







when gradient is small…
一、为什么Optimization会失败?
1.1 local minima 局部最小值

1.2 saddle point 鞍点
一个不是局部最小值的驻点(一阶导数为0的点)称为鞍点。沿着马脊背方向是稳定的,是极小值,但沿着左右方向,是极大值。例如,函数y=x^3就有一个鞍点在原点,在鞍点的一次导数等于零,二次导数换正负符号。
- 在微分方程中,指沿着某一方向是稳定的另一条方向是不稳定的奇点。
- 在泛函中,指既不是极大值点也不是极小值点的临界点。
- 在矩阵中,一个数在所在行中是最小值而在所在列中是最大值的点。
- 在物理上,指在一个方向是极大值而另一个方向是极小值的点。

这种gradient is close to zero—一阶导数为0,就称critical point驻点
因此,gradient无法下降,也许是因为critical point,但是不能说是卡在local minima .
1.3 如何鉴别
local minima
no way to go, 四周都比较高,现在位置是Loss最低点
saddle point
只要沿着左右方向逃离saddle point, 还是有可能更低的
二、Warning of math
2.1 Tayler Series Approximation
2.1.1 泰勒级数相关
了解Loss function 的形状。由于Loss function非常复杂,我们没法知道整个函数,但是可以知道给定参数θ‘的附近的Loss function的估计。
大一学的泰勒级数当时就没懂,因此在补课时意外发现以下视频,然后收藏了该系列…泰勒公式如下。
https://www.bilibili.com/video/BV1Gx411Y7cz?from=search&seid=13272137787140378575&spm_id_from=333.337.0.0
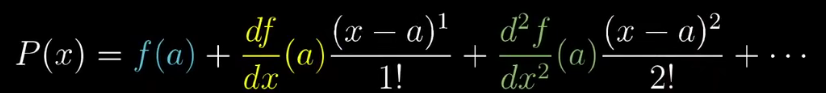
2.1.2 近似函数如下所示。

上图转置的原因可能是因为,θ是一个一维的列向量,g也是一个一维列向量,相乘的话必须将θ转置。
当出现critical point,意味着绿色部分为0(一阶导数为0)。所以,根据红色部分来看地貌长啥样,判断是local min、local max、saddle point.

2.1.3 根据hessian矩阵是否正定来判断。

正定矩阵
https://zhuanlan.zhihu.com/p/119185996
例子——计算hessian


2.2 如何对付saddle point

例子,使用上面那个史上最糟糕的神经网络来逃离鞍点。找到小于0的入,计算出对应的一个特征向量u,即可更新鞍点。但是实际上,由于求二阶导计算量非常复杂,因此很少有人用此方法逃离鞍点。

2.2.1 鞍点和局部最小值出现频率
实际上来看,鞍点的出现频率要高于局部最小值的。如下图所示。Loss处在很高或者很低时,都有可能出现critical point

三、Tips for training:Batch and Momentum
3.1 Optimization with Batch
这里注意一下shuffle,每个batch都训练完了,1 个epoch结束以后,我们会对整个data重新shuffle,得到的每个batch和上一轮是不一样的。

3.2 为什么要用batch?
3.2.1 batch大小比较

大:蓄力时间长,威力比较大 小:等待时间短,乱枪打鸟
比较大的batch size不一定需要花费更多的时间去计算gradient。因为GPU 平行运算的能力使得大小1000的batch和1的batch计算时间不是1000倍的关系。除非当数据真的非常大了。

比较小的batch update一次的时间虽然很短,但是需要更长的时间去跑完一次epoch。

如果只看validation acc可能会认为是过拟合的问题,实际上同时看training acc,整个趋势差不多,因此不是过拟合。而是对于更大的batch,模型的表现力可能会变差。batch过大,可能会使得optimization出现问题。
3.2.2 小的batch会带来更好地结果

为什么在小的batch size会出现更好地结果,“noisy”的update会表现更好?
解释1:不同的batch的Loss函数是不完全一致的,因此也很难在同一个点卡主,降低出现local minima的可能。

解释2(暂代研究):小的batch更倾向于走到平原minima,而大的batch更倾向于走到峡谷minima。实线代表训练集,虚线代表测试集,由于种种原因(可能训练数据和测试数据分布不一样)导致其函数会有些微差别,峡谷minima在面对函数变化时会产生较大的误差。



3.3 动量momentum
考虑物理问题,由于小球具有动量,所以一般的local minima或者saddle minima很难困住小球。

记录一下参数更新步骤。一般情况如下所示。

结合gradient的反方向和前一步的方向综合确定下一步的方向。注意,这里的入和学习率一样是人为设定的参数。

形象表达:
形象表达:
















 1601
1601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









