







R-CNN
https://blog.csdn.net/briblue/article/details/82012575
https://www.jianshu.com/p/c1696c27abf8
R-CNN模型:
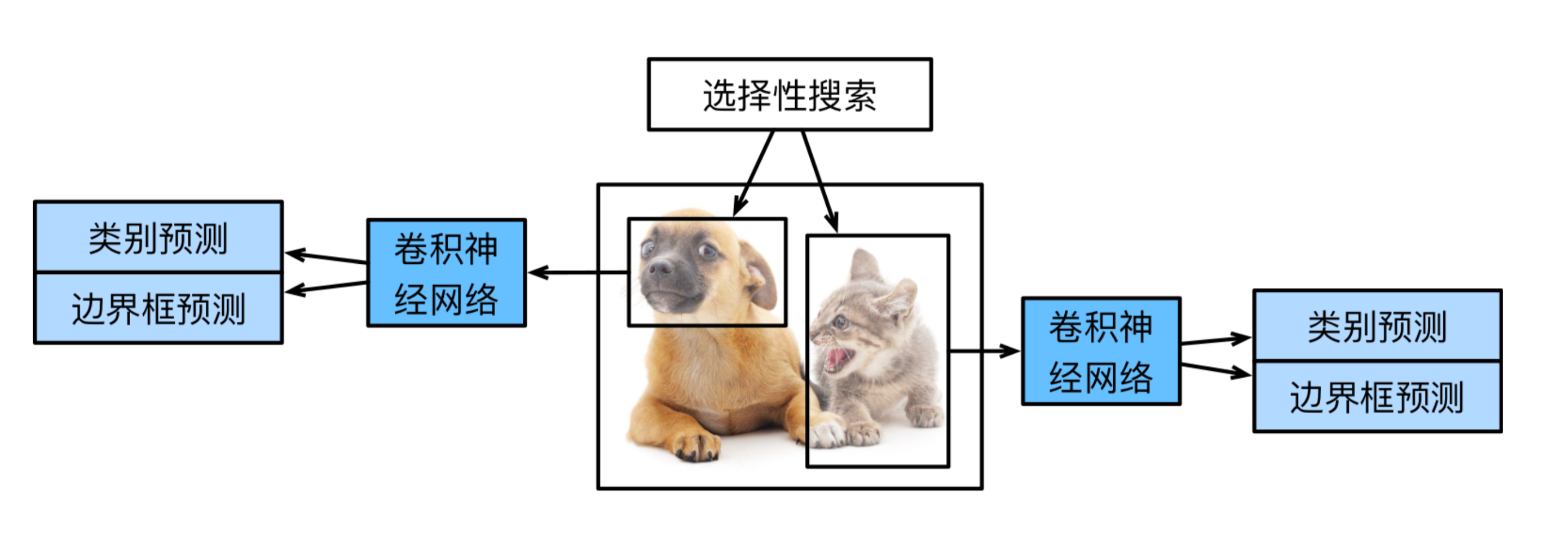
R-CNN的主要性能瓶颈在于需要对每个提议区域独立抽取特征。由于这些区域通常有大量重叠,独立的特征抽取会导致大量的重复计算。Fast R-CNN对R-CNN的一个主要改进在于只对整个图像做卷积神经网络的前向计算。
Fast R-CNN
Fast R-CNN模型:
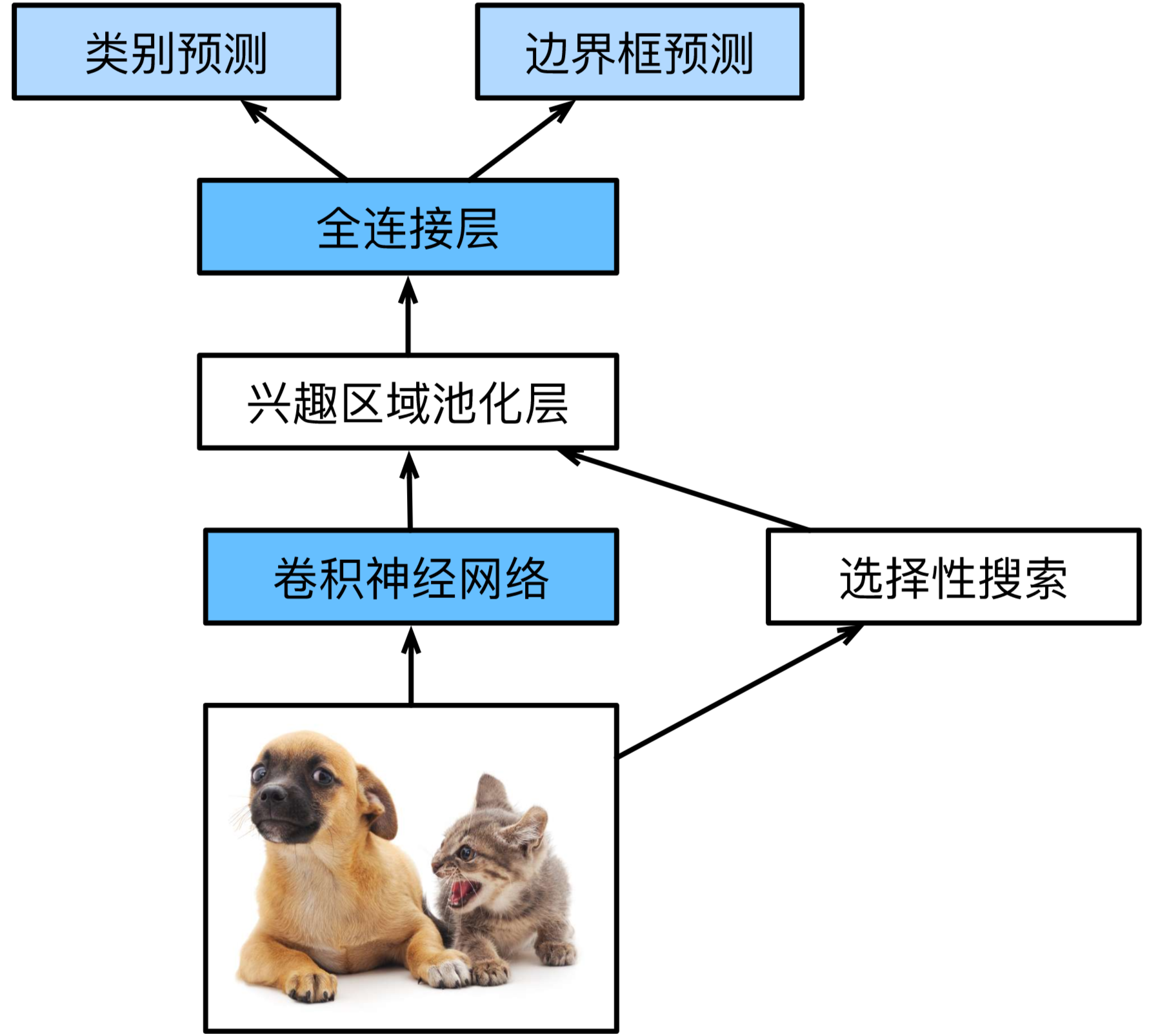
Fast R-CNN通常需要在选择性搜索中生成较多的提议区域,以获得较精确的目标检测结果。Faster R-CNN提出将选择性搜索替换成区域提议网络(region proposal network),从而减少提议区域的生成数量,并保证目标检测的精度。
Faster R-CNN
Faster R-CNN模型:
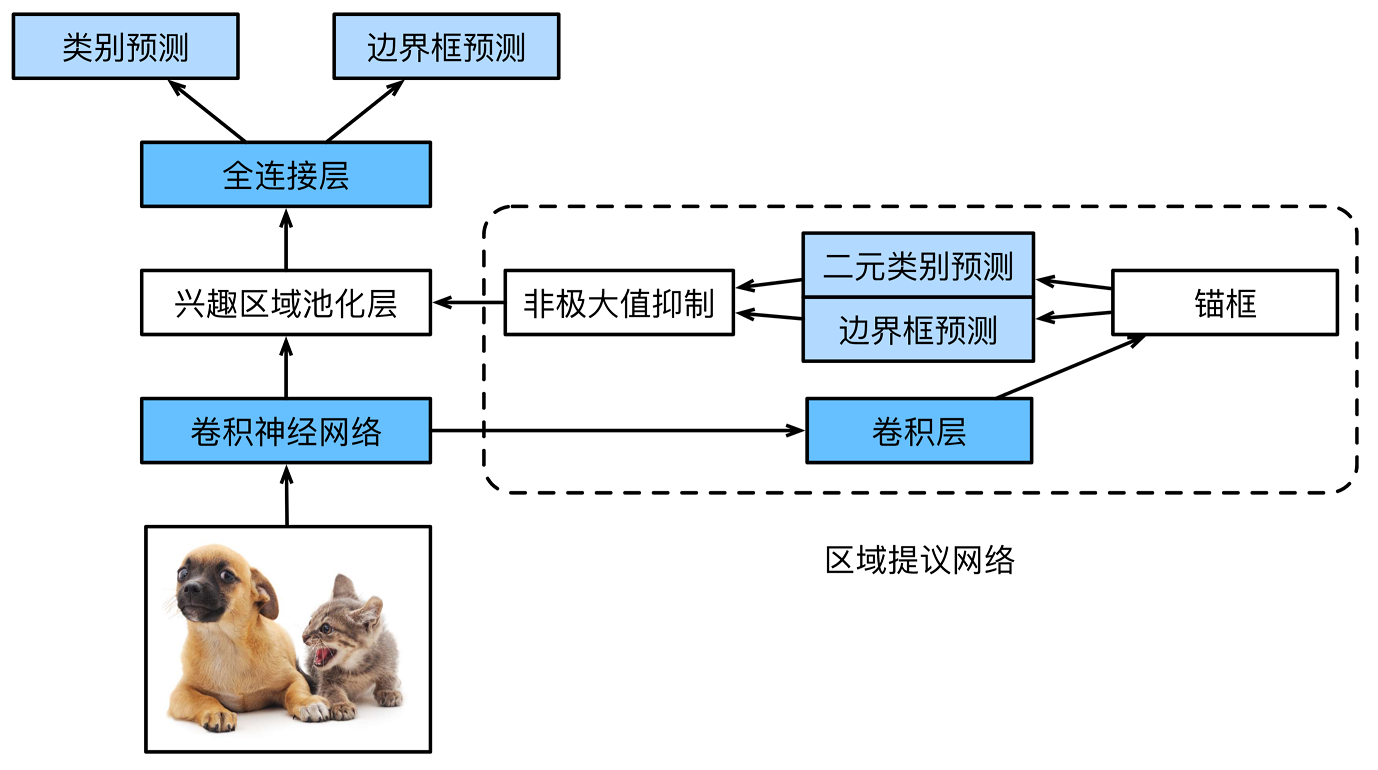
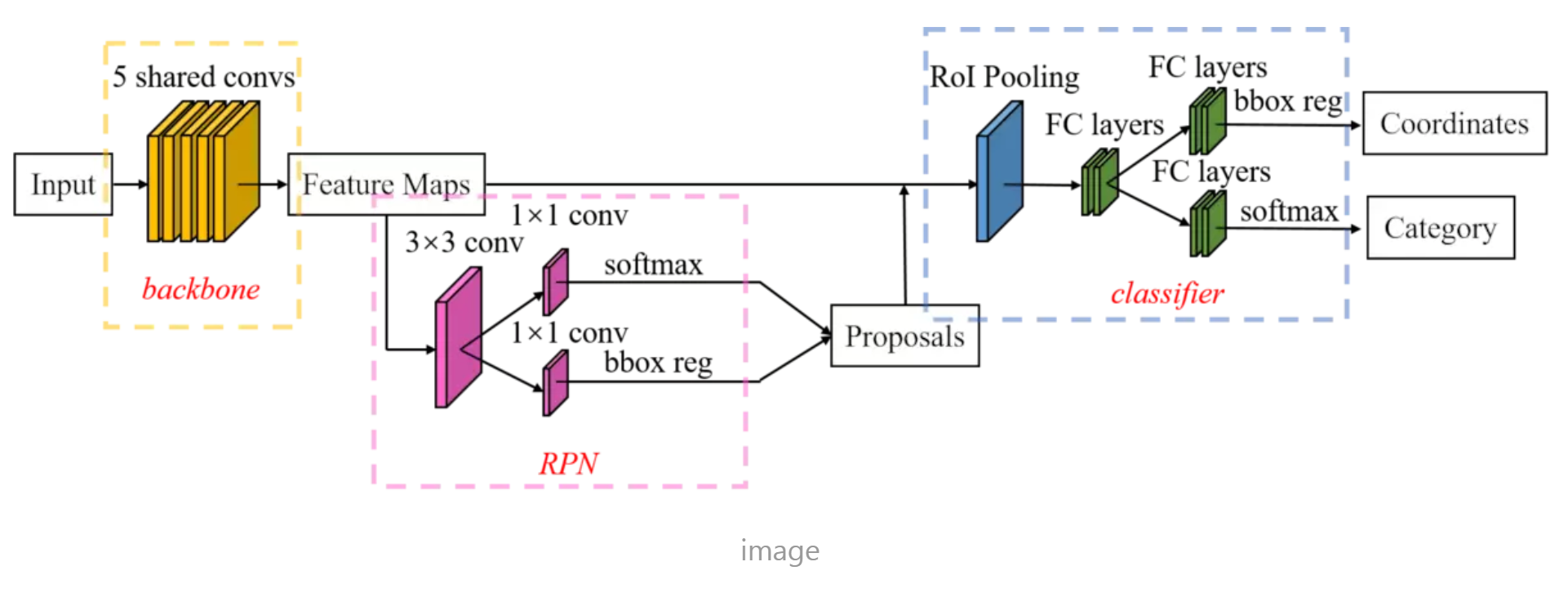
概念理解
思想:SPP逆向(即从相同尺寸的输出,倒推得到不同尺寸的输入)
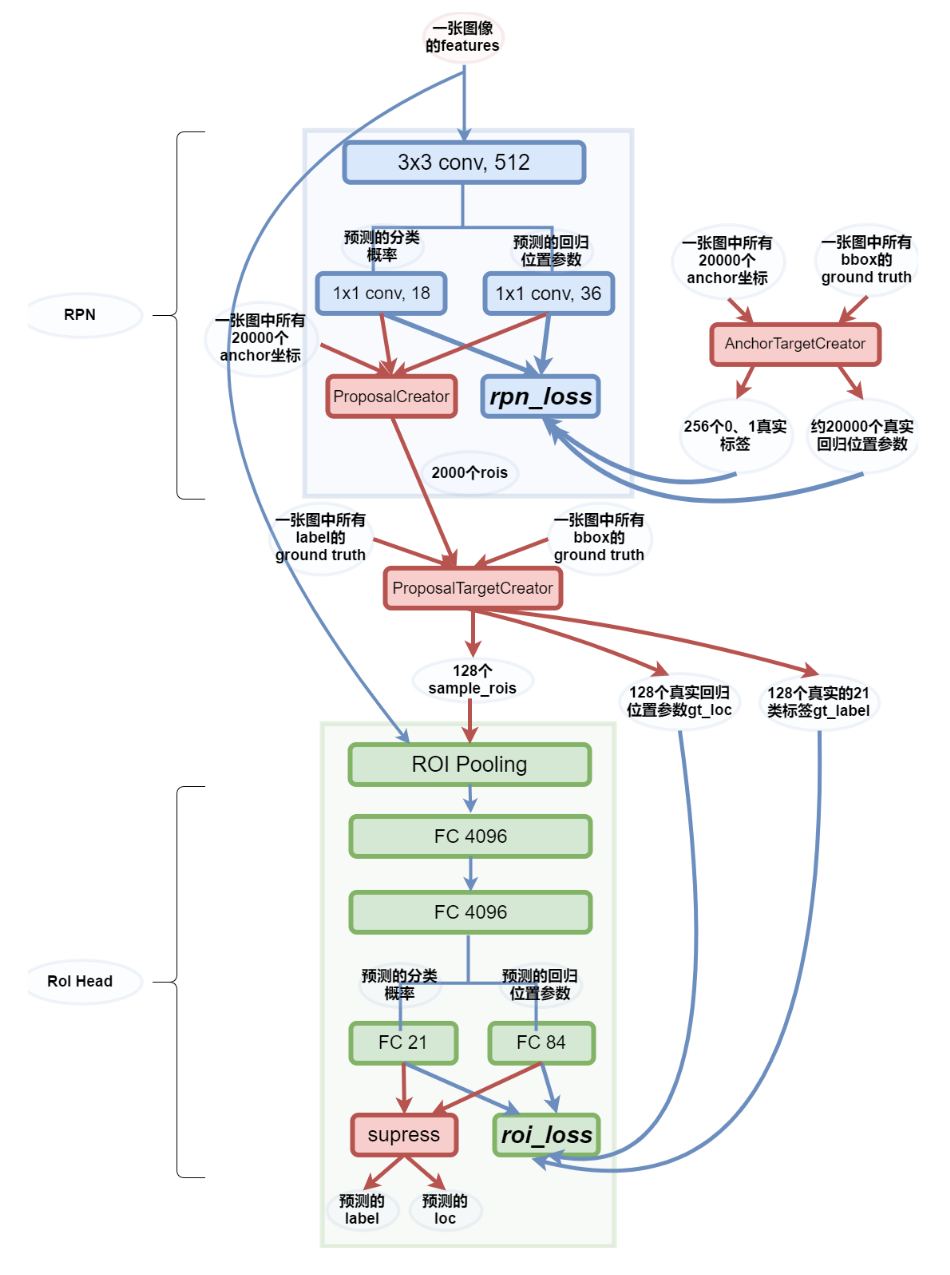
feature maps:51*39*256(256是层数),在feature maps的基础上,通过一个3*3的滑动窗口,stride=1,padding=2,就能得到51*39个的窗口。对于每个3*3的窗口,计算这个3*3滑动窗口的中心点(这个中心点就是anchor)在原图中的对应点。每个3*3窗口,假定它来自9种不同的原始区域(就是原始图片)。我们可以根据宽高比和缩放比,逆向推导出它所对应的原始图片中的一个区域(共9个)。这9个区域就是proposal。
我们通过滑动窗口和anchor,得到 51x39x9 个原始图片的proposal。接下来,每个proposal我们只输出6个参数:每个 proposal 和 ground truth 进行比较得到的前景概率和背景概率(2个参数);由于每个 proposal 和 ground truth 位置及尺寸上的差异,从 proposal 通过平移放缩得到 ground truth 需要的4个平移放缩参数。
anchor box个数:51 x 39 x 9 = 17900,约等于 2k
Mask R-CNN
如果训练数据还标注了每个目标在图像上的像素级位置,那么Mask R-CNN能有效利用这些详尽的标注信息进一步提升目标检测的精度。
Mask R-CNN模型:
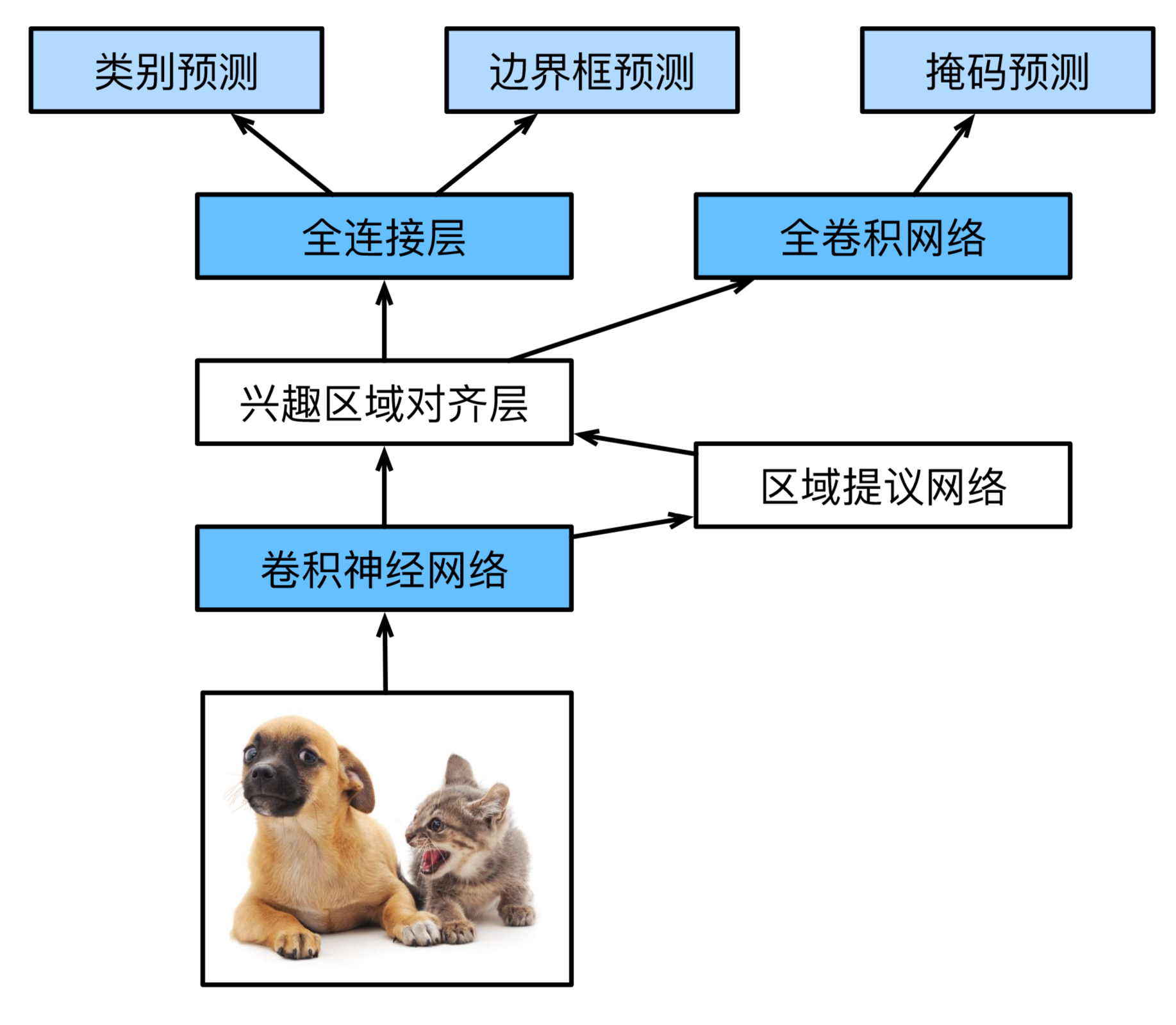
Mask R-CNN在Faster R-CNN的基础上做了修改。Mask R-CNN将兴趣区域池化层替换成了兴趣区域对齐层,即通过双线性插值(bilinear interpolation)来保留特征图上的空间信息,从而更适于像素级预测。兴趣区域对齐层的输出包含了所有兴趣区域的形状相同的特征图。它们既用来预测兴趣区域的类别和边界框,又通过额外的全卷积网络预测目标的像素级位置。















 5264
5264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









