






前面本渣渣分享过 爬虫-基础1 - GlidedSky ,这篇就来分享 爬虫-基础2 ,希望对你有帮助吧,当然仅记录分享,为了更有帮助,这里升级了一下爬虫难度,采用了多线程。
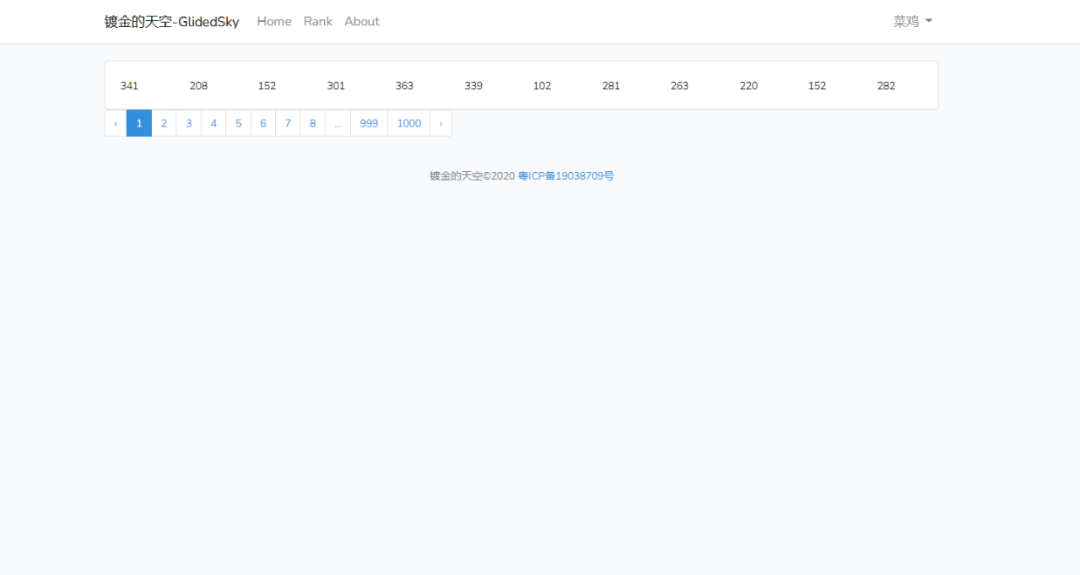
本身相对于基础1,基础2提升了一下难度,从单页爬取提升到分页爬取,分成了1000个页面,需要请求一千次,而网页结构没有变化,很典型的 Bootstrap 写的样式。
爬虫-基础2
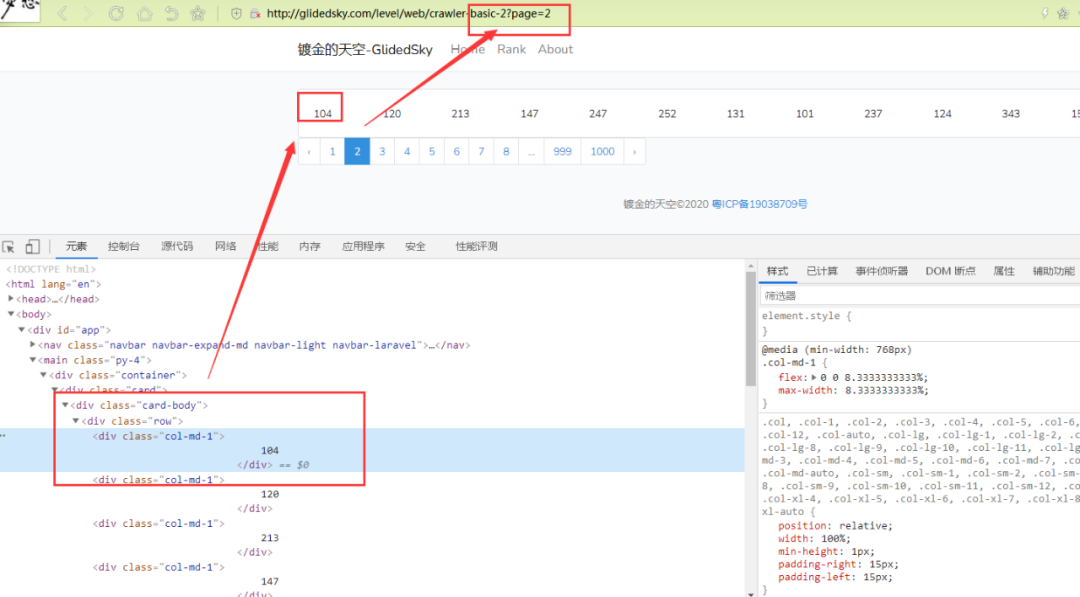
简单的分析一下页面,尤其是分页页面请求,可以很简单的得出请求规律,那就是 ?page=2 ,其中 2 页码,只需更换页码数,即可访问所有页面。
http://glidedsky.com/level/web/crawler-basic-2与第一篇爬取采用正则不同,这里使用本渣渣用的比较频繁的 lxml 库来获取数据,给出参考源码,供学习参考使用。
# -*- coding: utf-8 -*-
#爬虫-基础2 - GlidedSky @公众号:eryeji
#http://glidedsky.com/level/web/crawler-basic-2
# Cookie 需自行补充填写
import requests
from lxml import etree
Cookie=""
numbers=[]
for i in range(1,1001):
url=f"http://glidedsky.com/level/web/crawler-basic-2?page={i}"
print(f">> 正在爬取第{i}页..")
headers = {
"Cookie": Cookie,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
}
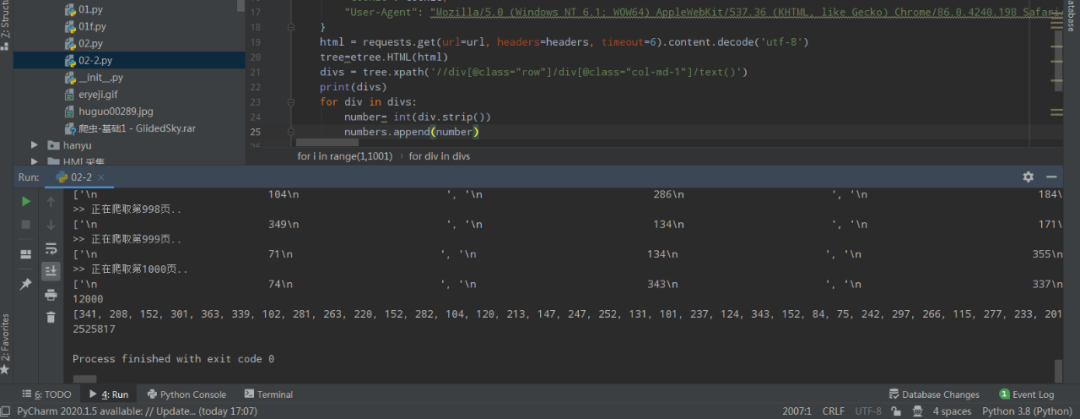
html = requests.get(url=url, headers=headers, timeout=6).content.decode('utf-8')
tree=etree.HTML(html)
divs = tree.xpath('//div[@class="row"]/div[@class="col-md-1"]/text()')
print(divs)
for div in divs:
number= int(div.strip())
numbers.append(number)
print(len(numbers))
print(numbers)
num=sum(numbers)
print(num)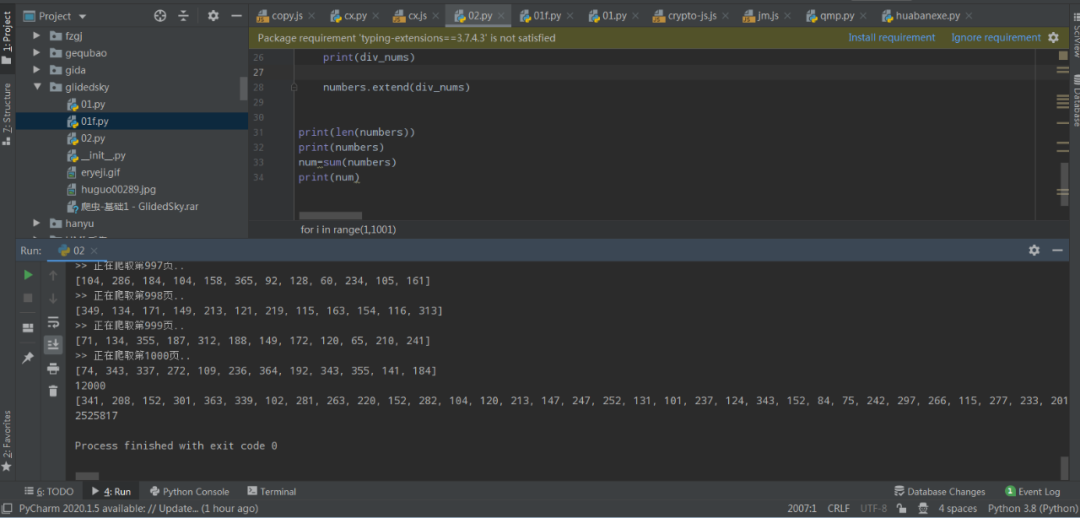
如果仅仅如此有什么意思呢,不妨可以尝试写一下多线程,异步爬取,来提升一下爬取效率,毕竟实例练手的机会也不是太多,这样才能做到举一反三!
这里给出一个多线程爬取示例做参考:
# -*- coding: utf-8 -*-
#多线程爬取
import requests
import re
import threading
url = 'http://www.glidedsky.com/level/web/crawler-basic-2'
total_threads = 10 # 设置线程数量
lock = threading.Lock() # 创建一个锁,用于线程间的数据同步
res = 0
Cookie=""
def worker(thread_id):
global res
for i in range(thread_id, 1001, total_threads):
temp_url = url + '?page=' + str(i)
print(f">> 开始爬取第{i}页..")
response = requests.get(temp_url, headers=headers)
html = response.text
pattern = re.compile('<div class="col-md-1">.*?(\d+).*?</div>', re.S)
n_list = re.findall(pattern, html)
with lock:
for n in n_list:
res += int(n)
threads = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36 Edg/89.0.774.54',
'Cookie': Cookie
}
# 创建并启动线程
for i in range(total_threads):
thread = threading.Thread(target=worker, args=(i,))
thread.start()
threads.append(thread)
# 等待所有线程执行完成
for thread in threads:
thread.join()
print(f'Result: {res}')更多多线程,异步爬取
参考完整源码
关注本渣渣公众号

后台回复“爬虫基础2”
·················END·················
你好,我是二大爷,
革命老区外出进城务工人员,
互联网非早期非专业站长,
喜好python,写作,阅读,英语
不入流程序,自媒体,seo . . .
公众号不挣钱,交个网友。
读者交流群已建立,找到我备注 “交流”,即可获得加入我们~
听说点 “在看” 的都变得更好看呐~
关注关注二大爷呗~给你分享python,写作,阅读的内容噢~
扫一扫下方二维码即可关注我噢~


关注我的都变秃了
说错了,都变强了!
不信你试试

扫码关注最新动态
公众号ID:eryeji















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









