







摘要: 分享对论文的理解, 原文见 Zhongping Zhang and Youzuo Lin, Data-driven seismic waveform inversion: A study on the robustness and generalization.
1. 论文贡献
- 提供实时预测的 VelocityGAN
- 与其他基于编码器-解码器的数据驱动地震波形反演方法不同, VelocityGAN 从数据中学习正则化, 并进一步将正则化应用于生成器, 从而提高反演精度.
- 进一步使用迁移学习, 缓解泛化性问题.
2. 相关工作

图 1 展示了全波形反演的基本框架, 本质上就是端到端: 地震数据到速度模型.
2.1 声波反演: 物理驱动方法
正演模型为
P
=
f
(
m
)
(1)
P = f(\mathbf{m}) \tag{1}
P=f(m)(1)
其中
m
\mathbf{m}
m 为速度模型参数 (一个向量),
f
f
f 为正演模型算子 (一个函数),
P
P
P 是声学情况下的压力波场.
正则化的物理驱动地震反演为
E
(
m
)
=
min
m
{
∥
d
−
f
(
m
)
∥
2
2
+
λ
R
(
m
)
}
(2)
E(\mathbf{m}) = \min_{\mathbf{m}} \{\|\mathbf{d} - f(\mathbf{m})\|_2^2 + \lambda R(\mathbf{m})\} \tag{2}
E(m)=mmin{∥d−f(m)∥22+λR(m)}(2)
其中
d
\mathbf{d}
d 是实测的数据,
∥
⋅
∥
2
\| \cdot \|_2
∥⋅∥2 是 2 范数, 相应部分表示数据匹配误差,
λ
\lambda
λ 为一个系数,
R
(
m
)
R(\mathbf{m})
R(m) 是由参数导致的正则项, 用于避免模型太复杂 (过拟合).
这种方法的特点:
- 不需要其它数据的支持. 本质上, 输入只有 d \mathbf{d} d;
- 需要进行不断迭代求解. 预先猜一个模型 m \mathbf{m} m 根据式 (3) 计算损失, 再根据该损失进行 m \mathbf{m} m 的调整;
- 效率比较低 (与上一条有关);
- 依赖于初始猜测的模型, 即 m \mathbf{m} m 的最初版本. 如果数据没有噪声, 可以获得非常好的效果. 否则会陷入局部最优解, 无法进行良好的拟合.
2.2 数据驱动: 学习反演算子
m
=
g
(
d
)
=
f
−
1
(
d
)
(4)
\mathbf{m} = g(\mathbf{d}) = f^{-1}(\mathbf{d}) \tag{4}
m=g(d)=f−1(d)(4)
其中
g
g
g 就是需要学习的反演算子.
g
=
arg min
g
{
∑
i
=
1
N
∥
m
i
−
g
(
d
i
)
∥
2
2
}
(5)
g = \argmin_g \left\{\sum_{i=1}^N \|\mathbf{m}_i - g(\mathbf{d}_i)\|_2^2\right\}\tag{5}
g=gargmin{i=1∑N∥mi−g(di)∥22}(5)
其中
{
d
i
,
m
i
}
i
=
1
N
\{\mathbf{d}_i, \mathbf{m}_i\}_{i=1}^N
{di,mi}i=1N 为训练数据.
2.3 方法比较
| 物理方法 | 数据驱动方法 | |
|---|---|---|
| 数据 | 不需要其它数据的支持. 本质上, 输入只有 d \mathbf{d} d | 需要训练数据 { d i , m i } i = 1 N \{\mathbf{d}_i, \mathbf{m}_i\}_{i=1}^N {di,mi}i=1N |
| 训练 | 针对当前数据的求解, 没有训练 | 大量训练时间, 效果与训练样本强相关 |
| 求解 | 需要进行不断迭代求解. 预先猜一个模型 m \mathbf{m} m 根据式 (3) 计算损失, 再根据该损失进行 m \mathbf{m} m 的调整 | 使用 g g g 直接求解 |
| 效率 | 针对当前数据求解慢 | 训练慢, 但测试效率高 |
| 依赖 | 依赖于初始猜测的模型, 即 m \mathbf{m} m 的最初版本. 如果数据没有噪声, 可以获得非常好的效果. 否则会陷入局部最优解, 无法进行良好的拟合 | 训练数据质量 |
3. 论文工作
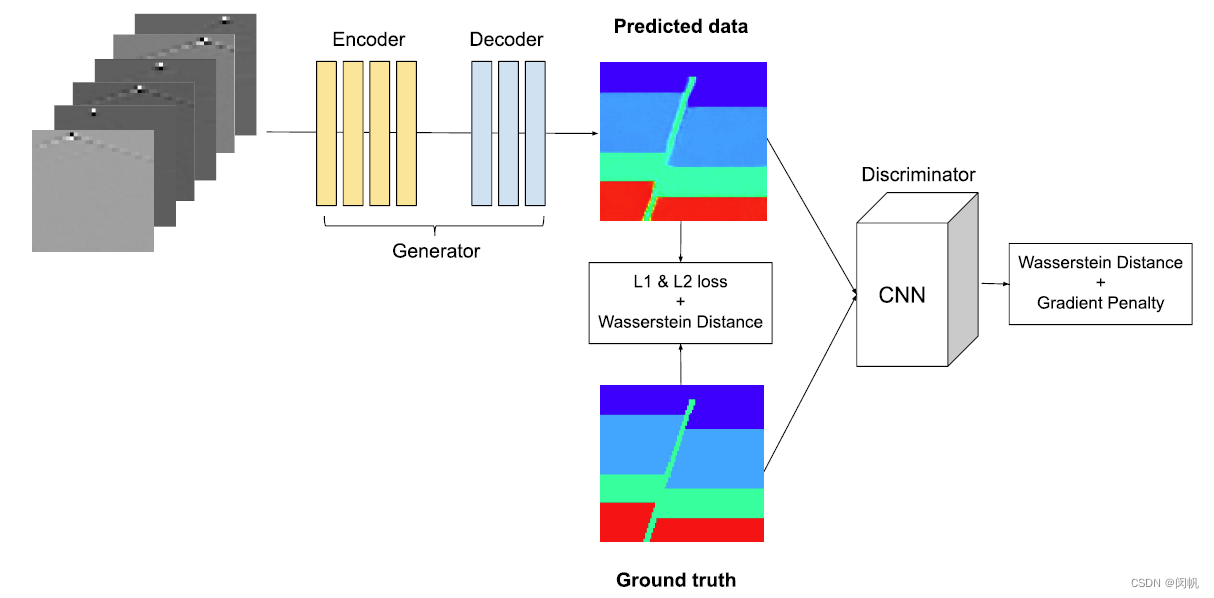
3.1 生成器
- 输入数据为一个
32
×
1000
×
6
32 \times 1000 \times 6
32×1000×6 的张量
- 32 个接收器
- 1000 个时间点
- 3 个源函数 (从后文来说是 3 shots, 即相同位置放了 3 炮) 和 2 个通道 ( 3 × 2 = 6 3 \times 2 = 6 3×2=6)
- 标签为速度模型
- 大小为 m × n m \times n m×n, m m m 表示深度, n n n 表示水平距离
- 相邻点的距离为 5 5 5 m, 因此总的尺寸为 5 m × 5 n m 2 5m \times 5n \textrm{ m}^2 5m×5n m2
- 矩阵每个点的值表示声波的传播速度
- 网络细节
- 输入数据与标签之间, 并不存在空间的对应关系, 因此不会像平常的 U-Net 那样对它们的差异进行惩罚
- 使用多个 k × 1 k \times 1 k×1 卷积统一到 32 × 32 32 \times 32 32×32
- 对 32 × 32 32 \times 32 32×32 的数据使用 3 × 3 3 \times 3 3×3 的卷积核, 直到获得 8 × 8 8 \times 8 8×8 的数据
- 最后使用 8 × 8 8 \times 8 8×8 的卷积核, 消除空间信息 (太狠了吧)
- 解码的时候, 逐步获得与速度模型相同大小 ( m × n m \times n m×n)
3.2 判别器
- 注重局部信息, 因此使用 patchCNN 而不是 GlobalCNN
小结
- 物理方法只在一个模型上迭代, 数据驱动方法从大量模型中学习, 所以会更容易跳出 (或者避免陷入) 局部最优解















 910
910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









