







用交叉验证判定误差
在过拟合与正则化这一章中,我们曾经提到过三种拟合状态的一些概念:
我们把图1这种状态称为欠拟合,欠拟合代表当前的假设函数对于数据的拟合状态欠佳,并不太适合,专业术语称为高偏差(high bias),偏差(bias)指的是算法的期望预测与真实结果的偏离程度。
图2的偏差较小,并且对于还未加入训练集的其他样本,也能和我们当前的模型相符。我们把这种能力称为:泛化,指的是当前的算法对于其他未加入的样本依然具有适用性。
图3的状态称为过拟合,意思就是它对数据的拟合程度已经过头了,不具有泛化性。我们可以称其为具有高方差(high variance),方差(variance)指同样大小训练集的变动而导致的学习性能的变化。
多项式次数与误差
在上一节中,我们学习了用训练误差来评估模型的方法,现在我们试着用新知识再回看这个图像,
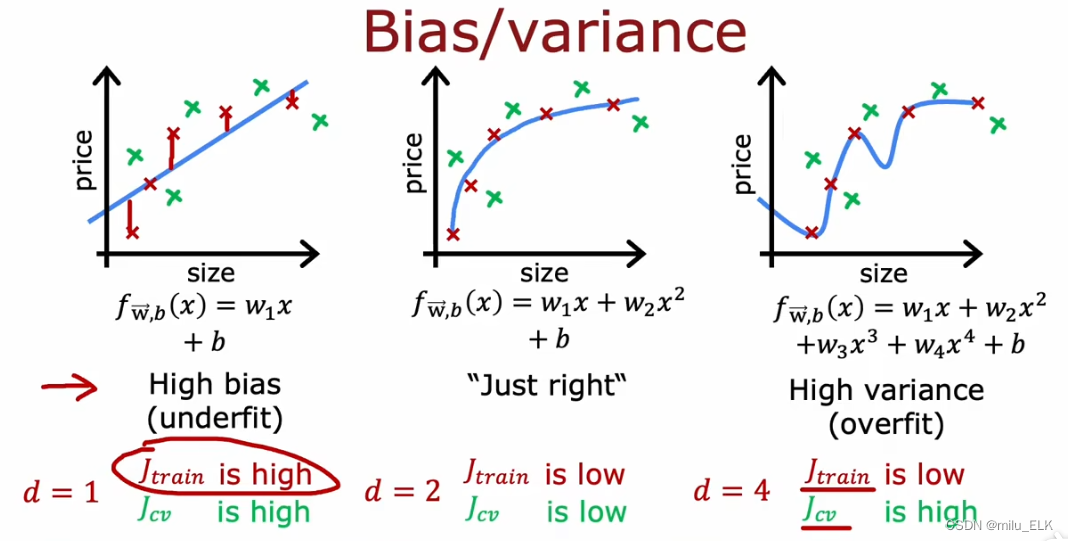
图1是欠拟合状态,我们可以看到这个图像和训练集以及交叉验证集的拟合状态都差,因此训练误差高,验证误差高,当训练误差高就代表了假设函数具有高偏差。
图3是过拟合状态,我们可以看到在这个图像上训练集的拟合状态较好,但交叉验证集的拟合状态差,因此训练误差低,验证误差高,当验证误差远大于训练误差就代表了假设函数具有高方差。
图2是一个适当的拟合状态,训练误差低,验证误差也低,这就代表了假设函数的拟合状态好。因此我们会选择图2进行拟合
从另一个角度看,虽然多个特征的拟合图像我们难以画出来,但是我们可以通过对模型的误差评估来判断当前的拟合函数是否恰当。此外,上面三个图像也代表了不同次数的多项次函数之间的拟合关系,当多项次次数越小,越容易欠拟合,反之次数越大,越容易过拟合,
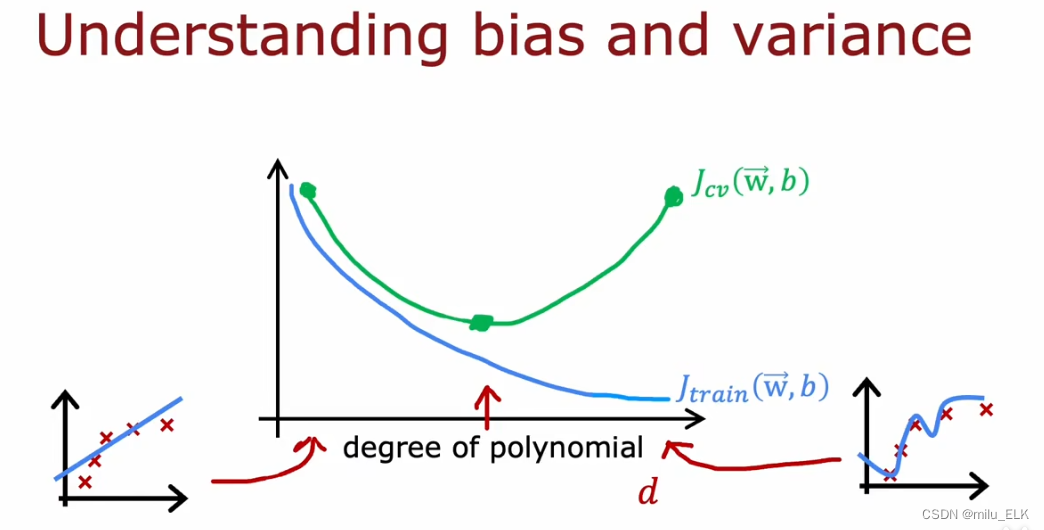
验证误差和训练误差与多项式次数d的函数关系如图所示,
当次数d越大,训练误差
J
t
r
a
i
n
J_{train}
Jtrain越小,这是因为多项次次数越多,越能逼近曲线
当次数d过小或者过大,都会导数验证误差
J
c
v
J_{cv}
Jcv过大,在中间某点处
J
c
v
J_{cv}
Jcv能取到最小值,我们要找的就是中间这个点。
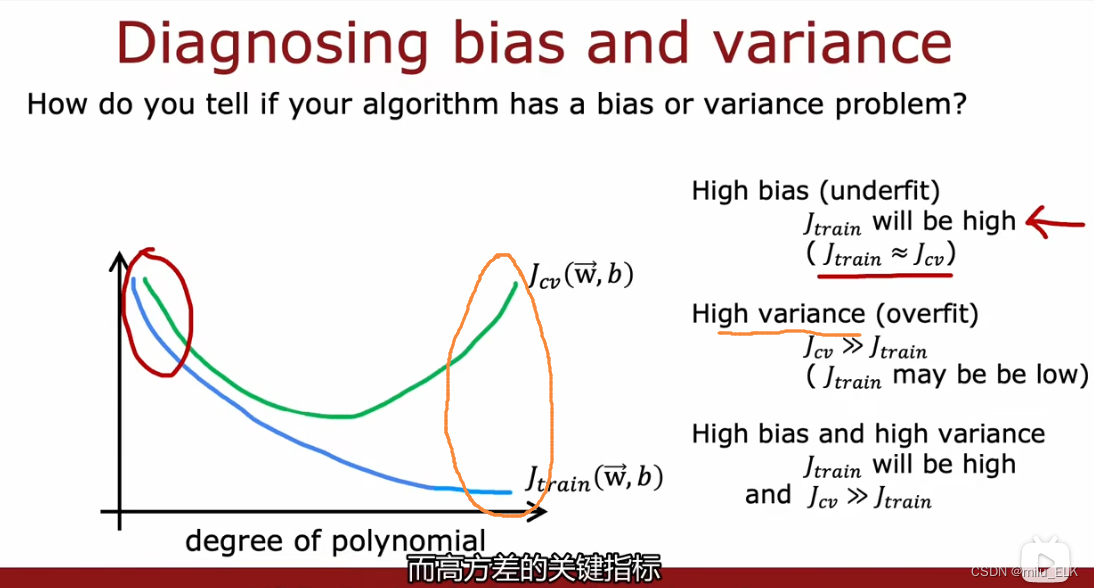 我们总结一下:
我们总结一下:
- 当训练误差 J t r a i n J_{train} Jtrain过高,意味着高偏差,欠拟合,说明拟合函数在训练集上表现不好
- 当验证误差 J c v J_{cv} Jcv远大于 J t r a i n J_{train} Jtrain,意味着高方差,过拟合,说明拟合函数在交叉验证集上表现不好
- 当训练误差 J t r a i n J_{train} Jtrain高且验证误差 J c v J_{cv} Jcv远大于 J t r a i n J_{train} Jtrain,意味着高偏差,高方差,说明拟合函数在两个集合上表现都不好
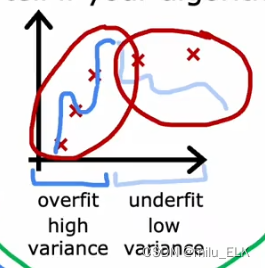
高偏差,高方差在线性方程中不容易出现,然而在神经网络中可能也经常会出现这种情况,这意味着模型在训练集上的训练效果不好,而且在交叉验证集上更差!也就是你的函数既欠拟合,又过拟合。比如下图这种情况。
虽然高误差让人悲伤,但是通过搞清楚这个误差有多高可以有效地帮助我们改进算法。
正则化参数与误差
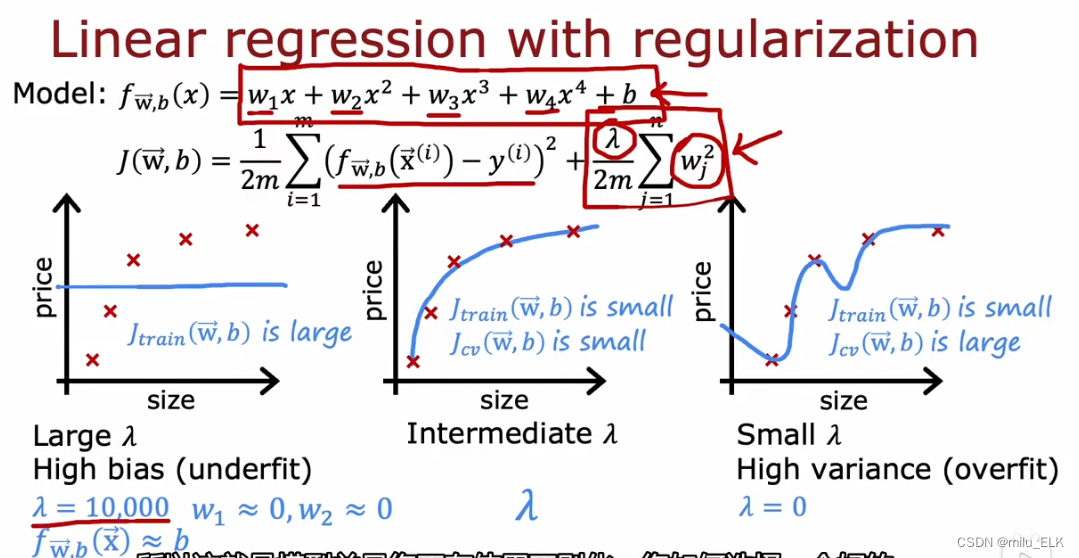 基于误差的性质,对于使用了正则化的代价函数,我们应当如何选择合适的正则化参数?
基于误差的性质,对于使用了正则化的代价函数,我们应当如何选择合适的正则化参数?
当正则化系数过大时,此时参数w会近似于0,那么拟合函数就类似线性函数,此时是欠拟合状态,训练误差 J t r a i n J_{train} Jtrain大,高偏差
当正则化系数过小时,多项式拟合又会呈现出过拟合的性质,此时训练误差 J t r a i n J_{train} Jtrain小,但验证误差 J c v J_{cv} Jcv大,因此方差。
和选择多项次次数d的时候同理,我们要选择合适的λ才能有低训练误差,低验证误差,使得拟合状态好。

我们之前在正则化那一章的时候就提到了,想要选取合适的正则化参数的方法很简单,就是算,我们从小到大,从欠拟合到过拟合,逐渐倍乘正则化参数λ,从中选择出最适合的正则化参数和系数参数
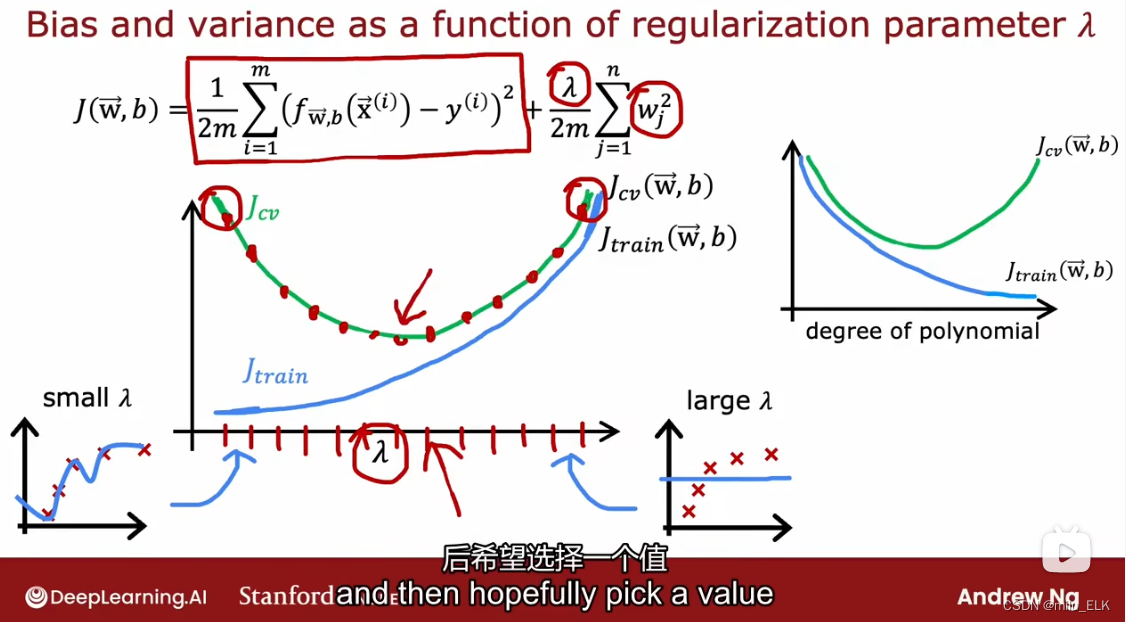
我们可以得到正则化参数与误差的关系图像(图左),有意思的是,这个图像与多项式次数d与误差的关系图像从形状上来看是对称的,这是由于λ小则过拟合,λ大则欠拟合,多项式次数d则正好相反。我们所作的,就是经过多次尝试来找到这个最适宜的λ参数。
性能基准

语音识别已经是一个比较普及的技术了,我们以语音识别系统为例。通过我们之前的讲解,我们知道训练误差越小在训练集上拟合效果越好,想要恰当的拟合需要低训练误差和低验证误差,在上图的语音识别系统中,训练误差有10.8%,也许你会觉得10.8%是一个很差的数字,但是如果我们横向对比擅长演讲的人类在语音识别上的误差就会发现——人类的误差竟然也有10.6%。也就是说该系统的训练误差已经接近人类的水准。这是由于我们在转录语音的时候,某些样本中总是有影响识别的噪音,因此即使让人类来识别也存在着10.6%的误差。所以该系统在训练集上已经做的很好了。问题在于验证误差有14.8%,远大于训练误差,这说明该模型是高方差,过拟合的。
 想要评估一个系统的性能,并不是通过直接观察误差,我们是希望误差越小越好,但是误差并不是不可接受的,即使人类的智能来进行识别也会有误差。
想要评估一个系统的性能,并不是通过直接观察误差,我们是希望误差越小越好,但是误差并不是不可接受的,即使人类的智能来进行识别也会有误差。
那么怎样来确定性能基准?人类在识别语音、文字、图像上有很高的性能,在非结构化的数据中我们往往将人类的误差作为性能基准,如果一个系统能尽可能地接近人类的误差基准,那么我们就可以认为是低误差的。
如果使用了结构化的数据,也许计算机的性能会更好,因此我们也可以比较其他人的算法表现,如果在同一个问题上,你的误差比别人的误差要大,说明了你的算法性能是比较差的。
或者也可以通过经验来确定基准,也许你曾经做过类似的算法,因此在性能基准的确定上就有经验。
 通过比较性能基准,我们可以确定训练误差和验证误差是否过大,通常来讲相差零点几都是较小的,但是如果超过了2%应该就可以认为是“远大于”了。
通过比较性能基准,我们可以确定训练误差和验证误差是否过大,通常来讲相差零点几都是较小的,但是如果超过了2%应该就可以认为是“远大于”了。
学习曲线
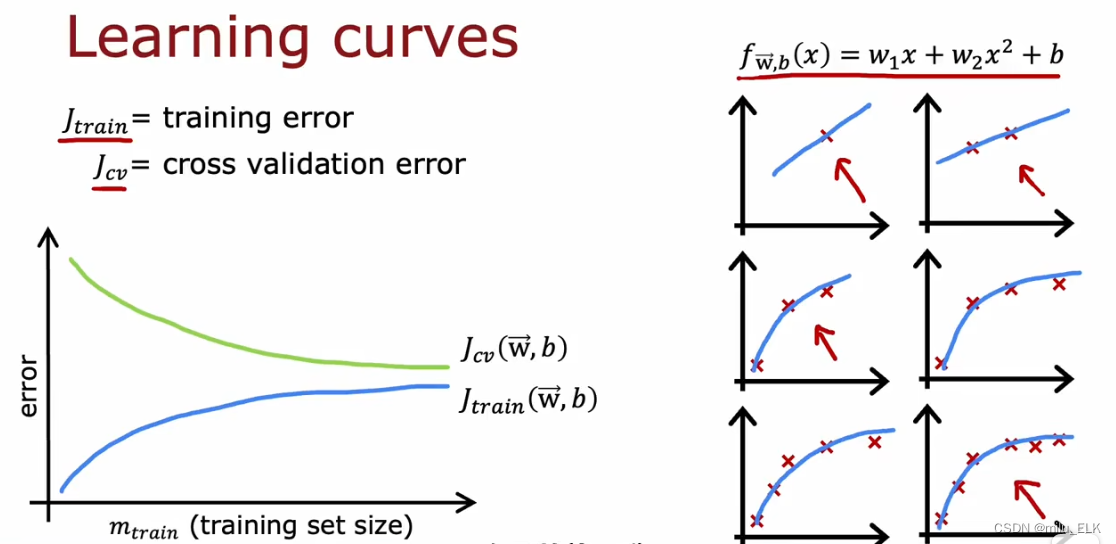
在拟合过程中,学习曲线可以帮助我们来理解误差的变化,以上图为例,假设我们确定的拟合函数是一个二次函数,如上图所示,我们可以绘制一个以训练集样本数量为横轴,误差大小为纵轴的图像。在训练集上,如果样本数量较少的时候,我们的训练误差是较小的,但是由于样本数量过少,因此我们的拟合函数实际上并未具有泛化性,我们通常都会增加样本数量,因此我们可以在图中看到,随着样本的增加,训练误差
J
t
r
a
i
n
J_{train}
Jtrain实际上是越来越大的,在拟合适当的情况下这并不代表拟合效果变差,恰恰相反,这说明了训练误差越来越接近泛化误差,更直观一点我们可以找到性能基准来比较误差大小。而与此对应的,验证误差
J
c
v
J_{cv}
Jcv会越来越小。二者都随着样本数量增加趋于平坦。
在右图中我们可以看到,随着样本数量的增加,二次函数也越来越难以拟合,因此训练误差也会越来越高。并且验证误差往往要高于训练误差,这是因为拟合函数是在训练集上训练的,验证误差自然就会比训练误差高。
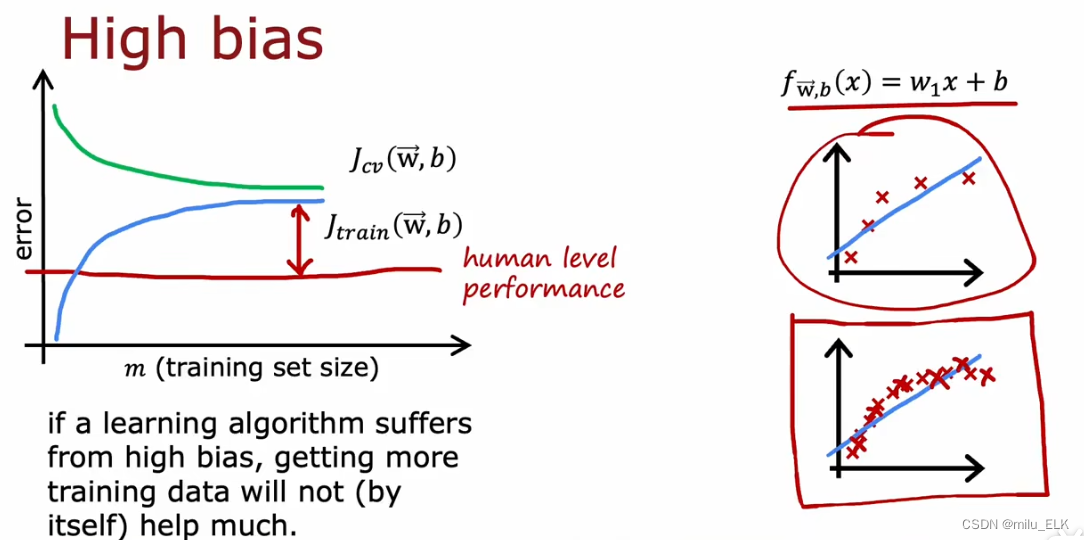
高方差往往代表了欠拟合,假设我们以线性函数来进行拟合,如右图所示,那么随着样本的增加,拟合效果只会越来越差。
左边的图像中显示了误差与样本数量的关系,在形状上看与之前那张图很类似,但是我们比较人类的性能基准发现,随着样本数量的增加,训练误差远远高于了性能基准,说明了当前的拟合函数是高偏差,欠拟合的。说明我们目前的模型是不适合的。即使我们增加样本数量,误差也只会保持平坦。
由于拟合函数本身选择就有问题,在高偏差时增加样本数量显然是没用的。

同样的,假设用一个足够多次数的多项式来拟合,那么图像如图所示,图像依旧呈现这个形状。不过由于我们的性能基准与其相近,因此当训练样本较少时,会呈现出高验证误差,低训练误差的性质,此时由于验证误差远远高于训练误差,因此是高方差的,不过训练误差小于性能基准,因此是过拟合的。
随着样本数量的增加,这个复杂函数的拟合效果会变得越来越好,因此,训练误差会上升,逐渐接近性能基准,而验证误差也会下降并逐渐接近基准。因此在高方差的情况下,增加训练样本是很有帮助的。
综上所述,结合学习曲线的图像,我们发现简单,低次数的拟合函数,越容易导致高偏差,增加训练样本是无法解决问题的。
而复杂,高次数的拟合函数,容易导致高方差,增加训练样本数量则可以有效解决这个问题。
对模型绘制学习曲线也是我们判断误差的一个技巧。
作出选择

还记得我们在上一章的开头抛出的这个问题吗?面对这六种方案,我希望你能先自己思考一下它们的答案,再对照标准答案。
其实我们有一种简单的思考方式:我们知道欠拟合的特点就是高偏差,过拟合的特点是高方差。我们的目的是要让拟合函数更just fit,欠拟合代表着函数的复杂程度有限,多项式次数过小,因此拟合程度也有限;过拟合代表拟合程度过高,函数过于复杂,多项式次数过高。带着这样的思考我们再来看看上述六种情况,我们可以通过判断函数是否变得复杂了来判定是用于拟合什么情况下的误差。
- 获得更多训练样本:刚才在讲学习曲线的时候其实也提到了,当训练样本很少的时候,函数的拟合状态是较好的,因为样本少,拟合几个点相对简单,但是这也意味着函数不一定具有泛化性,会出现过拟合的情况,当我们增加足够多的训练样本,那么拟合函数的训练误差将会更加接近泛化误差,也就是由过拟合变为拟合,因此是解决高方差。
- 尝试更少的特征集:减少特征意味着多项式次数变小,代表拟合函数的复杂程度变低,因此我们常常是想放在过拟合的函数上,复杂程度变低更接近拟合函数,因此是解决高方差
- 获取更多特征:与上面情况相反,增加特征会导致多项式次数变多,函数变复杂,我们会在欠拟合的时候使用,因此是解决高偏差
- 增加额外特征:同理,增加额外特征项,函数变复杂,用于解决欠拟合,因此是解决高偏差
- 减小正则化参数λ:减小λ意味着参数系数的影响变小,因此在代价函数计算最小化参数时,算出的参数就会变大,函数复杂程度上升,就可以解决欠拟合的情况,因此用于解决高偏差
- 增加正则化参数λ:增大λ意味着参数系数的影响变大,因此在代价函数计算最小化参数时,算出的参数就会变小,函数复杂程度下降,就可以解决过拟合的情况,因此用于解决高方差
方差和偏差

因此,我们会发现,误差和多项式次数d 的关系如上图所示:
当多项式次数小,函数较简单时,往往会导致欠拟合,高偏差
当多项式次数大,函数较复杂时,往往会导致过拟合,高方差
我们需要在过高和过低的次数之间,高方差和高偏差之间作出权衡(trade off,我发现计算机专业都很喜欢这个词),来选择出合适的函数。
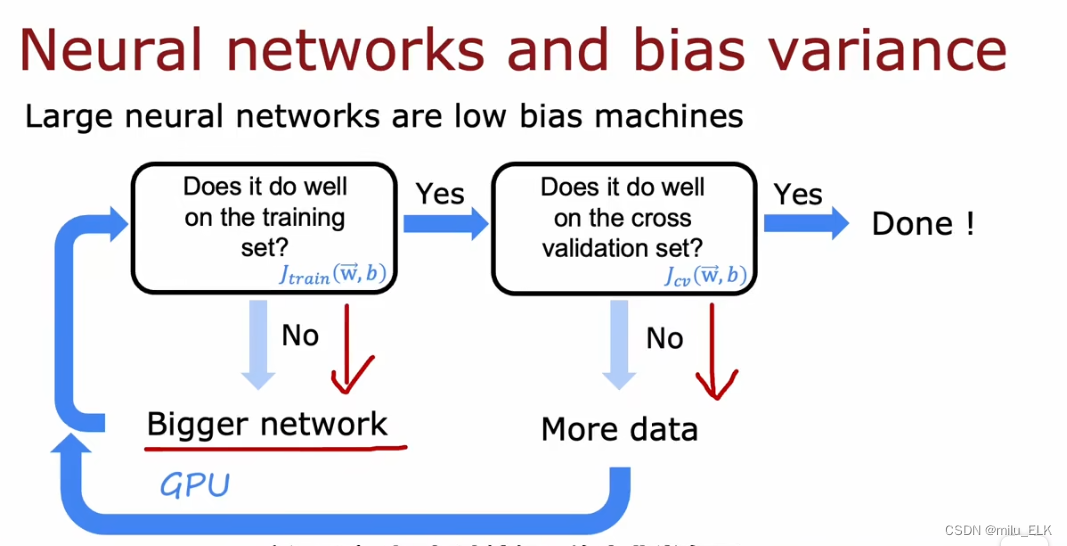
然而其实在实际情况中,我们发现,越是复杂的神经网络,面对中小型的数据(也就是函数复杂,数据量少的情况),表现出的特征往往是低偏差的(这是因为函数足够复杂,数据够少,所以训练误差
J
t
r
a
i
n
J_{train}
Jtrain就很小)。然而这并不能保证也有低方差(训练误差小不代表接近泛化误差,也可能造成过拟合),因此我们给出了上面的流程图:
首先,判断训练效果是否好?对于一个使用了有限大小数据量的训练集,其标准就是看训练误差 J t r a i n J_{train} Jtrain是否过大,如果 J t r a i n J_{train} Jtrain过大,代表高偏差,训练效果不好。因此,我们需要一个更大的神经网络,让整个神经网络更复杂。循环判断直到训练误差 J t r a i n J_{train} Jtrain变得恰当为止。
接下来,我们再判断验证误差 J c v J_{cv} Jcv是否过大,如果过大,远大于训练误差 J t r a i n J_{train} Jtrain,代表高方差,说明我们过拟合了,我们讲过增加数据量可以解决高方差,因此我们重复增加数据量,直到测试误差 J c v J_{cv} Jcv也适当,如果二者都可行了,说明我们的模型是恰当的。
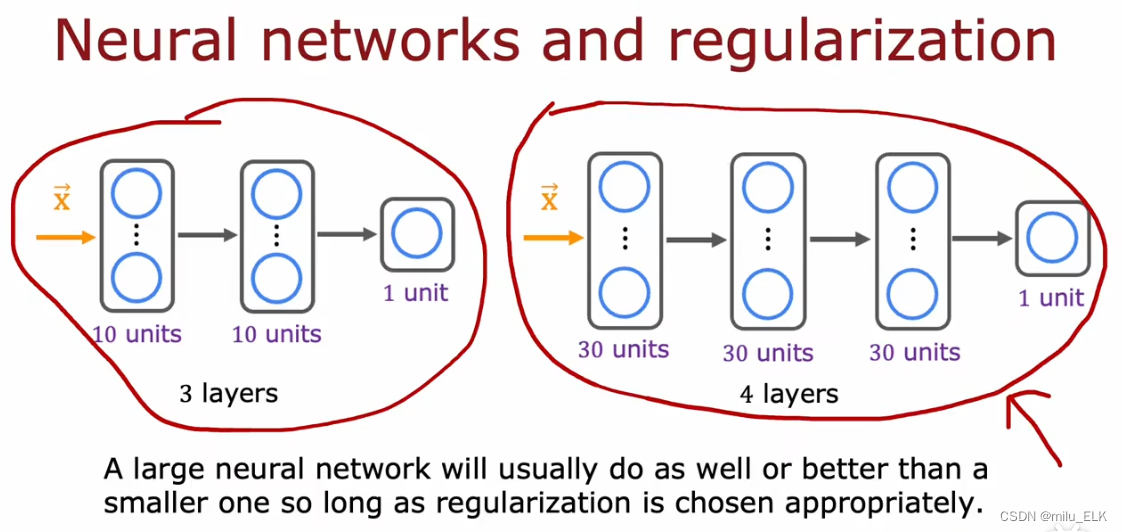 那么刚才那个图是不是和我们得到的结论相反了呢?我们说拟合函数越复杂,那么越是容易高方差,如果要解决高偏差需要更复杂的神经网络,是不是意味着它也会带来高方差的问题?
那么刚才那个图是不是和我们得到的结论相反了呢?我们说拟合函数越复杂,那么越是容易高方差,如果要解决高偏差需要更复杂的神经网络,是不是意味着它也会带来高方差的问题?
答案是否定的:因为我们可以解决高方差,我们之前也提到了
- 增加正则化参数λ:增大λ意味着参数系数的影响变大,因此在代价函数计算最小化参数时,算出的参数就会变小,函数复杂程度下降,就可以解决过拟合的情况,因此用于解决高方差
事实证明,在更加复杂的神经网络中,只要我们合理地选择神经元的正则化参数λ,就不会因为结构变复杂而导致高方差,并且结构更复杂还帮我们解决了高偏差的问题,因此,像上图中的两个模型,只要选择了合适的正则化参数,那么更复杂的神经网络将会比小型的简单的神经网络做得更好!
唯一的缺点在于,整个流程需要更复杂的神经网络和更大的数据量,也就意味着更长的计算时间,如果计算速度过慢是无法使用的,因此需要随着计算速度的发展而发展。不过好在近几年硬件发展、大数据技术发展十分迅速,因此AI才能在这几年异军突起。在现在这个时代,我们更推崇复杂的神经网络来作为训练模型。
总结
本章概念较多,主要是方差偏差与训练误差,验证误差的关系,与过拟合欠拟合的关系,注意梳理,融会贯通,就能较好地理解方差和偏差与拟合函数的关系















 892
892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









