









1、当梯度很小时,优化效果没有达到期望
Optimization失败的原因:(1)local minimum;(2)saddle point(鞍点)
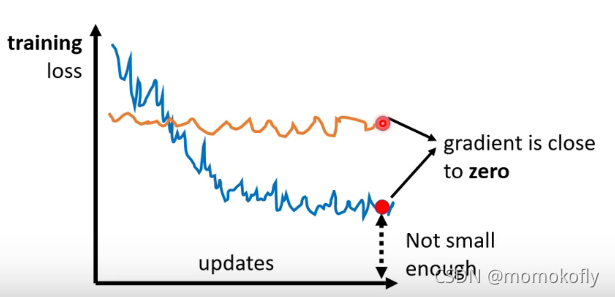
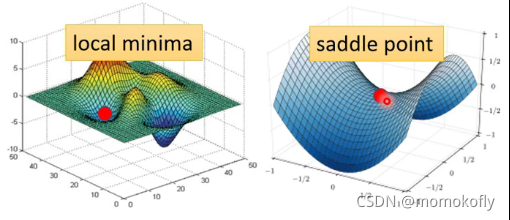
gradient为0,会导致loss不下降,即卡在了critical point(包括local minimum和saddle point)。 对于local minimum的问题可能无法解决,但是saddle point还是有可能解决。
数学推导
Taylar Series Approximation,泰勒展开式近似

critical point是指,近似式右边的第二项为0,根据第三项就可以知道是哪种critical point。
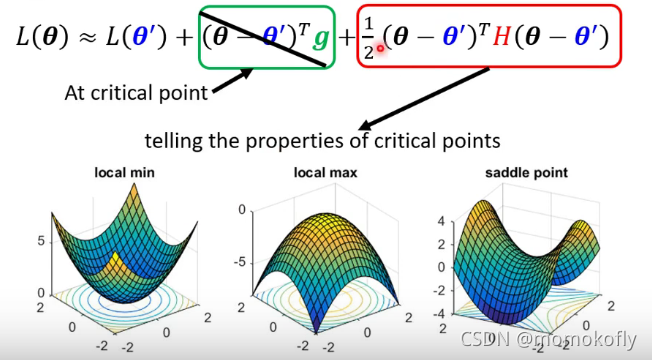

说明只要根据Hessian矩阵的特征根,即可确定是local minimum,还是local maximum,还是saddle point。
如果critical point 是 saddle point时,此时Hessian矩阵会说明接下来Loss下降的方向,从而有机会继续优化。原因在于:

因此,只要找到此时Hessian矩阵中负的特征根,那么更新参数只要沿着对应的特征向量
u
u
u的方向,就可以逃离saddle point并且降低loss。但这个方法在实际中几乎不使用,因为运算量太大了。
Saddle Point v.s. Local Minimum
这两种critical point哪个更常见?
local minimum可能在高维空间中也是saddle point。

Minimum ratio表明Hessian矩阵的特征根中负的特征根的个数占特征根总数的比例。实际中很少存在全为正或全为负的情况,说明实际中很多情况下都可以继续优化使loss下降。
2、Tips for training:Batch and Momentum
Batch
Optimization with Batch:每一个epoch开始前,会分一次batch,也就是每个epoch中batch的分法都不一样,也称为shuffle。
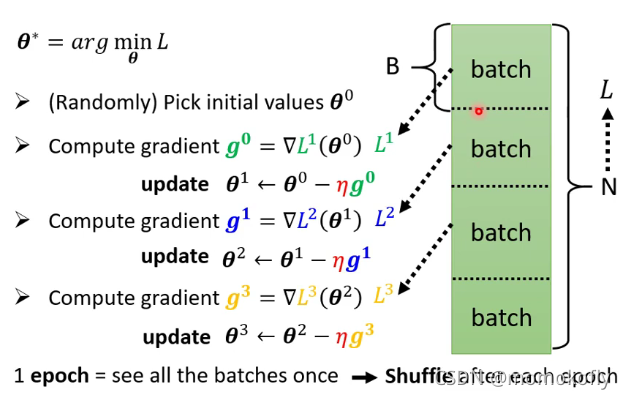
Small Batch v.s. Large Batch:各有各的优缺点

- Larger batch size does not require longer time to compute gradient(unless batch size is too large),因为可以利用GPU进行并行运算,但是并行运算也有极限。
- Smaller batch requires longer time for one epoch(longer time for seeing all data once),考虑平行运算的情况下,较大的batch size可能比较小的batch size更有效率。
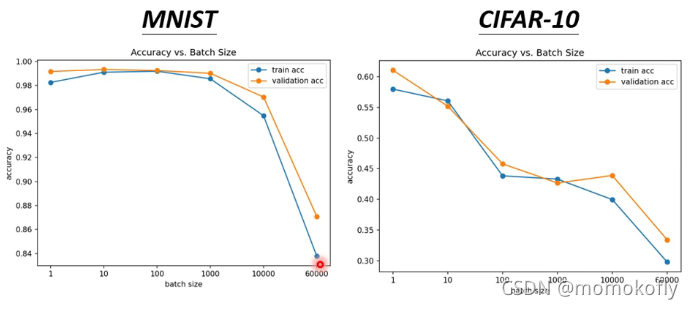
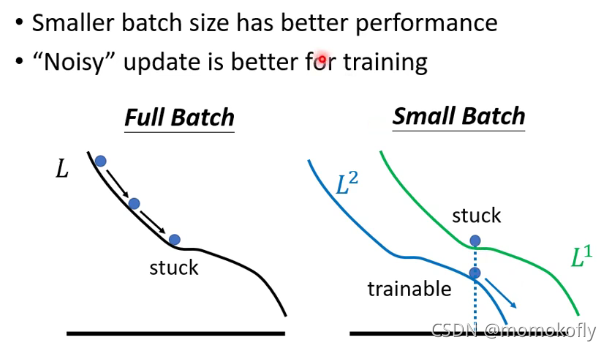
小的batch size的表现更好,因为随着batch size的增加,试验的精确率逐渐降低。那么大的batch size为什么表现会更差呢?因为optimization失败了。具体原因是:小的batch size在优化过程中每个batch中的数据都略有差异,当 L 1 L_1 L1在优化过程中遇到critical point,可以使用 L 2 L_2 L2继续优化,避免因为critical point而loss停止下降。
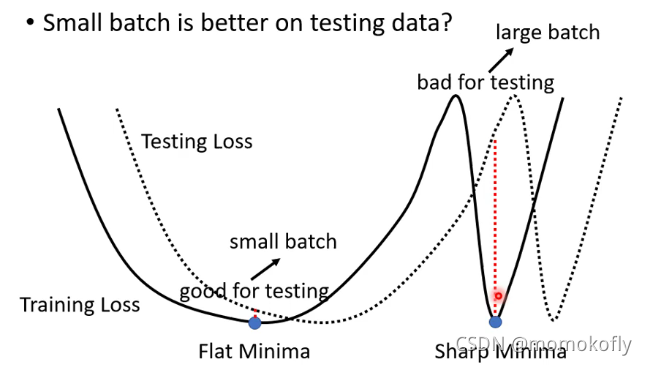
但是根据《On Large-Batch Training for Deep Learning:Generalization Gap and Sharp Minima》的试验结果,小的batch size在训练集表现较好,但在测试集中表现更差,这就是发生了overfitting。
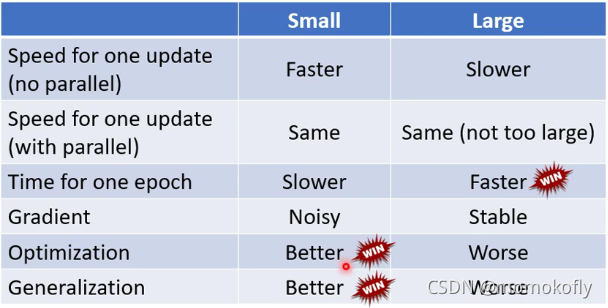
Batch size is a hyperparameter you have to decide。
Momentum
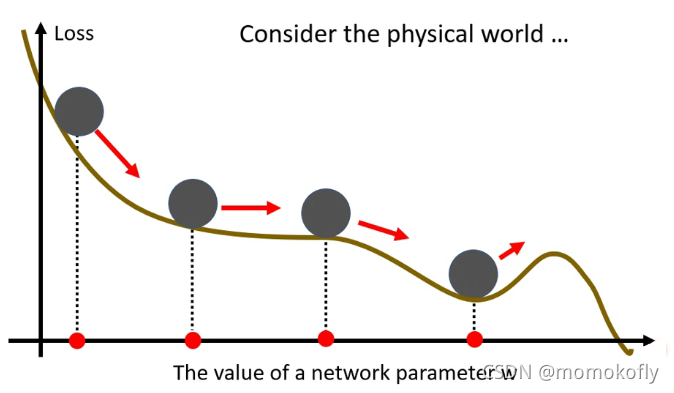
在物理学中,由于惯性因素的影响,下降过程中可能会突破critical point的困境。
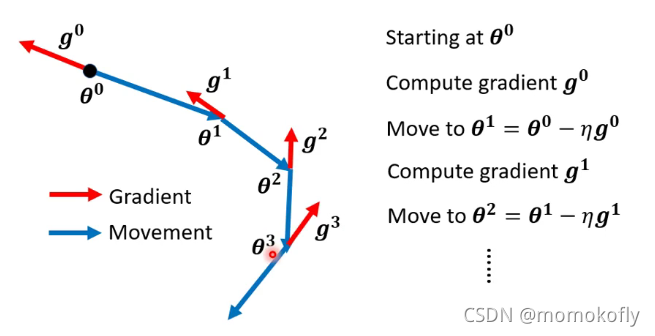
一般的梯度下降过程(Vanilla Gradient Descent):
Gradient Descent+Momentum的过程:
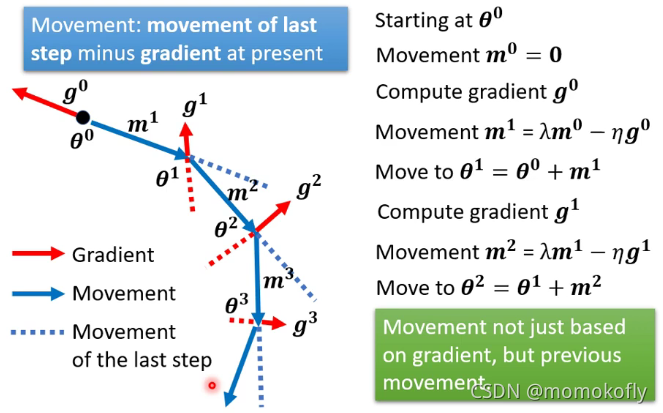
关于加入momentum的两种解读:(1)不止考虑当前点的梯度方向和大小,还考虑上一步的下降的方向和大小;(2)不止考虑当前的梯度大小和方向,还考虑之前的梯度大小和方向:

能突破critical point的原因:
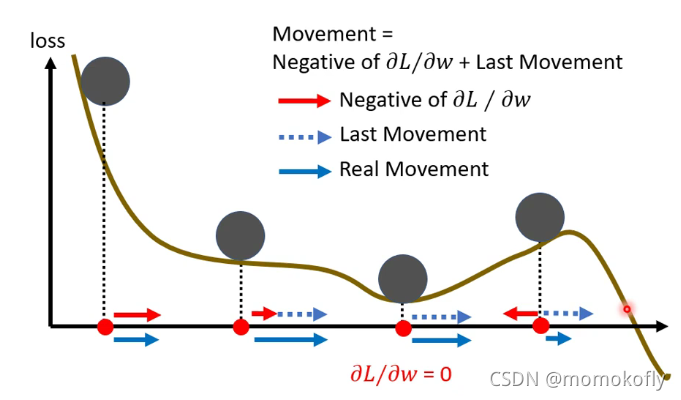
Smaller batch size and momentum help escape critical points.
3、Tips for training:Adaptive Learning Rate
训练过程中最大的阻碍不一定是遇到critical point,需要确定一下当loss不再下降的时候,gradient是否真的很小。
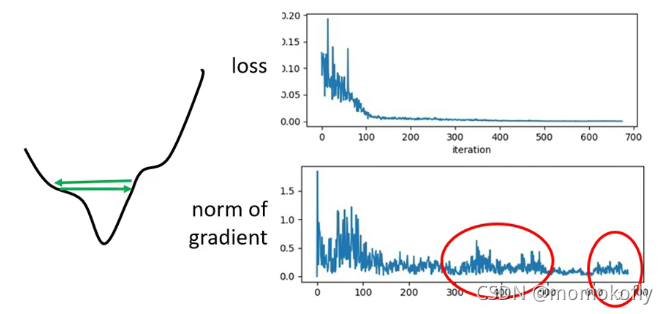
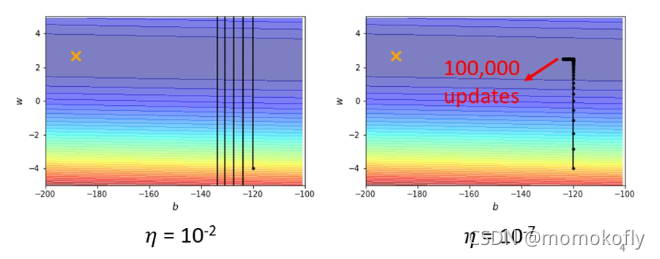
Learning Rate不能所有的参数所有的步骤都一样。考虑定制化的Learning Rate,即Different parameters needs different learning rate,希望在gradient变化大时learning rate较小,而在gradient变化小时learning rate较大。

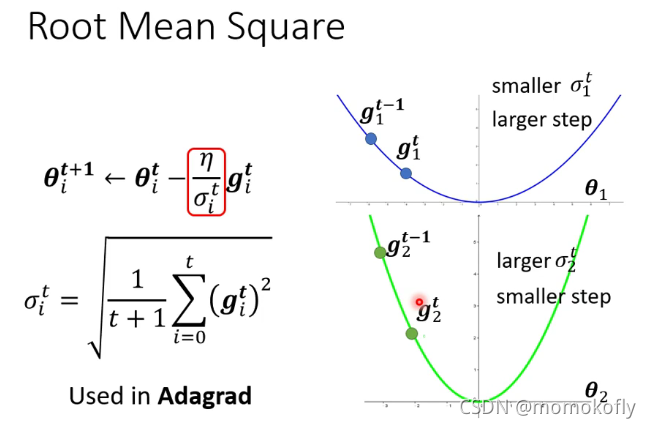
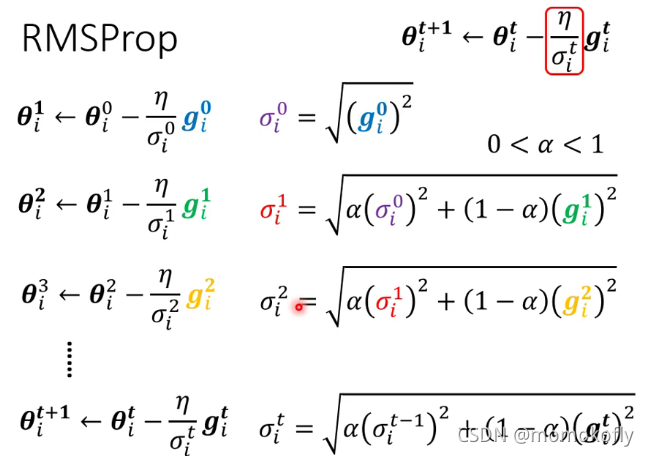
通过调整参数,可以改变最近的gradient的影响程度。
Adam:RMSProp+Momentum
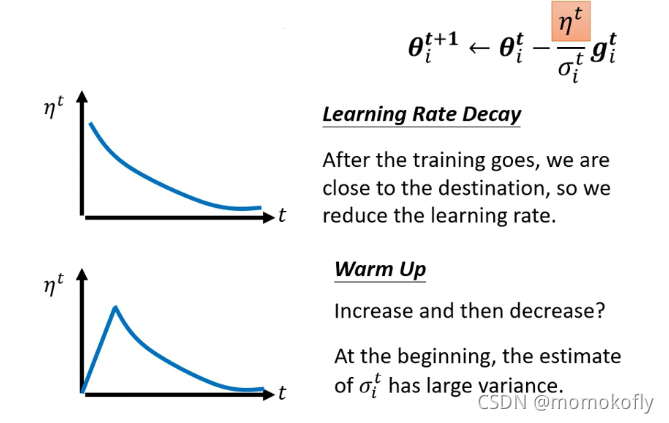
Learing Rate Scheduling:















 142
142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









