






网上有很多大佬为了帮助渣渣爬虫提升,都有搭建爬虫练习平台网站,这种网站的好处是可以练习爬取,同时网上也有很多参考教程,尤其适合学习练手使用。
爬虫练习网站,镀金的天空-GlidedSky,爬虫-基础1,爬取网页上的数据,计算求和。
爬虫-基础1
“爬虫的目标很简单,就是拿到想要的数据。这里有一个网站,里面有一些数字。把这些数字的总和,输入到答案框里面,即可通过本关。”
http://glidedsky.com/level/web/crawler-basic-1第一关还是比较简单的,数据的获取也有很多种方法和形式,这里本渣渣抛砖引玉,使用了正则获取数据,可惜网站本身的邮箱验证出错,获取到的计算答案无法验证,以及进入到下一关。
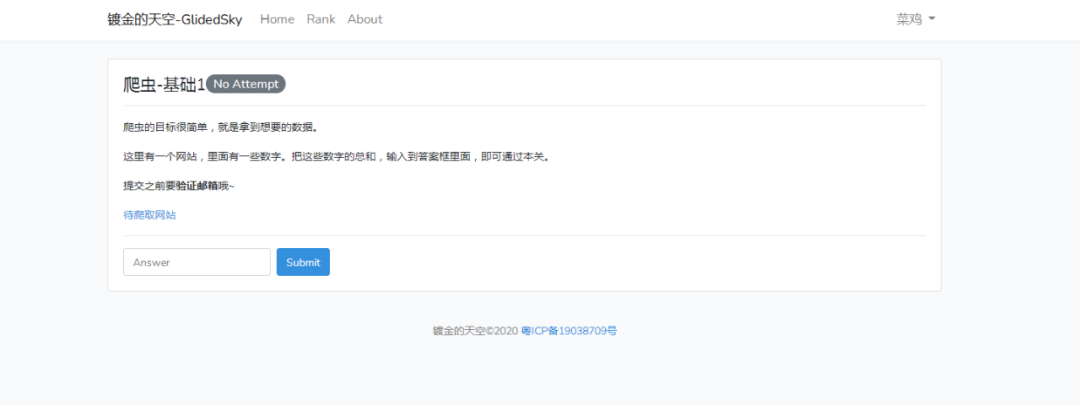
难道是本渣渣ip还是操作有问题?!

这里介绍了一下两种计算方法:
方法一
循环加
numbers=0
for div in divs:
numbers=numbers+int(div.strip())
print(numbers)方法二
sun 函数
numbers=[]
for div in divs:
number=int(div.strip())
#print(number)
numbers.append(number)
print(numbers)
num=sum(numbers)写的比较粗糙,仅供学习参考,如需完整源码,可关注本渣渣公众号

后台回复:“爬虫基础1”
获取完整源码
·················END·················
你好,我是二大爷,
革命老区外出进城务工人员,
互联网非早期非专业站长,
喜好python,写作,阅读,英语
不入流程序,自媒体,seo . . .
公众号不挣钱,交个网友。
读者交流群已建立,找到我备注 “交流”,即可获得加入我们~
听说点 “在看” 的都变得更好看呐~
关注关注二大爷呗~给你分享python,写作,阅读的内容噢~
扫一扫下方二维码即可关注我噢~

关注我的都变秃了
说错了,都变强了!
不信你试试

扫码关注最新动态
公众号ID:eryeji















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









