









一.算法介绍
还是那句话:统计学习=模型+策略+算法
1.模型
logistic模型是对条件概率进行了建模:
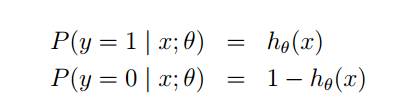
虽然叫做logistic回归,但实际上解决的是基本的二分类问题,因此可以建立上述的条件概率模型。
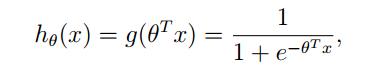
这里利用了sigmoid函数的特性,比之线性模型,应当是一个更加合理的模型
2.策略
在建立好概率模型之后,本算法使用的策略是最大似然法则,同样可以理解成最小经验风险准则。给定一个训练集(xi,yi),那么对于每个xi都可以得到p(y|x)的概率(由参数theat表示),把他们乘起来即可得到似然表达式,如下所示:
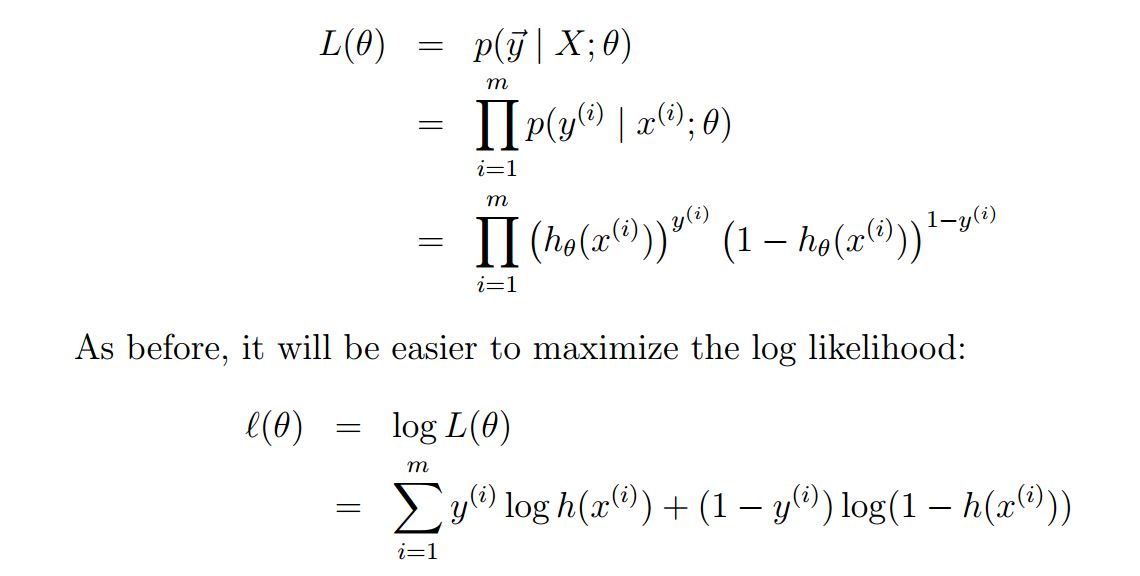
目标就是最大化上述的似然表达式
3.算法
sigmoid函数是一个非线性函数,上式没法求得闭式的最优解。因此可以采用梯度上升算法来求解最大值,即如下所示:
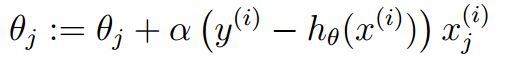
在实际求解中往往使用随机梯度下降法,关于随机梯度下降和批量梯度下降,详见:
http://www.cnblogs.com/murongxixi/p/3467365.html
二.python实现
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix)
weights = ones(n) #initialize to all ones
for j in range(numIter):
dataIndex = range(m)
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001 #apha decreases with iteration, does not
randIndex = int(random.uniform(0,len(dataIndex)))#go to 0 because of the constant
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights上面的代码片段使用的是随机梯度下降算法,同时还对步长alpha做了一些处理,会随着迭代次数的增加而下降。这也是一种比较好的做法,因为在实际的应用场景下,往往会有个别难以正确分类的数据,因为这些数据而大幅改变参数是不合理的。通过对步长的修改,使得当迭代次数很大的时候,步长变小,这样就会使得参数不会太受无法分类点的影响。















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









