







 本文介绍了一种新的跨媒体细粒度关联学习方法,该方法支持五种媒体类型的数据交叉检索,通过跨媒体循环神经网络和联合关联损失函数解决了“异构鸿沟”问题,实现了细粒度上下文信息的有效利用。
本文介绍了一种新的跨媒体细粒度关联学习方法,该方法支持五种媒体类型的数据交叉检索,通过跨媒体循环神经网络和联合关联损失函数解决了“异构鸿沟”问题,实现了细粒度上下文信息的有效利用。
最近在看彭宇新教授团队关于信息检索的论文,做个简单的总结。
题目:跨媒体深层细粒度关联学习方法
作者: 卓昀侃, 綦金玮, 彭宇新
年份:2019
现有问题:“异构鸿沟”问题导致不同媒体的数据表征不一致,难以直接进行相似性度量,因此,多种媒体之间的交叉检索面临着巨大挑战;现有技术仅考虑图像文本两种媒体数据的成对关联,难以实现多种媒体的交叉检索。
现有技术:深度神经网络模型具有 非线性建模能力。
本文提出:跨媒体深度细粒度关联学习方法,可支持5种媒体类型数据交叉检索。
方法结构:5种媒体的跨媒体循环神经网络+基于分布对齐和语义对齐的跨媒体联合关联损失函数
跨媒体交叉检索的现有解决思路:建立一个子空间,将不同媒体类型的异构数据映射至这一子空间,获取统一表征-->距离度量方法,计算不同媒体数据之间的相似性-->实现跨媒体交叉检索
现有文献的改进方向及存在问题:学习统一表征:CCA,语义类别信息,对应自编码器(Corr-AE),层次化网络联合学习----------只考虑成对关联,忽略细粒度信息之间的语义关联;仅使用语义类别信息约束关联学习,约束能力不足弥补数据分布差异。
细粒度:描述同一语义的不同媒体类型数据存在天然的语义一致性,且数据内部蕴含着丰富的细粒度上下文信息。细粒度指的是数据的局部区域或片段,上下文指的是这些区域或片段间的关联关系,如图像前景区域和背景图像区域之间的关系或前后视频帧之间的关系,充分利用细粒度上下文信息能够有效挖掘不同媒体数据之间的关联。
相关工作:
- 针对两种媒体的跨媒体检索方法:传统方法:CCA;KCCA;CFA;深度网络:DCCA;Corr-AE;Deep-SM;CMDN;CCL;CHTN;对抗式学习也被应用在跨媒体检索中。
- 针对多种媒体的跨媒体检索方法:JRL;跨媒体关联超图。--------只考虑线性映射
本文方法框架:
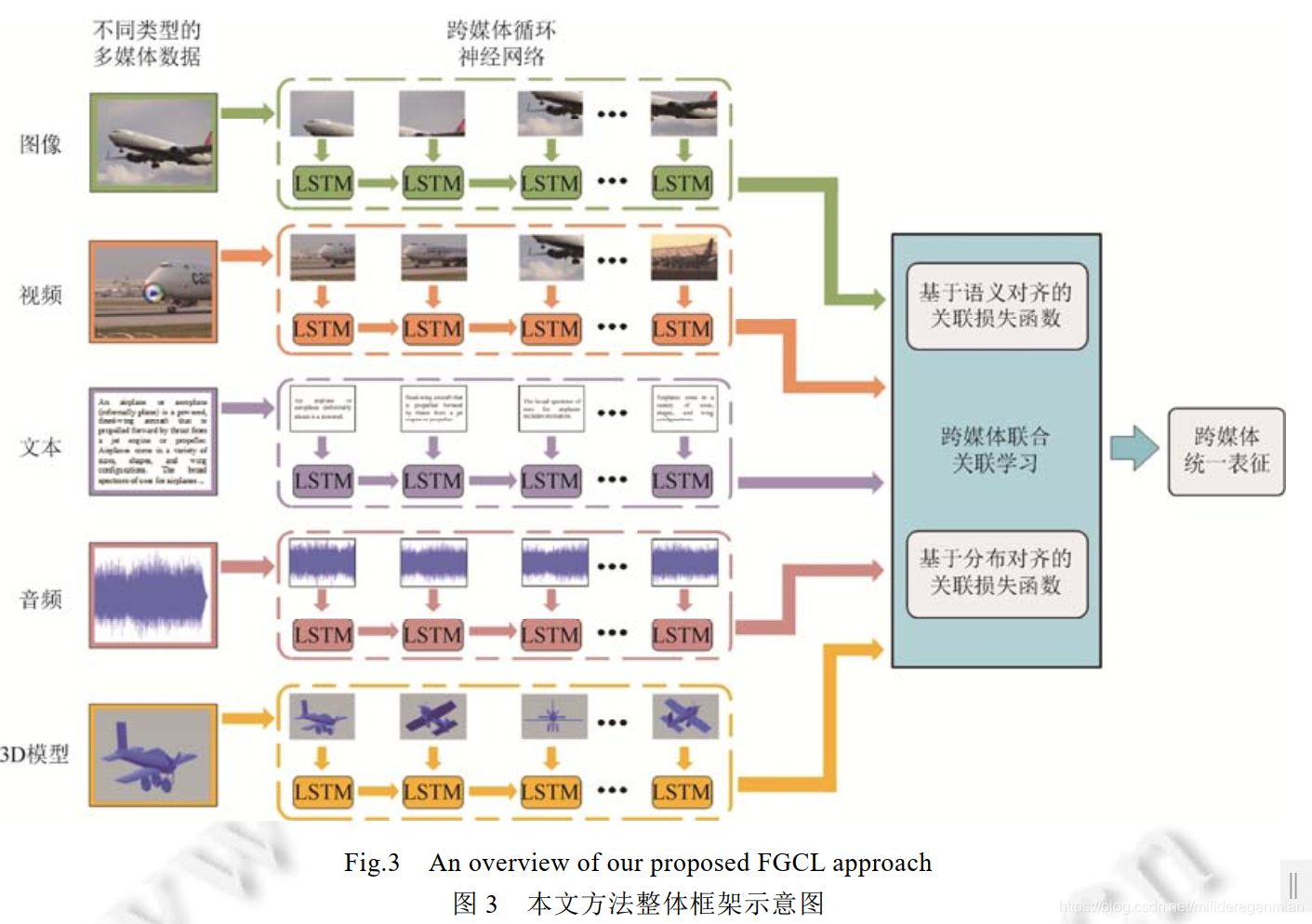
跨媒体循环神经网络:将每种媒体类型数据的局部区域或片段的序列输入到循环神经网络来学习细粒度特征表示。
(补充:分割数据并获取细粒度特征序列的具体策略:图像--缩放后输入VGG-19卷积神经网络,通过池化层提取49个不同区域的局部特征,肉眼看到的作为顺序;文本--按照段落或语句切分成片段,利用文本卷积神经网络提取特征,按照片段本身排序;音频--按固定时间间隔切片每片段提取MFCC特征形成序列;视频--提取VGG-19网络全连接层图像特征,按时间顺序排序;3D模型--对每个角度提取特征,并按[38]排序。上述均可采取不同特征选择方式。)
将5种媒体类型数据的特征按照序列逐步输入到LSTM网络中,并根据如下公式更新网络:
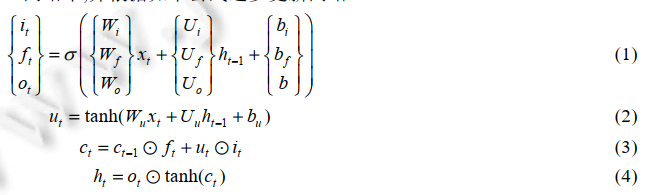
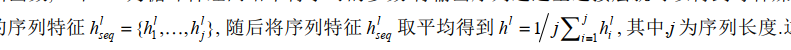
跨媒体联合关联学习:
基于语义对齐的关联损失函数。上述将得到不同媒体类型的数据表征h'通过全连接网络映射到统一的语义空间中,并采用如下的损失函数来约束不同媒体类型数据之间的语义关联:
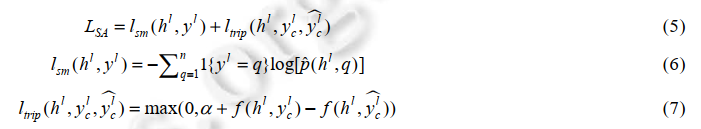

由于类别标签通过Word2Vec模型来映射,其映射后的特征向量本身带有语义信息。因此通过基于语义对其的关联损失函数,能够有效地增强统一表征的语义辨识能力,促进细粒度的跨媒体关联挖掘。
基于分布对齐的关联损失函数。采用最大均值差异MMD损失函数来优化不同媒体类型数据之间的分布差异。MMD是衡量两个数据分布差异的重要标准,其原理就是寻找样本空间中的连续函数,使不同分布的样本在该函数上均值查最大,得到MMD后,最小化MMD减少差异,达到对齐分布的效果。基于分布对齐的关联损失函数:
![]()
任意两种媒体类型数据之间的MMD损失函数定义如下:
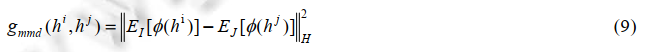
MMD损失函数是再生希尔伯特空间RKHS的平方形式。最小化上式可减少这两种数据之间的分布差异,达到对其的目的。
综上,基于语义对齐和分布对齐的跨媒体联合关联损失函数定义如下:
![]()
最小化上述损失函数。
数据集:http://www.icst.pku.edu.cn/mipl/XMedia。PKU XMediaNet数据集是目前国际上最大的包含5种媒体类型的跨媒体数据集,共包含超过10万个数据样本,其规模是XMedia的10倍。
代码:https://github.com/PKU-ICSTMIPL
评价指标与对比方法:
5种媒体交叉检索:将任意一种媒体类型的查询样例作为输入,检索所有5种媒体类型数据中与之于一相关的结果。
采用平均准确率均值MAP作为评价指标,与另外3种支持5种媒体场景或可以扩展至5种媒体场景的现有方法进行了实验对比:JRL(传统)、S2UPG(传统)、Deep-SM(深度)。
两种媒体互相检索:采用MAP,比较了6种传统跨媒体检索方法--CCA、CFA、KCCA、JRL、S2UPG、LGCFL,6种基于深度学习的跨媒体检索方法--Corr-AE、DCCA、Deep-SM、CMDN、CCL、ACMR。
基线实验对比:去掉三元组损失--去掉语义对齐关联损失函数or去掉MMD损失--去掉分布对齐关联损失函数。
均体现出优越性。
下一步工作:在不同尺度上挖掘跨媒体数据之间的关联关系,同时同分利用无标注数据并结合外部知识库进一步提升跨媒体检索的准确率。
学习所用,禁止转载,转载请附原文链接!

















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









