









一.算法介绍
《统计学习方法》对adaboost算法进行了相当精彩的介绍,尤其是后面证明adaboost算法是前向分布加法算法的特例,这就将adaboost算法拉入到 统计学习=模型+策略+算法这一框架中。
1.模型:
加法模型:
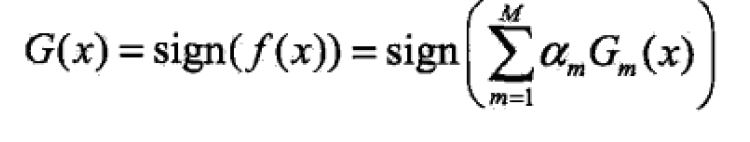
Adaboost算法期望用一系列不同权重的基函数的和来构成最终的分类器。
2.策略
采用指数损失函数
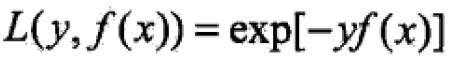
3.算法
采用逐层逼近的算法,每次寻求一个alpha 和 g(x)。具体的选取策略详见教材。
按我的理解,adaboost算法生效的前提是问题是可学习问题,即每次都能选取到一个分类误差率大于0.5(随机猜测应当是一半对一半的误差率)的弱分类器。只有这样,才能保证权重的更新有实际意义
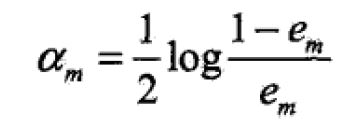
em是该弱分类器的分类误差,em<0.5时,alpha会大与0
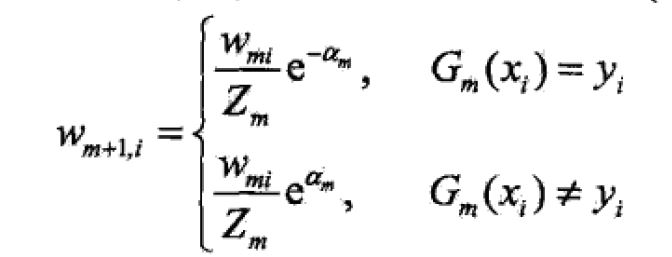
当alpha大于0时,才会扩大误分类训练样本的权重。
二.python实现
单层决策树生成程序
#这个函数要构建的是一个单层的决策树,但是输入特征向量是二维的,所以需要遍历每一维的特征。对于这里寻找得到的单层决策树,其误差error为0.2是小于0.5的,这跟我自己的理解应当是一致的。
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = mat(zeros((m,1)))
minError = inf #init error sum, to +infinity
for i in range(n):#loop over all dimensions,遍历每一维的特征
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max();
stepSize = (rangeMax-rangeMin)/numSteps
#遍历大量可能的决策树,寻找其中加权误差最小的
for j in range(-1,int(numSteps)+1):#loop over all range in current dimension
for inequal in ['lt', 'gt']: #go over less than and greater than
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)#call stump classify with i, j, lessThan
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T*errArr #calc total error multiplied by D
print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError)
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEstAdaboost的训练过程
#每次迭代都会在当前权重下再训练一个弱分类器,然后级联进去
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m) #init D to all equal
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)#build Stump
#print "D:",D.T
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#calc alpha, throw in max(error,eps) to account for error=0
bestStump['alpha'] = alpha
weakClassArr.append(bestStump) #store Stump Params in Array
#print "classEst: ",classEst.T
expon = multiply(-1*alpha*mat(classLabels).T,classEst) #exponent for D calc, getting messy
D = multiply(D,exp(expon)) #Calc New D for next iteration
D = D/D.sum()
#calc training error of all classifiers, if this is 0 quit for loop early (use break)
aggClassEst += alpha*classEst
#print "aggClassEst: ",aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print "total error: ",errorRate
if errorRate == 0.0: break
return weakClassArr,aggClassEst随着训练的进行,在训练新的一轮分类器时,那些分类正确的样本点的权重会越来越小。所以当迭代次数很大的时候,会出现过拟合现象。当弱分类器数目很多的时候,此时得到的强分类器模型已经很复杂了,所以会出现过拟合现象。而对于像loistic回归这样的分类器,其分类平面就是一个超平面,应当是不可能出现过拟合现象。















 338
338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









