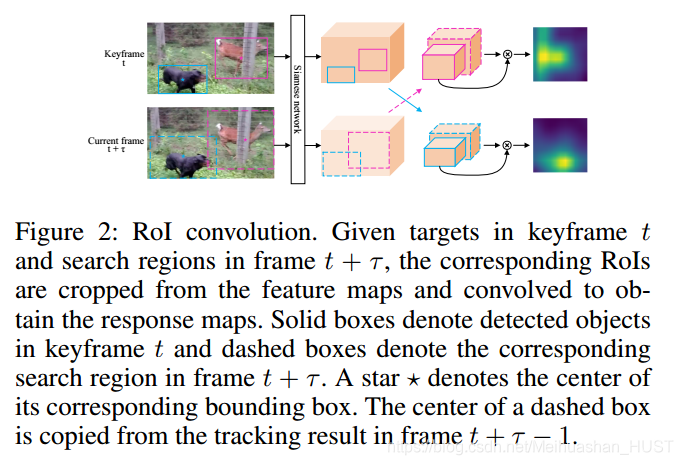
这里就是相关滤波,将特征换成 了CNN特征。由于特征共享,加速了10倍。
3.2 调度网络
调度网络输入当前帧f(t+x)与他的关键帧f(t)确定检测还是跟踪,y=Scheduler(f(t),f(t+x))。
3.3 数据关联
一旦调度网络确定当前帧是检测,那么他的输出结果就需要和之前的跟踪结果关联。为了公平比较,本文采用广泛使用的匈牙利算法做关联,但是为了提高准确率,完全可以采用更优的算法,比如Xiang, Y.; Alahi, A.; and
Savarese, S. 2015. Learning to track: Online multi-object tracking
by decision making. In ICCV,Sadeghian, A.; Alahi, A.;
and Savarese, S. 2017. Tracking the untrackable: Learning to track
multiple cues with long-term dependencies. In ICCV
四. 调度网络
他通过估计跟踪框的质量,确定当前帧进行跟踪还是检测,他本身应该高效的。而不是重头开始训练一个网络,本文重用了跟踪网络的一部分。首先,t帧第l层的卷积记为x(l,t),将t和t+m层的特征做相关
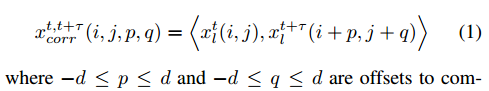
这样得到的特征图的维度为HW(2d+1)。然后再经过两个卷积层,一个FC层,得到一个2元的softmax分类结果。如图3所示
4.1 训练数据准备
VID中并没有对于跟踪质量的标记,本文取出两帧,仿真跟踪过程,将他们标记成detect(0)或者track(1)用下面的规则。本文用SiamFC从t帧跟踪到t+m帧,如果所有在t+m帧中的groundtruth box和track box的IOU大于0,8,就想t+m帧标记为跟踪,否则为检测。任何消失或者出现的物体的帧都会标记为检测。
4.2 SiamFC Tracker的推广
4.3 强化学习的特例
5. 实验














08-09
 134
134
134
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









