






 一项项目已顺利完成,但受限于GPU设备的缺失,导致无法充分利用技术潜能。这引发了关于硬件依赖性以及如何处理类似延迟部署的讨论。
一项项目已顺利完成,但受限于GPU设备的缺失,导致无法充分利用技术潜能。这引发了关于硬件依赖性以及如何处理类似延迟部署的讨论。
准备工作
1、确定显卡支持的CUDA版本并下载
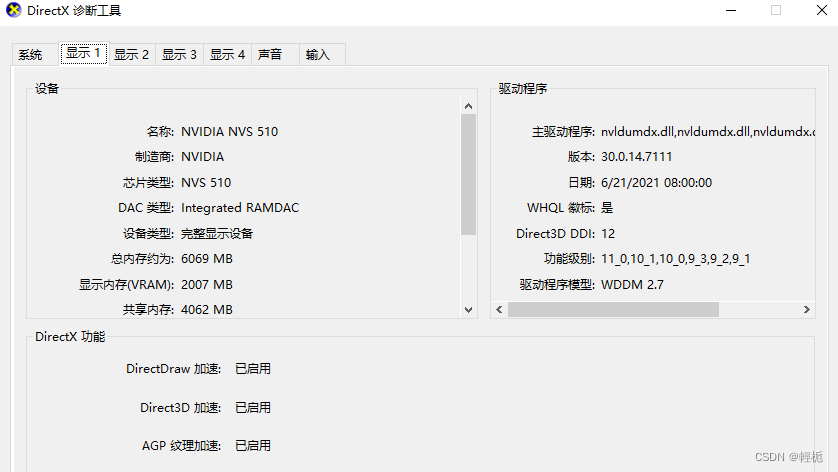
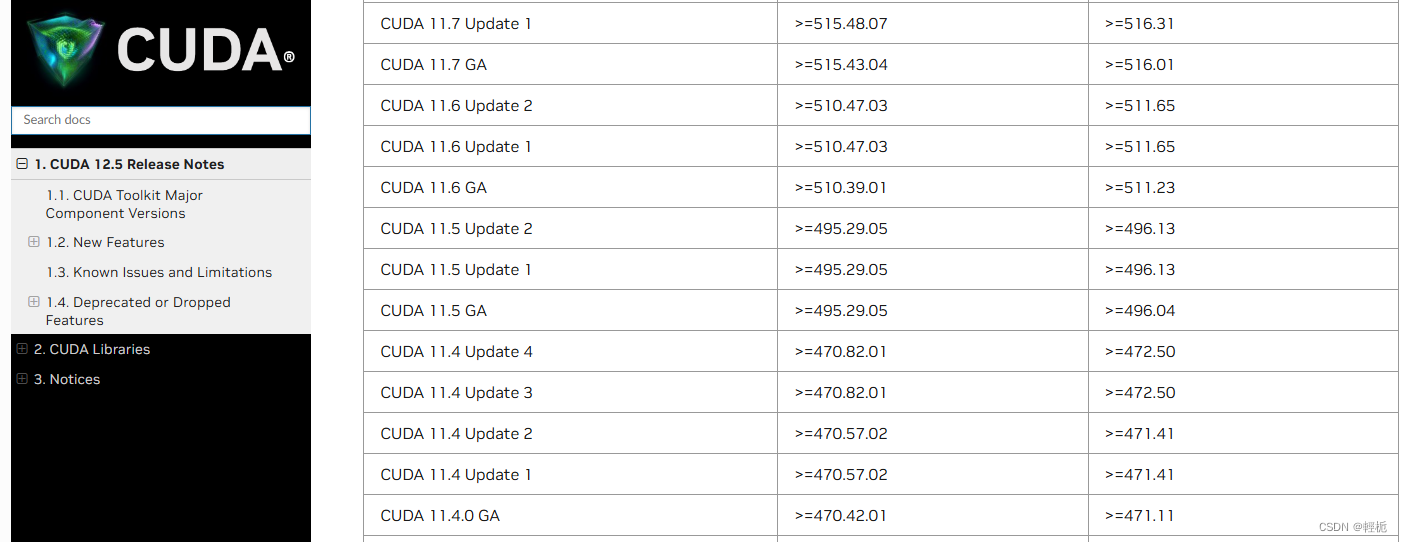
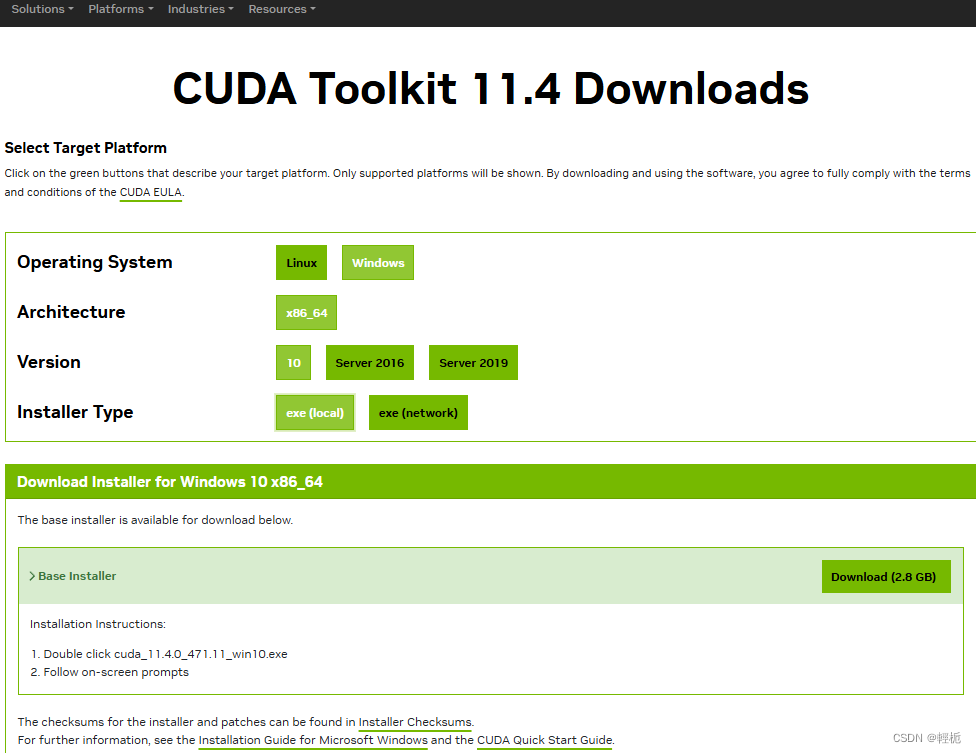
在命令行里面输入dxdiag查看NVIDIA版本,可以看到芯片是NVS 510,随即去查找对应版本的CUDA(CUDA 12.5 Release Notes (nvidia.com)),安装的是CUDA11.4下载CUDA Toolkit 11.4 Downloads | NVIDIA Developer。
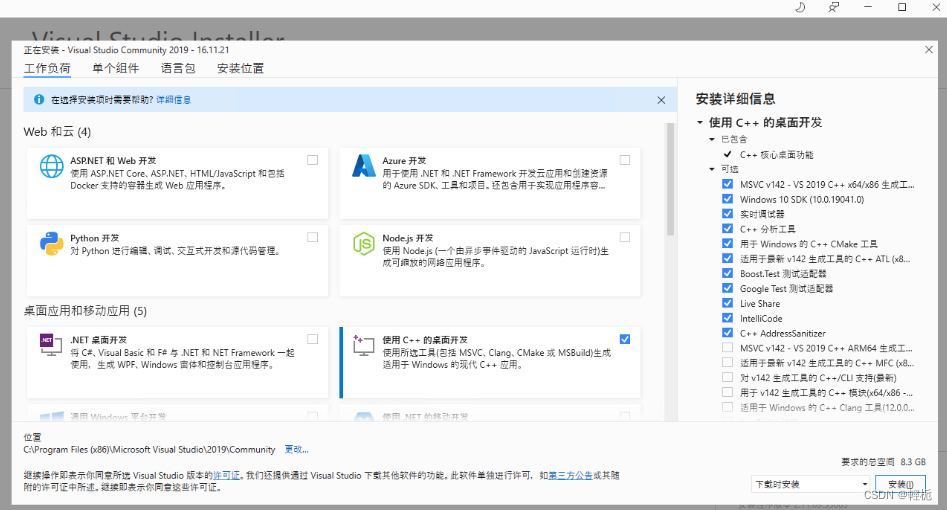
2、准备好CUDA版本对应的vs2019,Visual Studio 较旧的下载 - 2019、2017、2015 和以前的版本 (microsoft.com),下载好后选择C++桌面开发模块,点击下载安装。
CUDA安装包下载好后,双击安装,然后点击OK和下一步即可,选项选择自定义,自定义里面的CUDA-vs溴铵想取消勾选,默认安装在C盘,安装完成后,会提示Nsight Visual studio的整合情况,这里提示安装了vs2019版的,正是我们前面安装的VS版本,这样就能在vs2019里面做GPU方面的开发。
3、进入管理员的cmd,输入命令:nvcc -V ,有结果说明安装成功。
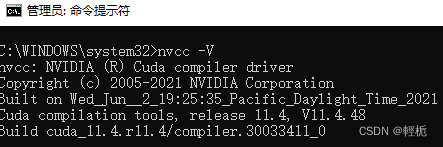
接下来进入C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\extras\demo_suite,查询本机的gpu设备info:deviceQuery
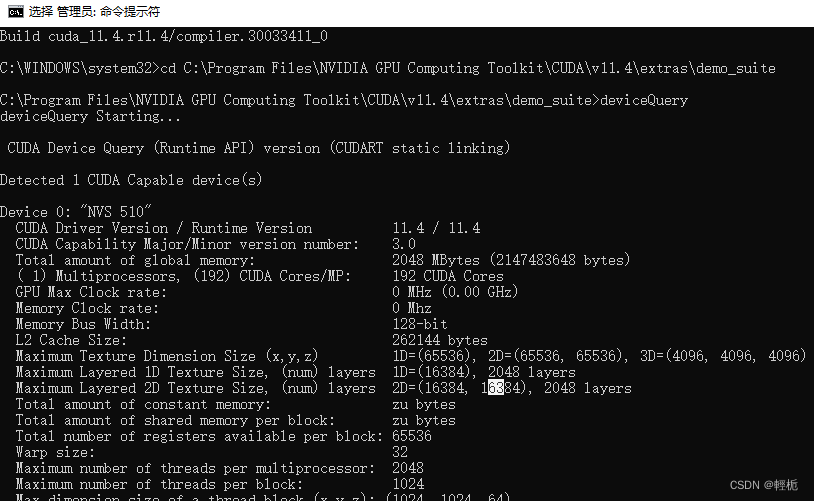
测试带宽:bandwidthTest ,结果都是PASS,说明一切运行正常。
4、创建pytorch的环境:(CUDA 10.1 支持 Python 3.5 - 3.8,而 CUDA 11.0 则支持 Python 3.5 - 3.9)
conda create -n pytorch-gpu python==3.9到官网下载pytorch:PyTorch,复制命令激活刚才的虚拟环境运行,
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118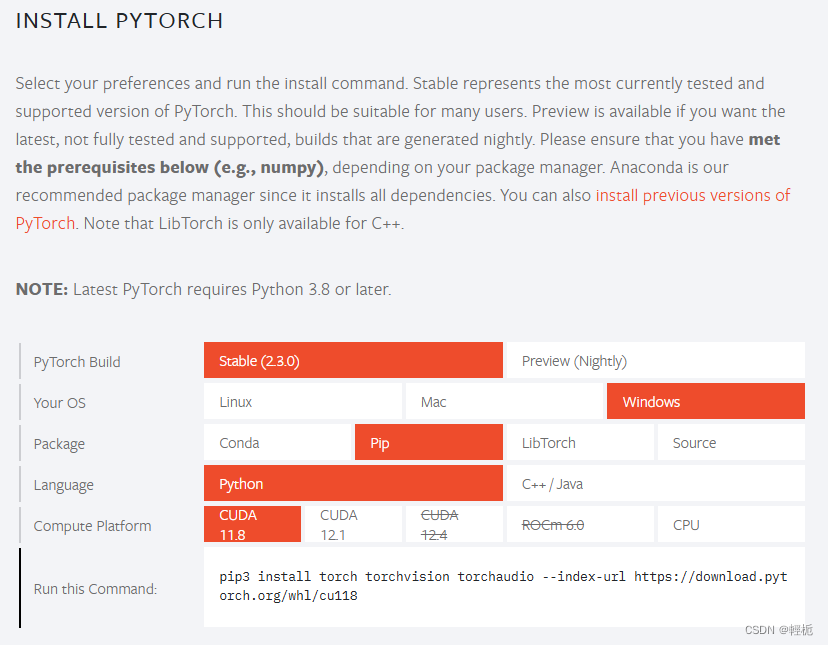

测试是否可用:
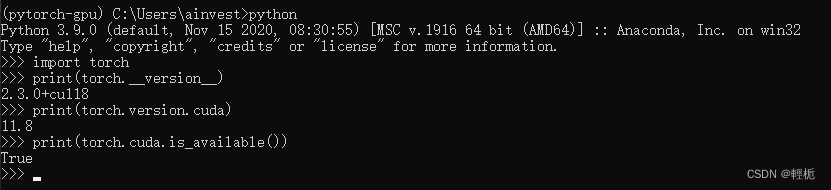
import torch
print(torch.__version__)
print(torch.version.cuda)
print(torch.cuda.is_available()) #输出为True,则安装无误
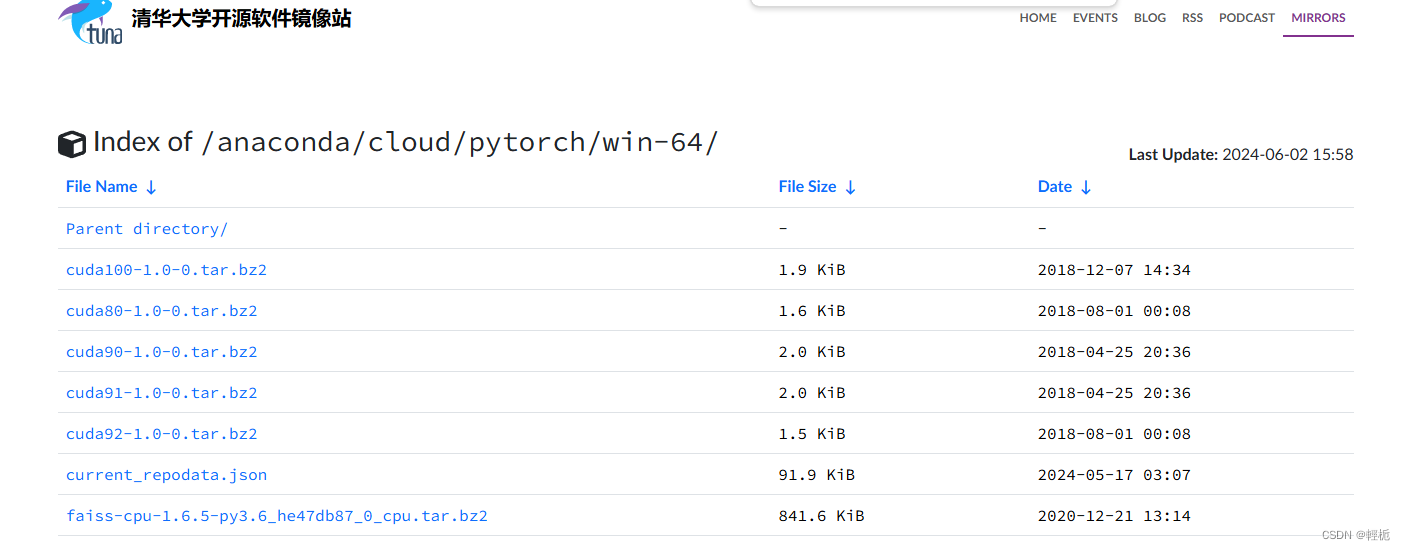
5、若安装失败就去清华大学开源软件镜像:Index of /anaconda/cloud/pytorch/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
找到对应的pytorch、torchvision、torchaudio的版本下载,自身python里面的版本是:
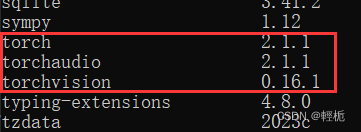
去对应目录下载即可(pytorch版本尽量最新,cuda等版本尽量找与主机相近的版本):
![]()
![]()
![]()
------------------------------------------------------------------
1.准备 OpenCompass 运行环境:(不可跳过)
面向开源GPU测试环境:需要在此环境下安装pytorch,命令上面。
conda create --name opencompass python=3.10 pytorch torchvision pytorch-cuda -c nvidia -c pytorch -y
conda activate opencompass面向基于API的开源CPU测试环境:
conda create -n opencompass python=3.10 pytorch torchvision torchaudio cpuonly -c pytorch -y
conda activate opencompass
# 如果需要使用各个API模型,请 `pip install -r requirements/api.txt` 安装API模型的相关依赖如果你自定义 PyTorch 版本或相关的 CUDA 版本,请参考 官方文档 准备 PyTorch 环境。需要注意的是,OpenCompass 要求 pytorch>=1.13。
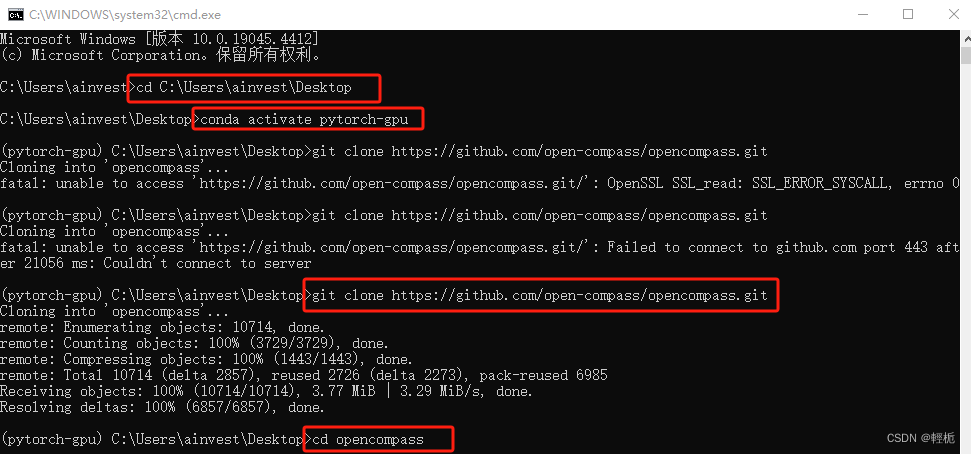
2.安装 OpenCompass(首先进入你想要安装opencompass的文件夹,重启一个cmd,我直接放在桌面):
cd C:\Users\ainvest\Desktop
conda activate opencompass
git clone https://github.com/open-compass/opencompass.git
cd opencompass
pip install -e . 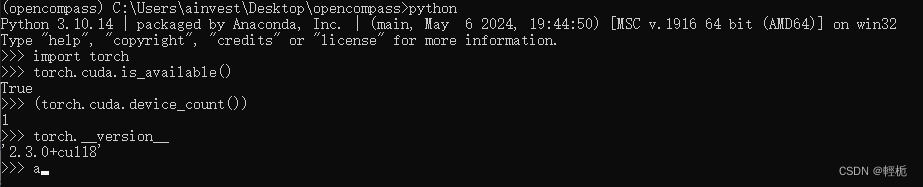
遇上git不下来直接开个vpn即可,或者你直接去项目上dow一下(https://github.com/open-compass/opencompass)
3、安装完成后开始准备数据集,OpenCompass 支持的数据集主要包括两个部分:
-
Huggingface 数据集: Huggingface Dataset 提供了大量的数据集,这部分数据集运行时会自动下载。
-
自建以及第三方数据集:OpenCompass 还提供了一些第三方数据集及自建中文数据集。运行以下命令手动下载解压。
在 OpenCompass 项目根目录下运行下面命令,将数据集准备至 ${OpenCompass}/data 目录下:
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
unzip OpenCompassData-core-20240207.zip如果需要使用 OpenCompass 提供的更加完整的数据集 (~500M),可以使用下述命令进行下载和解压:
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-complete-20240207.zip
unzip OpenCompassData-complete-20240207.zip
cd ./data
find . -name "*.zip" -exec unzip "{}" \;一般需要VPN下载,如果不需要全量下载仅是测试,可以从下渠道下载对应模型的评测数据:
4、评测原理:
首先,常见的大模型评测模式可以大致总结为以下三种:
a、做题打分。主要是收集各种各样的评测数据集,然后把数据集分为不同的维度能力。通过设计一些prompt让大模型去做这些数据集的任务,与标准答案进行对照计算分数。典型的如openCompass,huggingface的openLLM leaderboard等。
b、让GPT-4做裁判。还是会收集评测用的数据集(一些不是公开开源的、不带标准答案的数据集也会包含在内),然后让GPT-4给大模型的生成结果进行评判。评判这块又有很多工作衍生出来,例如有直接让打分的,也有设计一些维度(例如事实性、准确性、安全合规性等),然后更细粒度地进行评测的。
c、竞技场模式。类似于竞技游戏里面的竞技场。每次拉两个大模型选手PK,由用户来评测哪个模型更好,赢的大模型有加分,输的大模型有减分。当执行了足够多的PK轮次后,就会有一个大模型的得分排行榜,这个榜单相对来说还是比较公正的,能够较为客观得体现模型的能力强弱。典型的例子如UC伯克利发布的Chatbot Arena Leaderboard。
当然,除去上述模式外,还有很多针对单项能力的评测,例如针对数学能力、针对代码能力、针对推理能力等,评测这些能力一个是可以判断一个大模型是否真的具备类似人类得思考能力,另一方面其评测结果也是能够直接帮助在特定领域场合中选择大模型(例如代码助手)。
openCompass评测机制
评测工具openCompass属于第一种模式,他是书生大模型(internLM)的研发团队开源出来的大模型评测工具,也是当前市面上极少有的代码级开源评测项目。它包含了数据集处理、模型加载与生成、结果的评测与指标计算等流程,构成了一个完整的评测生命周期:
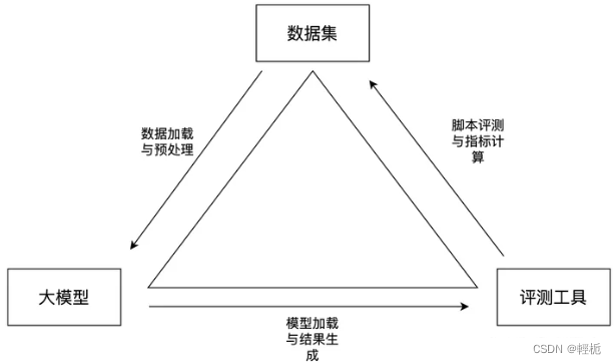
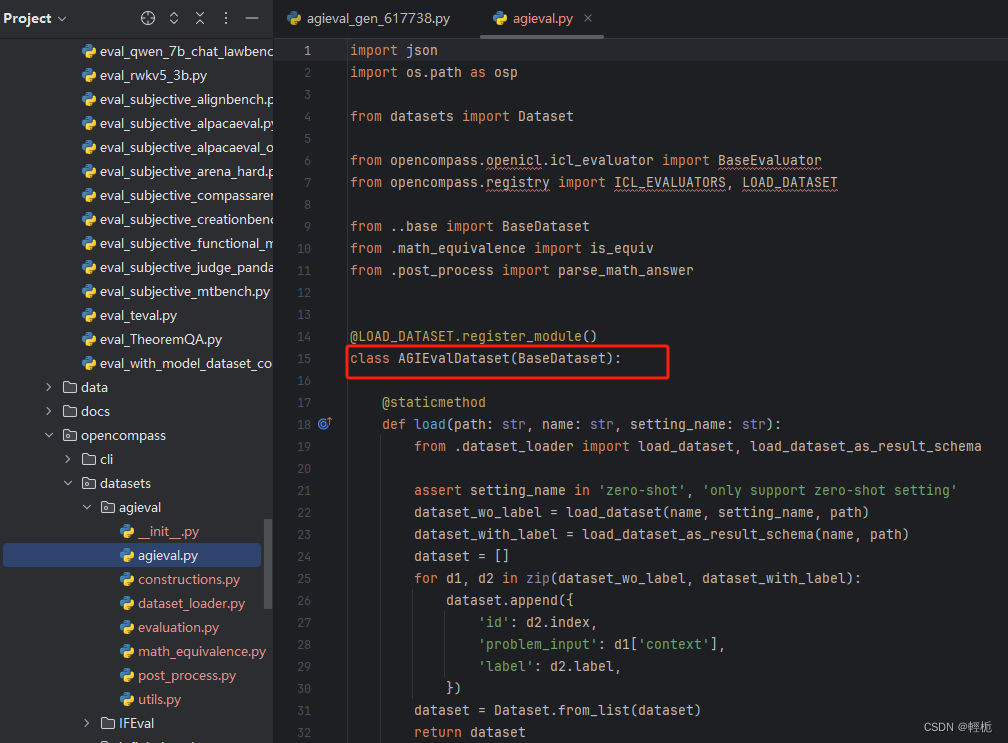
另外,它最大的一个特点就是囊括了非常多的数据集以及对应数据集的预处理加工脚本。传统的NLP数据集在输入大模型之前,要经过数据预处理加工,转换成instruction+input+output的文本生成任务格式。不同数据集的原始格式不尽相同,不同类型的任务如信息抽取与文本分类、语义理解与文本生成之间的区别较大,即使是同类型任务的不同数据集格式也有很大差异。因此要开发不同的预处理脚本,工作量非常大。而openCompass已经预置了相当多的国内外数据集处理脚本,即使不用openCompass,我们也可以参考其中的处理方式,快速移植到我们自己的项目中,以下是agieval数据集的加载和预处理示例(有本身的注册器,也可以自定义):
数据加载
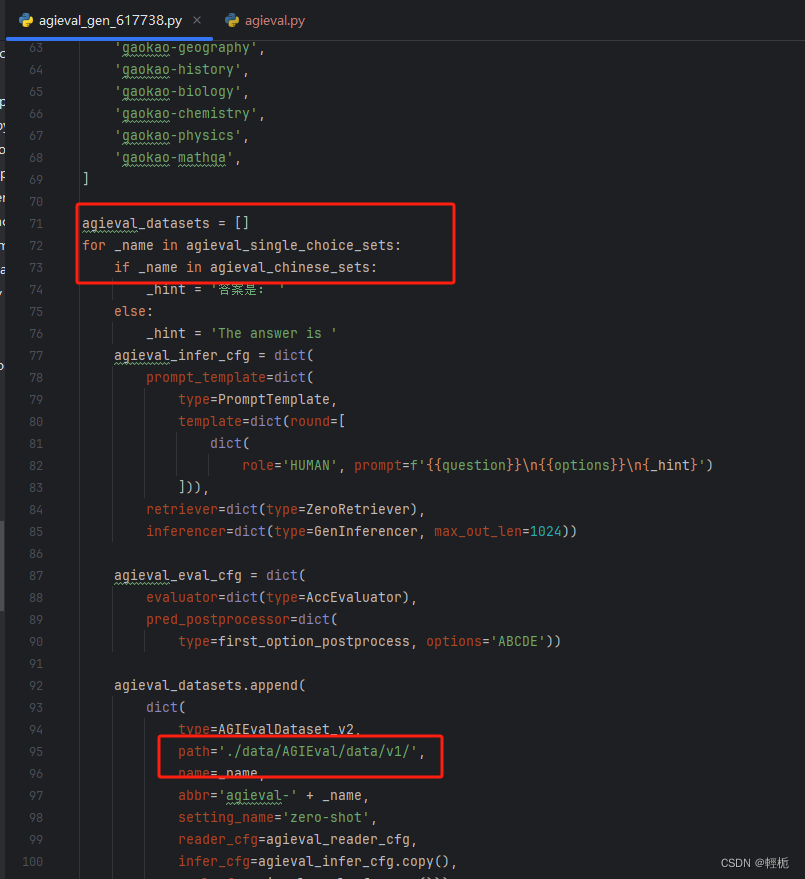
数据预处理(确保数据在所在文件夹)
运行机制
从宏观整体的维度说明openCompass的评测工作流程,下图为一个简易的流程图:
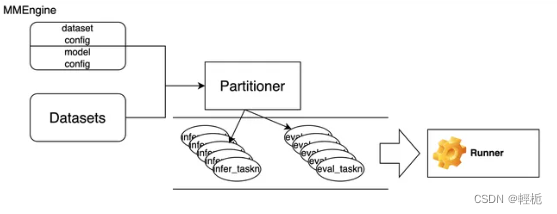
整个项目基于的是MMEngine框架,在此框架下,Partitioner模块会接收数据集与参数配置模块,并根据模型生成、结果评测等类型将整个评测任务拆分多个最小粒度的task元素。参数配置模块包括数据集的配置和模型的配置。数据集配置包括数据集的加载、预处理等配置,模型的配置包括模型的加载、预测生成等配置。最后我们有一个Runner模块负责管理和有序执行所有的task,完成最终的评测任务。下面详细的分析各个模块的原理。
openCompass的项目结构还是比较清晰的,主要由以下核心模块组成:
(1)MMEngine
作为组成openCompass的基本框架,MMEngine由openMMLab实验室发布出来的一个基于pytorch的深度学习基础库,框架比较复杂,封装得比较深,要了解其原理的话建议参考官方文档:OpenMMLab:从 MMCV 到 MMEngine,架构升级,体验升级!。由于openCompass并没有涉及到模型训练等复杂功能,因此它只是借助于MMEngine的部分特性构建了一个评测平台,用于管理数据、模型和评测任务。下面讲到的模块都用到了其中的基础功能。
(2)配置模块
openCompass中主要包含数据集配置(dataset configs)与模型配置(model configs),见项目中的configs/。数据集配置(见configs/datasets/,以及opencompass/datasets/)主要包含了以下内容:
a.数据集加载方式。不同数据集的文件格式、字段名称都不同,因此需要针对性配置对应的文件读取方式。这个配置主要见opencompass/datasets/下。
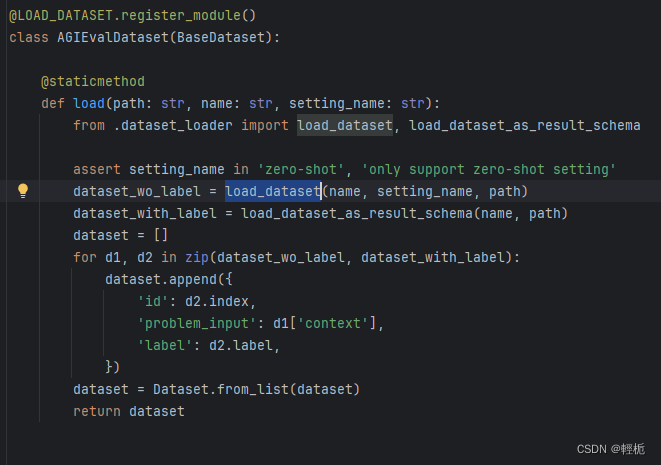
上图中可以看到有个register_module(),这个就是MMEngine的一个基础特性。MMEngine 实现的注册器可以看作一个映射表和模块构建方法(build function)的组合。映射表维护了一个字符串到类或者函数的映射,使得用户可以借助字符串查找到相应的类或函数。上图中是已经创建了一个注册器LOAD_DATASET,通过注册将cmmlu的加载模块加入到注册器中。这样,后面,我们只需要通过类似
LOAD_DATASET.build(dict(type=“agievalDataset”))的方式就能以配置的形式调用对应的方法。在openCompass中,调用的脚本可见:opencompass/utils/build.py中的build_dataset_from_cfg:
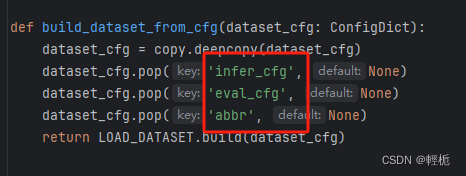
调用注册器中的对应模块
openCompass中除了数据集的注册器外,还预置了其他核心模块的注册器,如模型、任务等,可见opencompass/registry.py。其中的注册器代表了项目中所需要用到的核心要素。
b.数据预处理。这里的预处理主要是将数据集原始格式转化为大模型能够支持的输入格式,即构造instruction+input+output的prompt数据,配置数据字段与prompt模版中需要填充的槽位对应关系:















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









