







 本文介绍了概率论的基础概念,包括事件、概率、随机事件及随机变量等。详细讲解了事件的概率计算法则,以及随机变量的两种类型:离散型与连续型,并探讨了它们的期望值、方差等关键特性。
本文介绍了概率论的基础概念,包括事件、概率、随机事件及随机变量等。详细讲解了事件的概率计算法则,以及随机变量的两种类型:离散型与连续型,并探讨了它们的期望值、方差等关键特性。
抽样分布:从间断性变数总体的理论分布(二项分布和泊松分布)和连续性变数总体的理论分布中抽出的样本统计数的分布,即抽样分布。
一、事件和事件发生的概率
事件:在自然界中一种事物,常存在几种可能出现的情况,每一种可能出现的情况称为事件
事件的概率:每一件事出现的可能性,称为该事件的概率(probability)。
随机事件:某特定事件只是可能发生的几种事件中的一种,这种事件称为随机事件(random event)。
统计学上用n较大时稳定的p近似代表概率。
统计学上通过大量实验而估计的概率称为实验概率或统计概率,以表示。
P代表概率,P(A)代表事件A的概率,。
随机事件的概率表现了事件的客观统计规律,它反映了事件在一次试验中发生可能性的大小,概率大表示事件发生的可能性大,概率小表示事件发生的可能性小。
若事件A发生的概率较小,如小于0.05或0.01,则认为事件A在一次试验中不太可能发生,称为小概率事件实际不可能性原理,简称小概率原理。这里的0.05或0.01称为小概率标准。农业试验研究中常用这两个小概率标准。
随机事件的特例:对于一类事件来说,如在同一组条件的实现之下必然要发生的,称为必然事件(certain event 概率1)。如果在同一组条件的实现之下必然不发生的,称为不可能事件(impossible event 概率0)。
二、事件间的关系
在实际问题中,不只研究一个随机事件,而要研究多个随机事件,这些事件间又有一定的联系。
(1)和事件
事件A和B至少有一个发生而构成的新事件称为事件A和B的和事件,记为A+B,读作‘或A发生,或B发生’。
(2)积事件
事件A和B同时发生而构成的新事件称为事件A和B的积事件,记为AB,读作‘AB同时发生或相继发生’。
(3)互斥事件
事件A和B不可能同时发生,AB为不可能事件,记为AB=V,称事件A和B互斥或互不相容。
(4)对立事件
事件A和B不可能同时发生,但必发生其一,即A+B为必然事件(记为A+B=U),AB为不可能事件(记为AB=V),则称事件B为事件 A的对立事件,记为B为
(5)完全事件系
若事件 两两互斥,且每次试验结果必发生其一,称
为完全事件系。
(6)事件的独立性
若事件 A发生与否不影响事件B发生的可能性,则称事件A与事件B相互独立。
三、计算事件概率的法则
(1)互斥事件的加法
事件A和B为互斥事件,则其和事件
(2)独立事件的乘法
事件A与事件B相互独立,同时发生概率为
(3)对立事件概率
事件A概率为,其对立事件概率:
(4)完全事件系概率
例如:从10个数字中随机抽得任何一个数字都可以,这样一个事件是完全事件系,其概率为1。
(5)非独立事件的乘法
如果事件A和B是非独立的,那么事件A和B同时发生的概率为事件A的概率P(A)乘以事件A发生的情况下事件B发生的概率P(B|A),即
四、随机变量
随机变量是指随机变数所取的某一个实数值。

1、离散型随机变量(discrete)
(1)当试验只有几个确定的结果,并可一一列出,变量y的取值可用实数表示,且y取某一值时,其概率是确定的,这种类型的变量称为离散型随机变量。将这种变量的所有可能值及其对应概率一一列出所形成的分布称为离散型随机变量的概率分布。
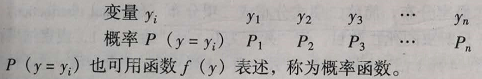
因为构成一完备组,所以
(2)概率分布类型
0-1分布
均匀分布
(3)离散型随机变量的期望值和方差
在实际问题中,一个随机变量的概率分布不好确定;有些问题不需要知道y的全部概率性质,只需知道某些数字特征即可。
所以,对随机变量的研究中,确定某些数字特征很重要。
i: 期望值(Expected value): 表示随机变量本身的平均水平或集中程度。
一般实际数据的加权算术平均数是具体数据的平均指标,期望值是随机变量y的期望指标。
ii: 方差和标准差:随机变量与其数学期望的离差的平均水平,可测定随机变量的变异程度或离散程度
方差实际上是随机变量y的函数
的数学期望。y是离散型变量,可写成:
式中:
证明:
若y的取值比较集中,则方差较小;若比较分散,方差越大。方差=0,随机变量取值集中在期望值,随机变量以概率1取值
。
随机变量方差的标准差与随机变量有相同单位,所以在实际中经常使用。
(4)应用
离散变量预期期望值相同时,计算标准误来评价投资或模型的稳定性和风险性,愈小越稳定,风险越小。
期望值不同,计算离散系数,标准误/均值,每单位的均值所承受的风险,越大,风险越大。
2、连续型随机变量(continuous)
变量y的取值仅为一范围,且y该范围内取值时,其概率是确定的。此时取y为一固定值是无意义的, 因为在连续尺度上一点的概率几乎为0。这种类型的变量称为连续型随机变量。对于随机变量,若存在非负可积函数,对任意 a,b(a<b) 都有:
则称 y 为连续型随机变量(continuous random variate), 为y的概率密度函数(probability density function)或分布密度(distribution density)。因此,它的分布由密度函数所确定。若已知密度函数,则通过定积分可求得连续型随机变量在某一区间的概率。
随机变量可能取得的每一个实数值或某一范围的实数值是有一个相应概率的,这就是所要研究和掌握的规律,这规律称为随机变量的概率分布。
随机变量完整地描述了一个随机试验,不仅说明了随机试验的所有可能结果,还说明随机试验各种结果出现的可能性大小。对随机试验概率分布的研究,就转成了对随机变量的概率分布的研究。须注意事件发生的可能性与试验结果是不同的,前者是指事件可能发生的概率,后者是指特定试验结果,这种结果可能是概率大的事件发生了,也可能是概率小的事件发生了。概率分布指明了不同事件发生的可能性。
随机变量是用来代表总体的任意数值的,随机变数是随机变量的一组数据,代表总体的随机样本样本资料,用来估计总体的参数。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









