






1.基本概念
PR曲线用横轴表示召回率,纵轴表示精确率,将数据绘制成图表的形式。PR曲线可以用于评估分类器的性能,在处理高度不均衡的数据集时,PR曲线能表现出更多的信息。
1.1.曲线中P和R的概念
P:查准率,精确率
精确率(precision)是预测为正例的样本中真正为正例的比例,表示预测为正例的样本中有多少是真正的正例。
R:查全率,召回率
召回率(recall)是所有真正的正例中被预测为正例的比例,表示真正的正例中有多少被正确地预测为正例。
PR曲线以P为横坐标,R为纵坐标,将不同阈值下的预测结果进行可视化。通过观察PR图,可以选择合适的值来平衡查准率和查全率,提高分类器的性能。
1.2.混淆矩阵
在机器学习的分类问题中,TP、FP、TN、FN是评估分类模型性能的四个重要指标,它们组成了混淆矩阵(Confusion Matrix)。
TP(True Positive):真正例,表示预测结果为正例,真实结果也为正例
FP(False Positive):假正例,表示预测结果为正例,真实结果为反例
TN(True Negative):真反例,表示预测结果为反例,真实结果为反例
FN(False Negative):假反例,表示预测结果为反例,真实结果为正例
1.3.P和R的定义
P=TP/(TP+FP)
R=TP/(TP+FN)
2.实现PR曲线
2.1具体代码
from sklearn.metrics import precision_recall_curve
import matplotlib.pyplot as plt
# 准备数据集
y_true = [1, 0, 0, 1, 1, 0, 0, 1, 0, 1]
y_scores = [0.1, 0.4, 0.35, 0.8, 0.6, 0.2, 0.7, 0.9, 0.5, 0.85]
# 计算查准率和查全率
precision, recall, _ = precision_recall_curve(y_true, y_scores)
# 绘制PR图
plt.plot(recall, precision, marker='.')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.show()2.2.代码说明
y_true = [1, 0, 0, 1, 1, 0, 0, 1, 0, 1]
y_scores = [0.1, 0.4, 0.35, 0.8, 0.6, 0.2, 0.7, 0.9, 0.5, 0.85]
定义一个包含10个样本的数据集,y_true是真实标签,y_scores是预测分数
使用precision_recall_curve函数计算查准率和查全率,并将结果分别赋值给变量precision和recall
使用matplotlib库绘制PR图,其中plot函数用于绘制曲线,xlabel、ylabel和title分别用于设置X轴标签、Y轴标签和标题,show函数用于显示图形
2.3.得到的PR图
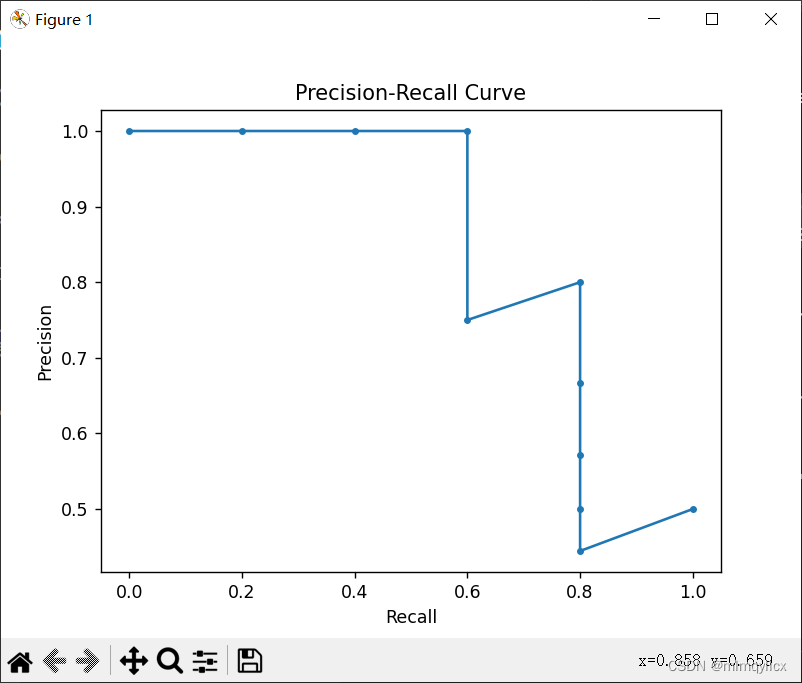
3.结论
PR曲线可以反映分类器对于正样本的识别准确率,以及对于所有正样本的覆盖程度。通过绘制多个不同分类器的PR曲线,可以比较它们的性能,选择最好的模型。观察PR曲线在不同阈值下的变化,可以调整模型的参数,以优化模型的性能。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









