







概要
performance metrics
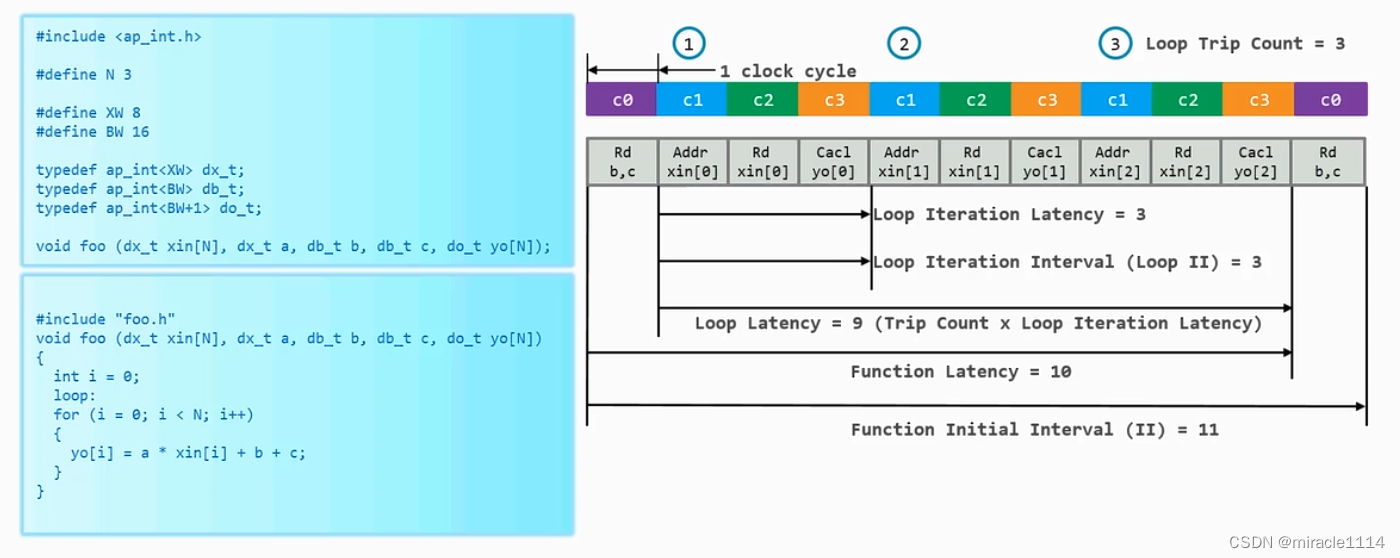 loop trip count = 3循环执行了三次
loop trip count = 3循环执行了三次
loop iteration latency 循环里有三个时钟
loop interation interval 每个循环间隔3个时钟
需要判断i是否继续满足循环的条件,需要额外加入一个时钟的工作。
Pipeline
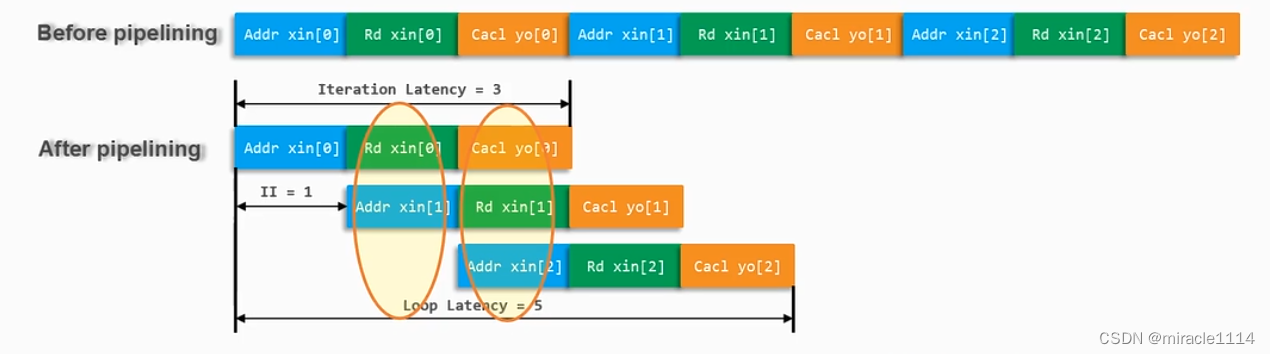
椭圆标出了正在并行执行的部分。
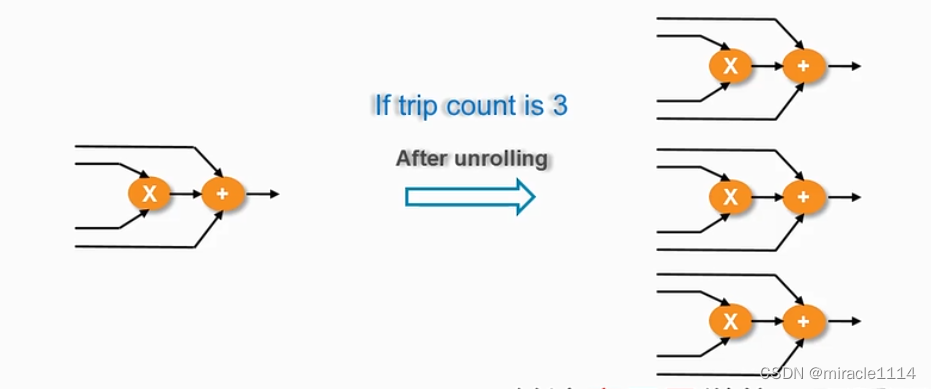
Unrolling
未使用unroll的情况下,循环都是默认“折叠“了。即每次循环都是采用一套电路。
这个“展开”策略,就是类似复制操作。
完全展开,factor == 3
DSP48E被复制了三份
Loop Merge
对于两个for循环
一个for循环至少需要一个状态机,因此合并能够提高latency,interval等。
对于N>M的情况下,合并后的for循环trip count是N。
其中N是常数,M是变量,无法合并。
对于可变的循环边界,解决方案是:
修改代码,扩大小的边界的循环。
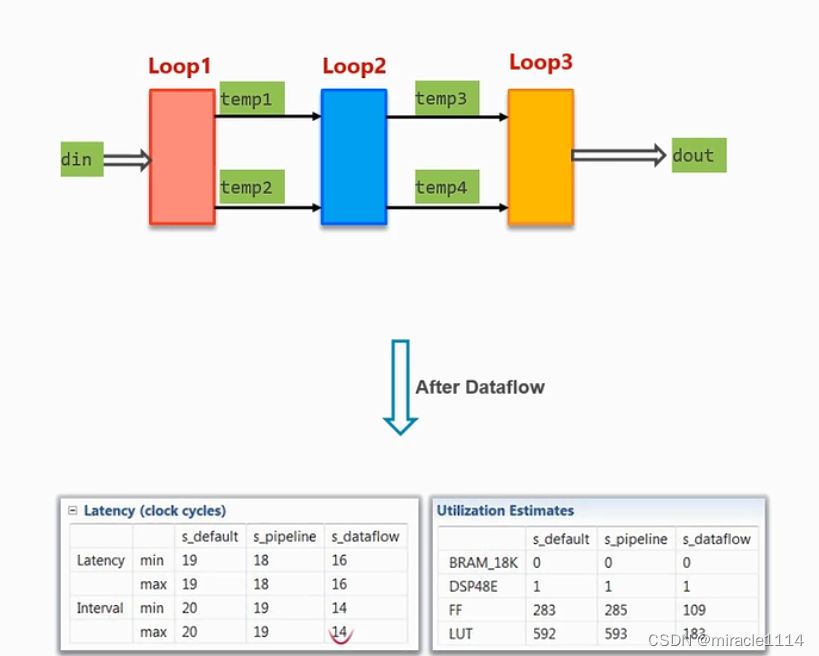
Dataflow
对于三个有依赖关系的for循环,可以进行pipeline,但是不能merge,因此可以使用Dataflow。
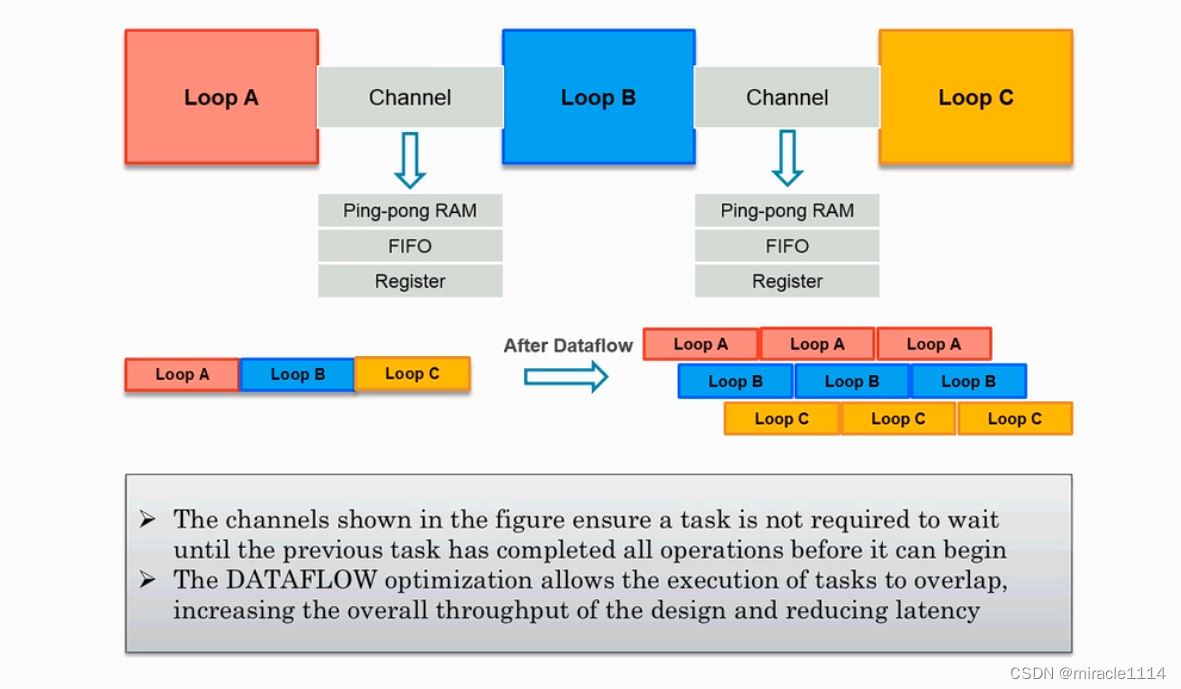
Dataflow分为pingpong,FIFO,register。
对于BYpass案例,前后互相依赖的,
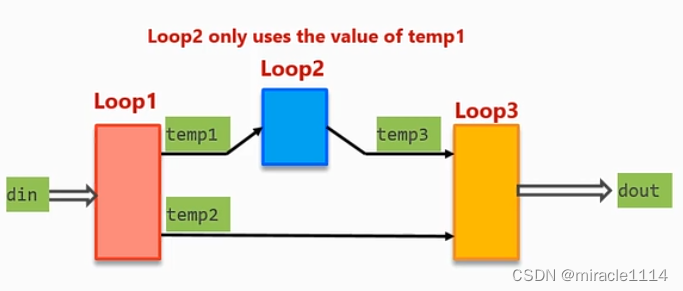 可以通过再多复制一个loop,temp4只是temp2的复制
可以通过再多复制一个loop,temp4只是temp2的复制
对于scalar, pointer, and reference parameters,作为FIFO
数组,FIFO or ping-pong。
配置FIFO的时候,注意深度,否则仿真会错误。
嵌套循环的三种类型
- perfect loop nest
内外都是constant,loop body在内部 - Semi-perfect
最外层可以是variable,最内层是constant - Imperfect (转化成perfect loop nest/Semi-perfect)
也有两种,边界都是constant,但是loop body在外部。
外部是constant,内部是variable.

最内部进行pipeline通常是最好的可以兼顾latency和资源的方法。
1
对于loop boundary是变量或不相同的时候,无法merge。
把一个相同功能的loop封装成函数,节省了资源,但是仍然分时复用,串行执行。
此时,继续考虑,使用HLS ALLOCATION将函数复制实现并行。
2 rewind
取消不同的for循环之间的interval















 1453
1453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









