






文章目录
摘要
在机器学习训练模型中通过判断损失函数Loss值来衡量模型的好与坏,如果损失函数值过大,需要进一步优化模型。优化模型时,需要分析训练过程中所出现的问题,可能是由于 model bias,也可能是由于optimization做的不够好。而本文介绍了在各个情况下,该如何采取优化方法以及解决过拟合的方法。也介绍了一种模型评估方法,N-fold交叉验证帮助我们选择一个适中的模型,既不容易出现过拟合现象,也不会因为optimization做的不好,从而导致模型过差。在梯度下降过程中,当梯度为0时,模型参数无法继续更新,这是由于此时梯度为0的点为局部最小点或鞍点。
Abstract
In the machine learning training model, the good and bad of the model are measured by judging the Loss function value. If the loss function value is too large, the model needs to be further optimized. When optimizing the model, it is necessary to analyze the problems in the training process, which may be due to model bias or not good enough optimization. This paper introduces how to adopt the optimization method and solve the overfitting method in each case. A model evaluation method is also introduced. N-fold cross-validation helps us to choose a moderate model, which is not prone to overfitting phenomenon, nor will it lead to poor model due to poor optimization. In the process of gradient descent, when the gradient is 0, the model parameters cannot be updated because the point where the gradient is 0 is the local minimum point or the saddle point.
一、机器学习任务攻略
在训练深度学习模型时,根据Training Data的Loss值来判断模型问题所在。
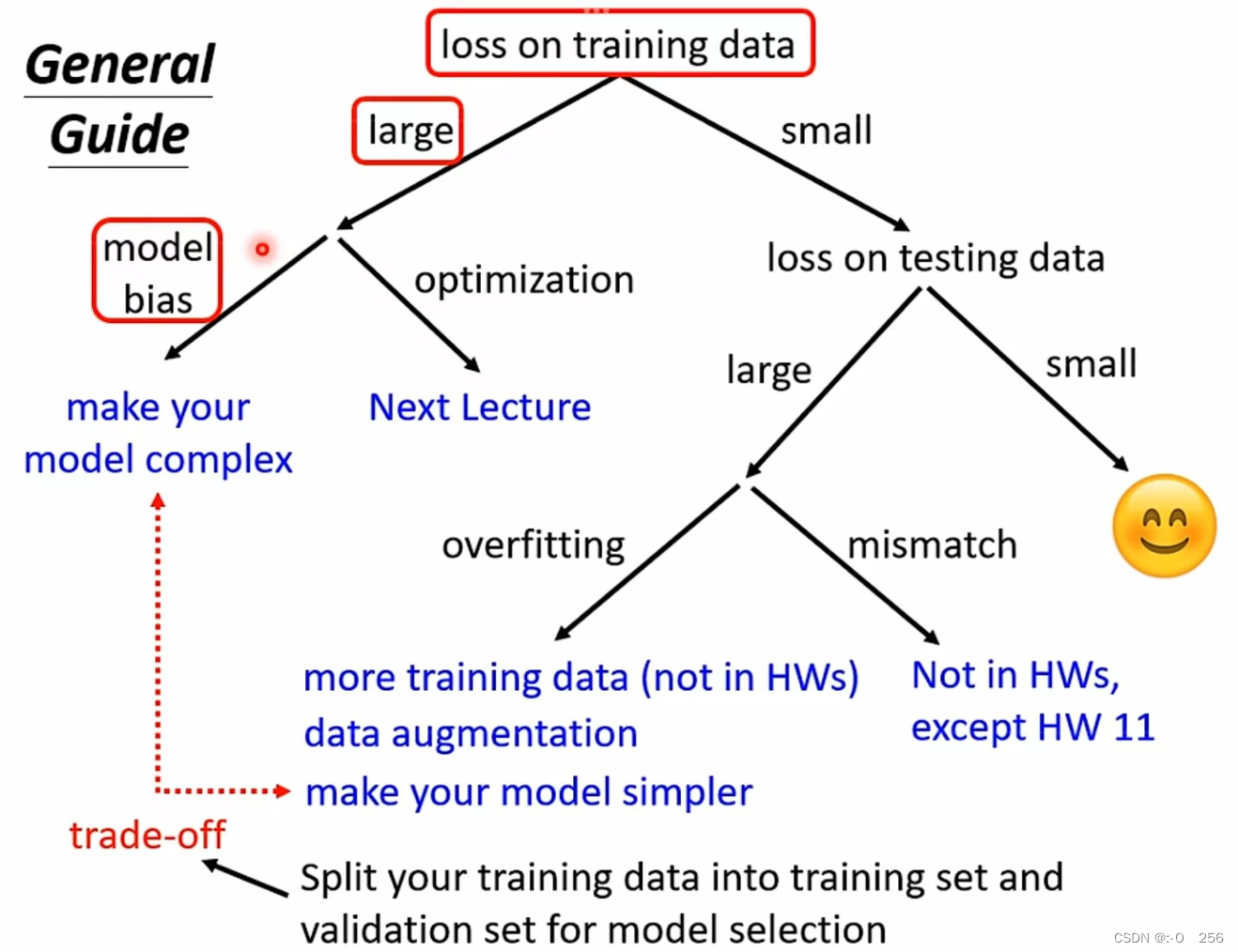
1.1 训练数据的loss偏小
训练数据loss偏大,一般是一下两个问题导致的:
①模型的bias问题
Model Bias的原因模型过于简单,弹性不够大,包括的范围太小,需要重新设计一个弹性更大的、更复杂的Model。
②模型优化过程的问题
Optimization Issue,即在梯度下降的时候出现了问题。梯度下降算法需要选择合适的学习率,过小的学习率会导致收敛速度缓慢,而过大的学习率会使得算法无法收敛到最优值。局部最优解:梯度下降算法容易陷入目标函数的局部最优解,而无法找到全局最优解,从而降低了训练模型的性能。鞍点问题:在高维空间中,目标函数可能存在多个局部最小值和鞍点,梯度下降算法容易停留在鞍点附近,从而无法快速找到全局最小值。
1.2 怎么判断是Model Bias还是Optimization Issue?
我们可以首先训练一些比较简单的model,层数比较少的神经网络,通过训练这种model和网络,观察我们可以得出的loss结果。接下来,我们可以训练一些比较复杂的model和层数多的神经网络。如果二者对比,发现复杂的model得出的loss值比简单model得出的loss值明显大很多,那就说明对于复杂model而言,optimization存在问题,无法找出让loss值最低的一组参数。
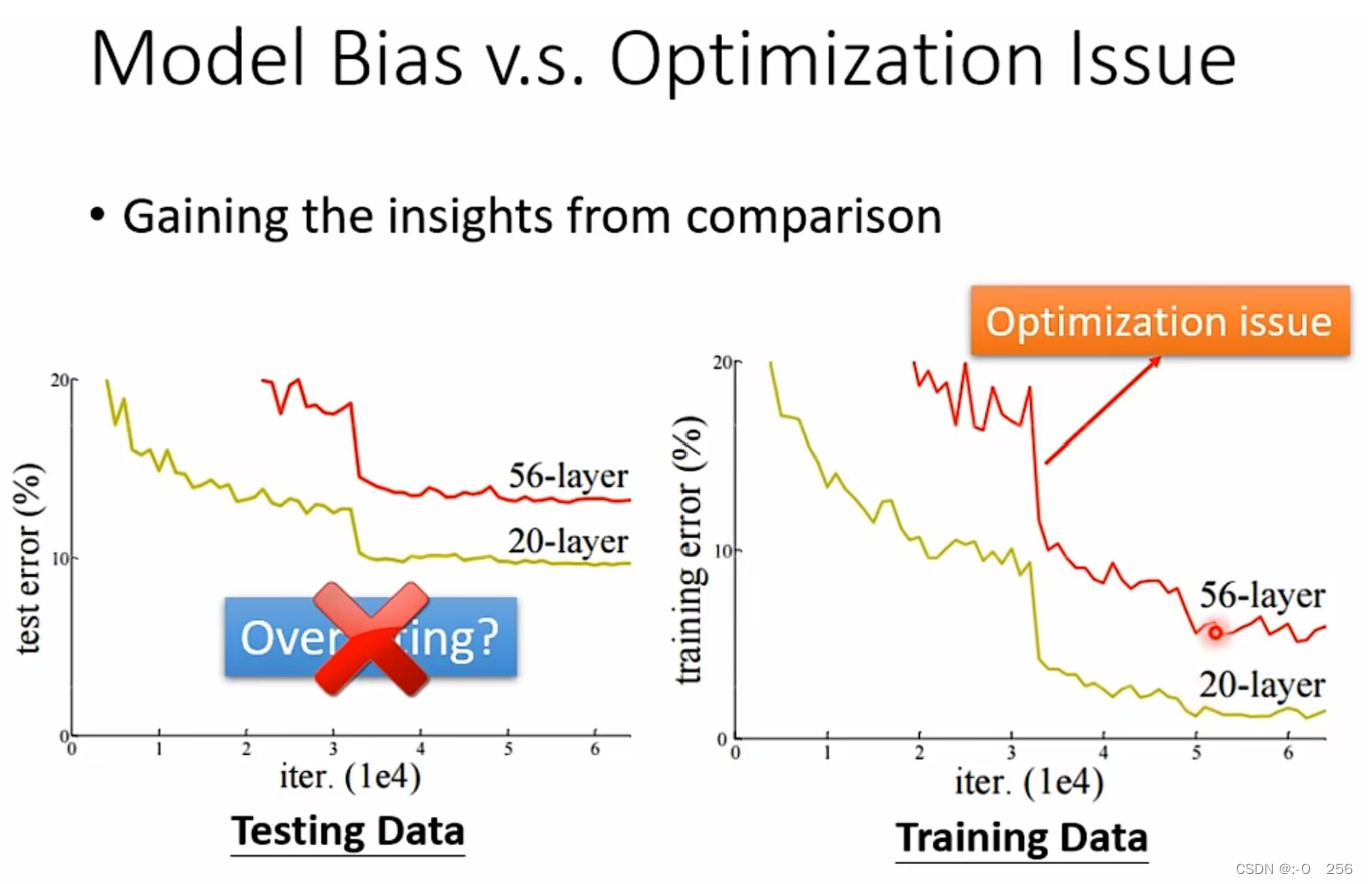
例如我们有两个神经网络,一个神经网络是56层,一个神经网络是20层,将它们均用在Testing data(测试数据集)上。但是训练结果,20层神经网络的误差比较低,56层神经网络的误差比较高,可能有人会认为出现这种状况是由于过拟合。我们不能通过训练Testing data的好坏去判断这就是过拟合导致的,我们需要检查一下模型在Training data上的结果,结果显示,在训练数据上的结果20层神经网络的误差仍然比较低,56层神经网络的误差仍然很高。这种现象说明56层的神经网络并没有做好optimization。
1.3 训练数据的loss偏小
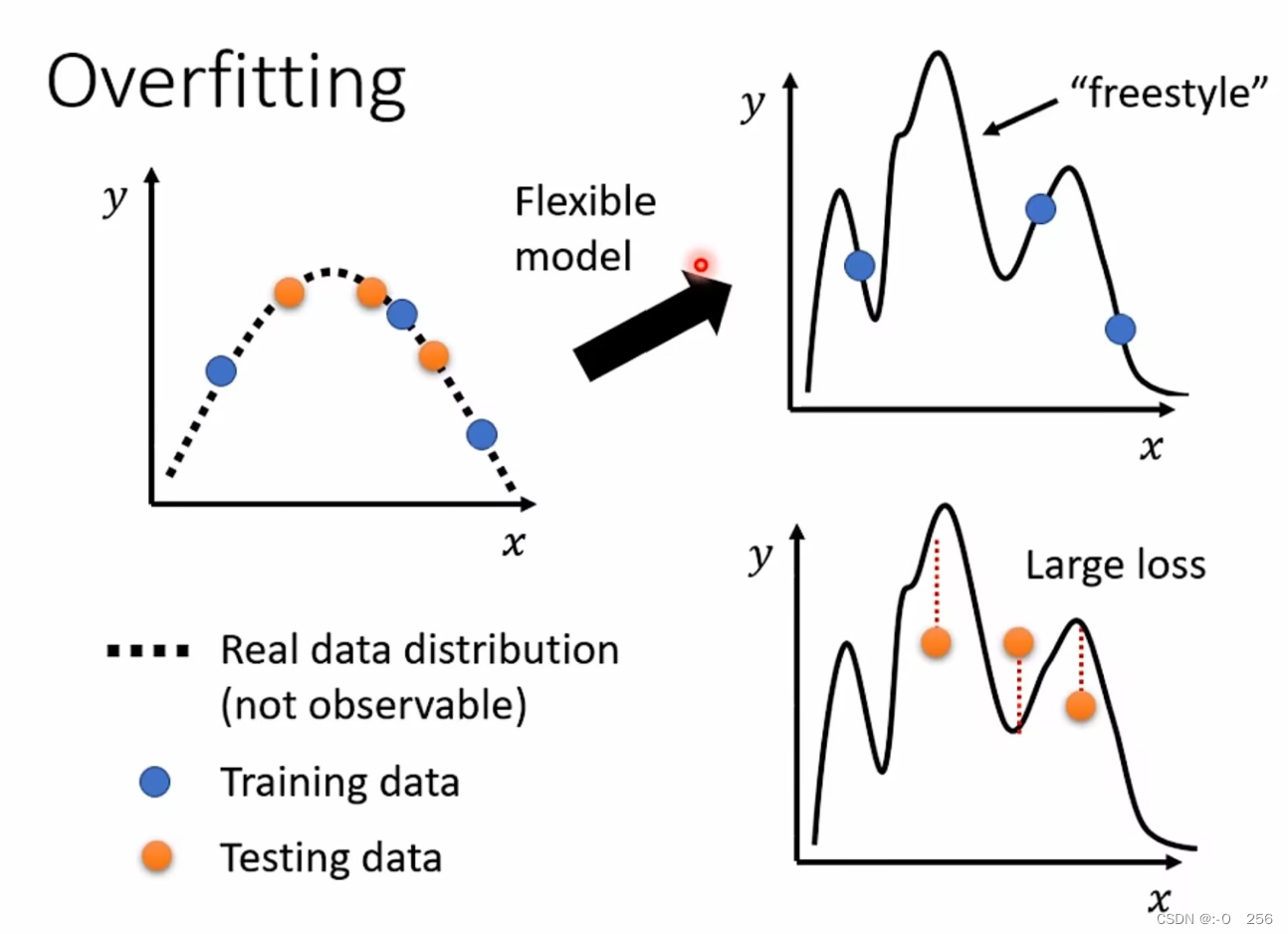
训练数据的loss值小时,我们分析测试数据的loss值,当loss偏大时,即出现过拟合情况。原因是如果模型的弹性太大,在训练集之外的地方“自由度”太高,就会导致模型在测试集上的结果很差,如图所示,利用蓝色的点找出一个function,测试在黄色的点上结果不是很好,因为model的自由度很大,它会产生很奇怪的曲线,导致训练资料上结果好,但是测试资料上的结果不好,蓑在测试数据产生较大误差。
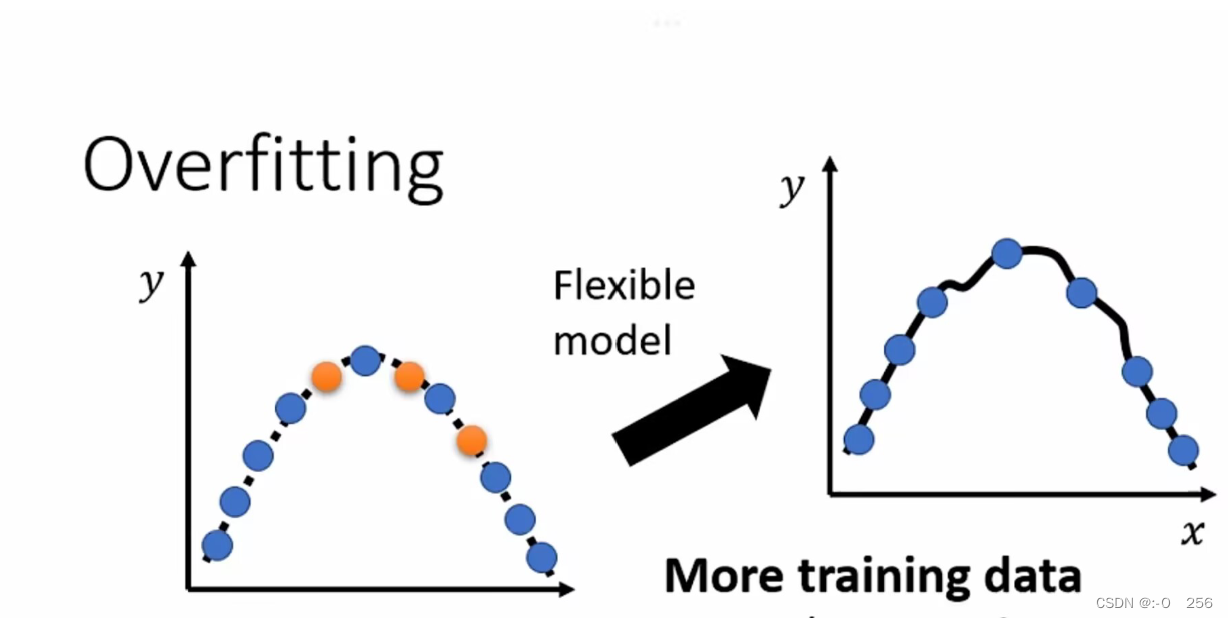
解决过拟合最简单方式便是增加训练数据
但是如果直接增加训练数据,需要的数据量过大。所以我们可以使用 “数据增强”来代替,规避去网络上大量收集资料的过程,可以通过对目前所做案例的理解,去创造训练数据。比较常用的数据增强方法主要有:翻转,旋转,裁剪,缩放,平移,抖动。
如图蓝色的点增多,模型的自由度就会受到限制,产生的曲线就会接近预期的曲线,测试结果就会好很多。
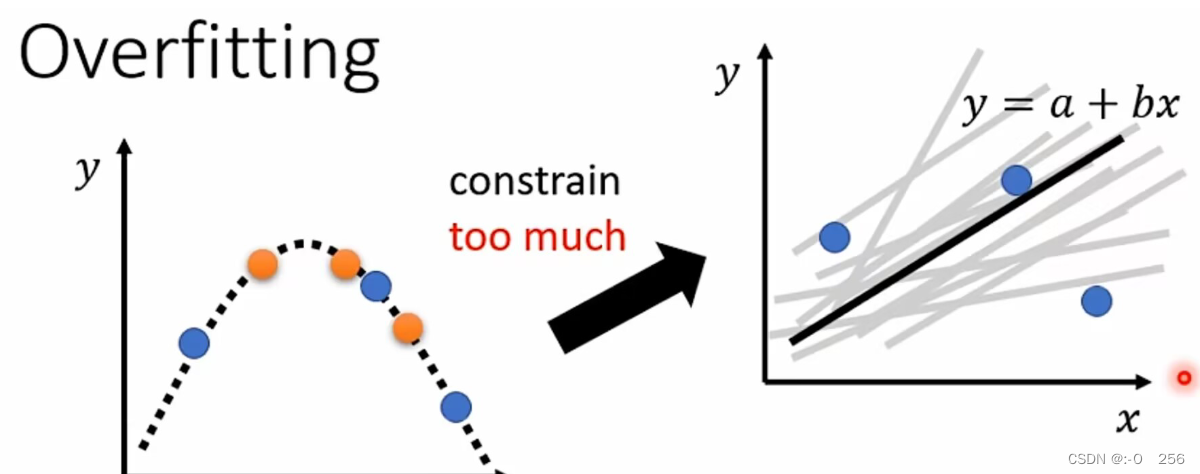
解决Overfitting的另一个方法就是:限制模型的弹性
例如限制模型为一个一元二次方程,那么图形的可能性就很少,找到刚好契合的那一种的几率就会增大。制造限制的方法:减少参数、共有参数、更少的特征值、Early stopping——提前终结、egularization——泛化、Dropout——增加鲁棒性。
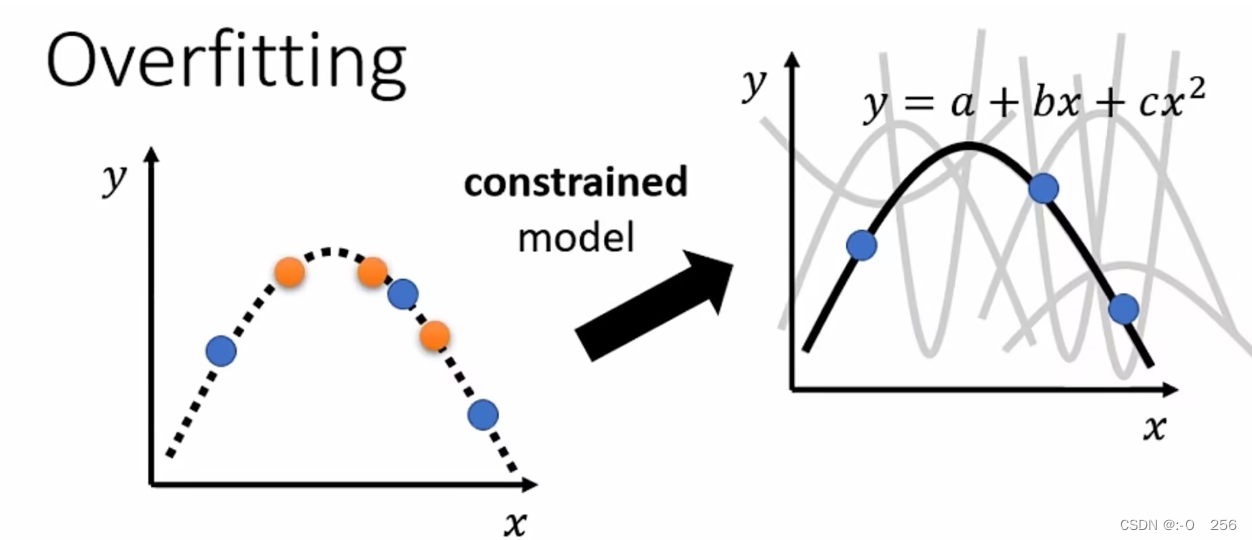
限制也不能太大,否则又会回到Model Bias问题,例如对于图中的训练集,怎么也找不到一条直线可以同时经过这三个点。
模型复杂度与误差的曲线大致如下:
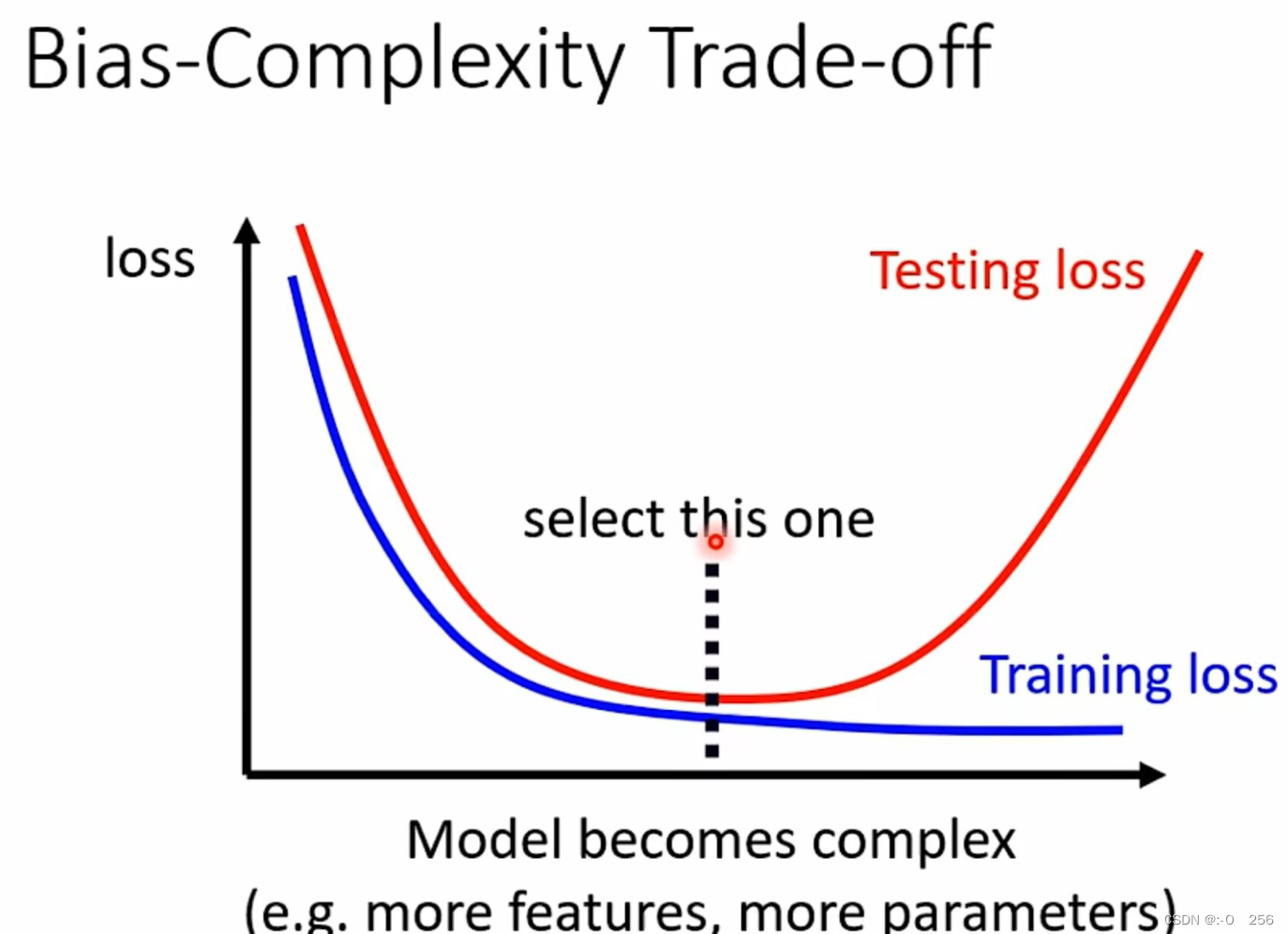
总结:模型过于简单会导致Model Bias问题,模型过于复杂又回到过拟合问题。所以要选择一个合适复杂度的Model。
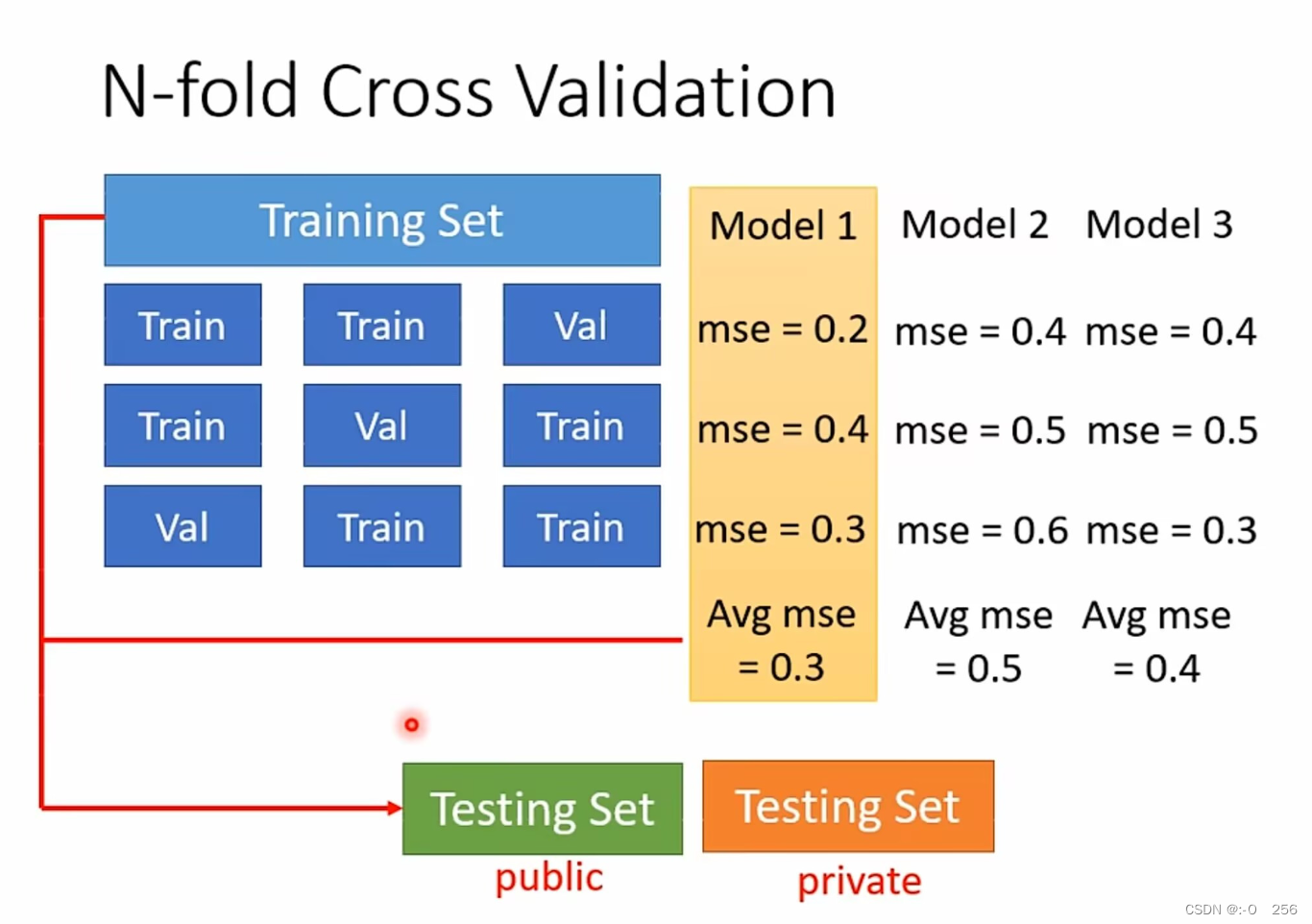
N-fold交叉验证(N-fold Cross Validation)是一种常用的模型评估方法,它将数据集分割成N份,其中N-1份用于训练模型,另外1份用于测试模型,不断重复以上过程直到所有的子集都被用于测试。通过对不同训练子集上的训练和测试结果的平均得分来评估算法性能。这种方法可以更准确地验证一个模型的性能,因为它使用了数据集中的所有子集进行训练和测试。它也可以更好地应对过拟合的问题,因为多次训练和测试模型能够减小一组数据集对模型性能评估的影响。
如下举例子,给出三个模型,在不知道哪个模型更好的情况下,将这三个模型在这三组Set下统统跑一次,把这三个模型在这三组Set下的结果计算平均值,看看谁的结果最好,在给出的例子中Model1的结果是最好的,因此将Model1用在全部的Training Set上,然后训练出来的模型,再用在Testing Set上面。
二、局部最小值与鞍点
(1)局部最小值(local minima)。如果是卡在local minima,那可能就没有路可以走了,因为四周都比较高,你现在所在的位置已经是最低的点,loss最低的点了,往四周走 loss都会比较高,你会不知道怎么走到其他地方去。
(2)鞍点(saddle point)。(如图可看出,左右是比红点高,前后比红点低,红点既不是local minima,也不是local maxima的地方)如果是卡在saddle point,saddle point旁边还是有其他路可以让你的loss更低的,你只要逃离saddle point,你就有可能让你的loss更低。
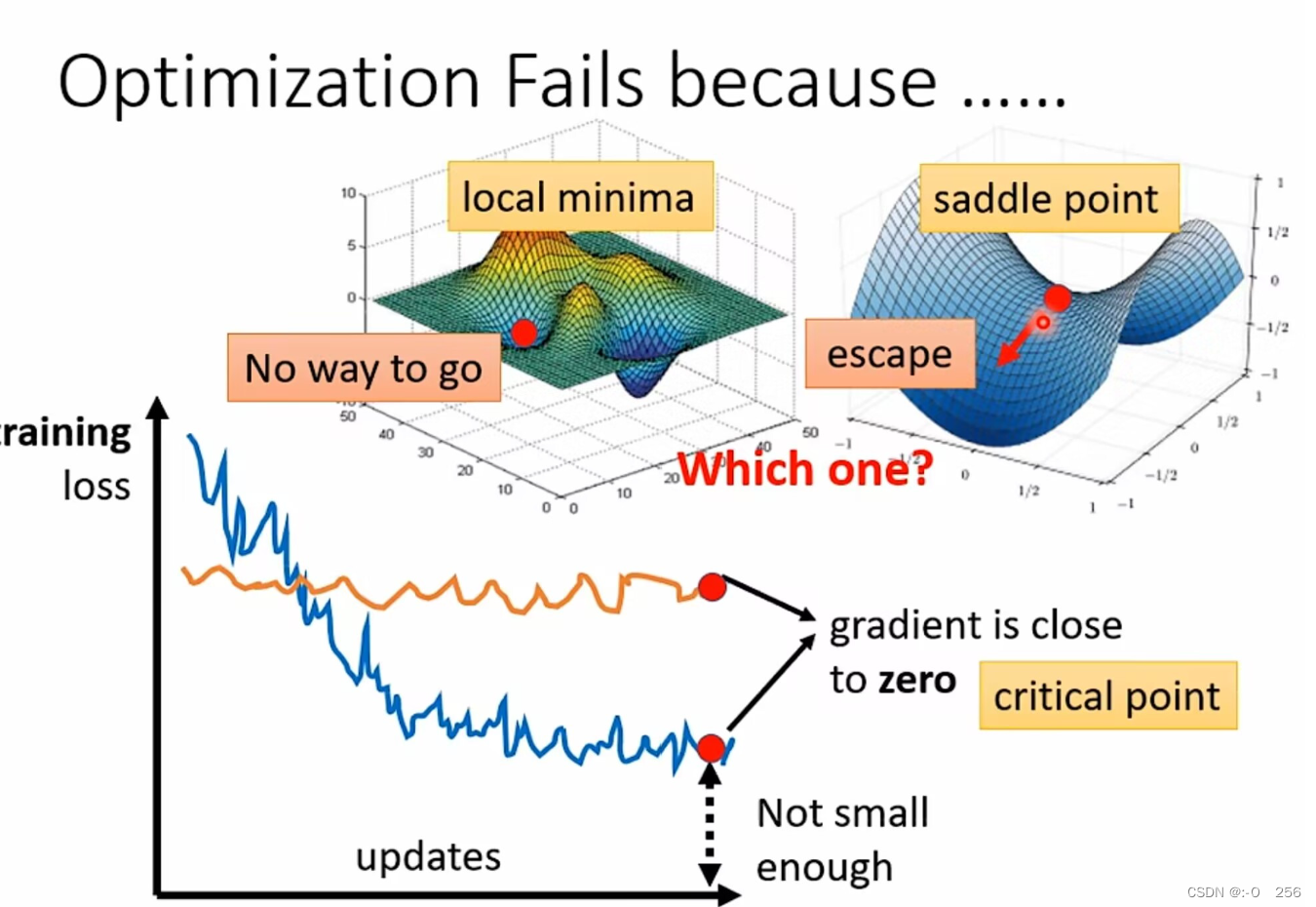
2.1 判断梯度为0的点是局部最小点还是鞍点?

2.3鞍点处继续优化参数
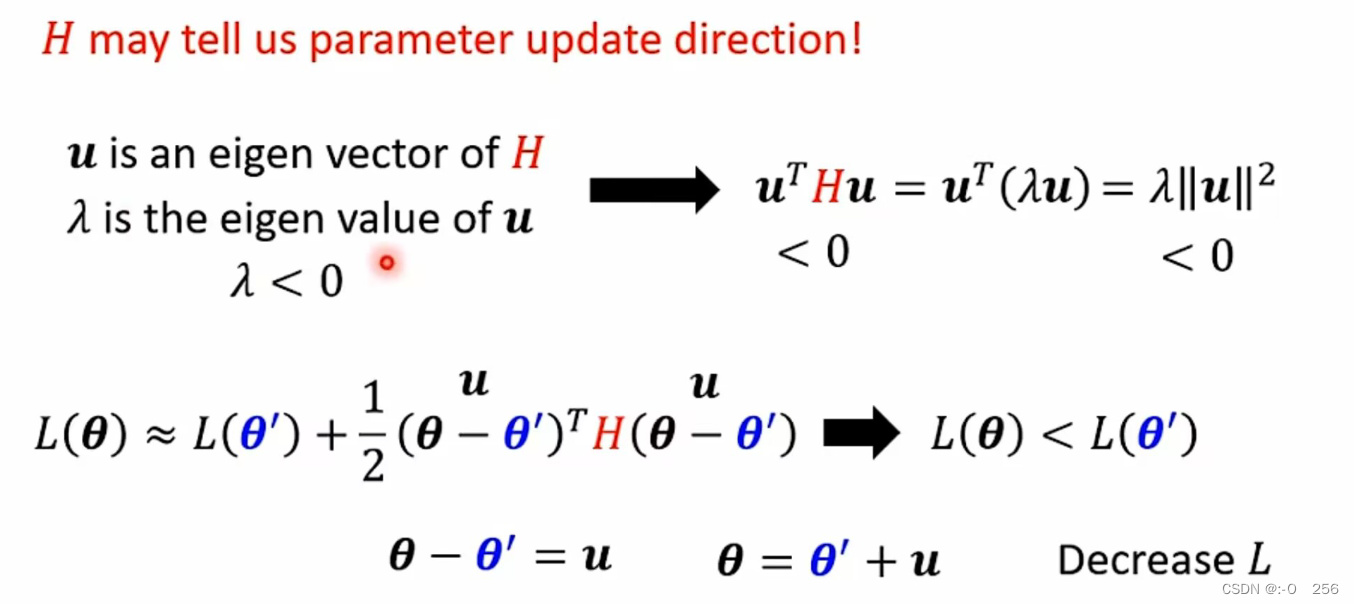
v是H的一个特征向量,λ是H的特征值,因此可以将v^THV进行变形,变形之后的公式正负就取决于的λ值。由于鞍点处的H既非正定也非负定,因此同时存在正特征值和负特征值。当λ<0,即对负特征值来说,在的θ‘方向加上v,沿着函数的方向更新参数θ,就能够让loss值下降; 当λ>0,即对正特征值来说,函数在它对应特征向量方向上上升。
2.4 鞍点例子

如果我们在鞍点处,想要减少模型的Loss值,我们只需要计算在鞍点处的 H 矩阵的负特征值λ ,再找出负特征值对应的特征向量u ,然后让这个负特征值对应的特征向量 u 与θ’ 相加,最终得到更新后的 θ。此时我们的参数也就更新了,即模型在鞍点处又进一步更新了参数,降低了Loss值。实际过程中,我们往往很难将Hassion矩阵表示出来,Hassion矩阵中的值都是二阶偏导数值,因为计算量十分大。
总结
局部最小点(local minima)并没有那么常见,因此在大多数情况下,你train到一个位置时,你的gradient已经很小了,于是你的参数就不会再更新了,这个时候就是因为你卡在一个鞍点(saddle point)。















 99
99











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









