







NLP-transformer学习:(2)transformer的 pipeline
基于 NLP-transformer学习:(1),这里对transformer 更近一步,学习尝试使用pipeline
学习内容:
- pipeline 知识基础:
- pipeline 实战:
- gpu 上跑模型:
1 pipeline 基础基础知识:
pipeline:字面意思就是流水线:包括数据预处理+模型调用+结果后处理。pipeline() 提供了在任何语言、计算机视觉、音频和多模态任务上使用 Hub 中的任何模型进行推理的简单方法, 如图
pipeline 的huggingface 参考教程:https://transformers-doc.100sta.com/docs/transformers/v4.31.0/zh/pipeline_tutorial#pipeline
pipeline 支持的任务:
| No | task | type | detail |
|---|---|---|---|
| 1 | text-clasification(sentiment-analysis: ) | text | 文本分类,情感分析 |
| 2 | token-clasification(ner ) | text | 识别 |
| 3 | quesion-answering | text | 问答 |
| 4 | fill-mask | text | 掩码填充 |
| 5 | summarization | text | 摘要生成,阅读理解 |
| 6 | translation | text | |
| 7 | text-2-text generation | text | sequence to sequence |
| 8 | text-generation | text | |
| 9 | quesion-answering | text | 问答 |
| 10 | conversational | text | 对话 |
| 11 | table-question, answering | text | 表格问答 |
| 12 | zero-shot-classification | text | 0样本分类 |
| 13 | automatic-speech-recognition | multimodal | 语音识别 |
| 14 | feature-extraction | multimodal | 特征抽取 |
| 15 | audio-classification | audio | |
| 16 | visual-question-answering | multimodal | 视觉问答 |
| 17 | document-question-answering | multimodal | 文档问答 |
| 18 | zero-shot-image-classification | multimodal | 图像0样本分类 |
| 19 | zero-shot-audio-classification | multimodal | 音频0样本分类 |
| 20 | image-classification | image | |
| 21 | zero-shot-object-classification | multimodal | 音频样本分类 |
| 22 | video-classification | multimodal | 视频分类 |
通过代码也可以看支持哪些任务:
# print the support task
from transformers.pipelines import SUPPORTED_TASKS
for k, v in SUPPORTED_TASKS.items():
print("---------------------------")
print(k, v)
运行结果
2 pipeline 实战 :
代码:
from transformers import pipeline
# case 1 text-classification
model_id = "distilbert/distilbert-base-uncased-finetuned-sst-2-english"
text_pipe = pipeline("text-classification", model=model_id)
print("case1:")
print(text_pipe('good!'))
# case 2 sentiment
model_id = "facebook/detr-resnet-50"
sentiment_pipe = pipeline("object-detection", model=model_id)
print("case2:")
print(sentiment_pipe('/home/mex/Desktop/learn_objdetect/datasets/coco128/images/train2017/000000000025.jpg'))

注:其中,第一次运行时没有模型,需要下载
运行结果:

可以看到对于情感判断的 case1 ,我写的是好的积极的判断正确,
同时case 2 是一张来自与目标检测coco数据集的图片,是一只长颈鹿,这个模型也是运行正确

还有一点要注意:
就是之前的写法可以不写明模型id(model_id),但是目前我用的 transformer 需要增加,如果不增加就会报出如下错误

model id 怎么看? 在章节1 中的打印可以看到
例如:


当我们登录 huggingface 后,选择界面上的 models
比如我们选择 uer
选择 uer/roberta-base-finetuned-cluener2020-chinese
进入进去后,我们看到的开头就是 model_id就是我们想要的

3 gpu 运行 :
代码:
# case 3
import torch
import time
model_id = "facebook/detr-resnet-50"
objdct_pipe = pipeline("object-detection", model=model_id)
start = time.time()
for i in range(30):
objdct_pipe('/home/mex/Desktop/learn_objdetect/datasets/coco128/images/train2017/000000000025.jpg')
end = time.time()
print("case 3:")
print("cpu time:" + str((end - start)))
model_id = "facebook/detr-resnet-50"
objdct_pipe = pipeline("object-detection", model=model_id, device=0) # chose gpu 0
objdct_pipe.model.device
torch.cuda.synchronize()
start = time.time()
for i in range(30):
objdct_pipe('/home/mex/Desktop/learn_objdetect/datasets/coco128/images/train2017/000000000025.jpg')
torch.cuda.synchronize()
end = time.time()
print("gpu time:" + str((end - start)))
运行结果:
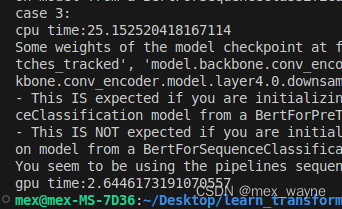
可以看到gpu 明显运行快很多,但是不要比运行一次的,因为gpu开始和结束需要同步,比较耗时。















 3810
3810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









