









链接:https://zhuanlan.zhihu.com/p/24780433
链接:https://www.cnblogs.com/objectDetect/p/5947169.html
在SPP-net中的难点一曾提到:ROI如何对应到feature map?
这个地方遇到不少坑,看了很多资料都没有太明白,感觉太绕。
先数数遇到的坑:
- 《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》原文是这样写的,一脸懵逼。

- 找了张图是这样画的:有那么点意思,好像是从前向后推出各个层的感受野,可是还是不懂为啥这样。

- 这两张图,看的有点摸不着头脑


- 接着找了何凯明在ICCV2015上演讲的PPT:《 iccv2015_tutorial_convolutional_feature_maps_kaiminghe.》,算是有了点眉目。可是还是不造咋回事,只知道有那么个公式,却不知道怎么推出来的,满心的疑惑。

回归正题
最后找到一篇靠谱的文章 卷积神经网络物体检测之感受野大小计算 - machineLearning - 博客园,它给出了一个不错的启发,还附带了代码,最关键的是它给出了参考链接。 于是我终于在参考链接找到了这篇 Concepts and Tricks In CNN(长期更新) 最佳博文,不仅清晰易懂,而且公式详细。(不过感觉略有不足,所以下面就详细介绍一下这个大坑)
【先说说感受野的计算】
回忆一下我之前在 卷积神经网络(CNN)简介 里就曾经画图推导过的一个公式(这个公式很常见,可是竟然很少有人去讲它怎么来的,当时我在写 CNN简介就顺便画图推导了一下,没细看的同学可以回头看看)
原文里提到:隐藏层边长(输出的边长) = (W - K + 2P)/S + 1
(其中 W是输入特征的大小,K是卷积核大小,P是填充大小,S是步长(stride))
为了理解方便我就把公式先用英文写一下:
output field size = ( input field size - kernel size + 2*padding ) / stride + 1
(output field size 是卷积层的输出,input field size 是卷积层的输入)
反过来问你: 卷积层的输入(也即前一层的感受野) = ?
答案必然是: input field size = (output field size - 1)* stride - 2*padding + kernel size
再重申一下:卷积神经网络CNN中,某一层输出结果中一个元素所对应的输入层的区域大小,被称作感受野receptive field。感受野的大小是由kernel size,stride,padding , outputsize 一起决定的。
从Concepts and Tricks In CNN(长期更新) 里截张图你感受一下:

- 对于Convolution/Pooling layer(博文作者忘了加上padding本文在这里补上):
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/46fa1c96aa9a8e9b6f9b2ff97dc48f54.png)
- 对于 Neuronlayer(ReLU/Sigmoid/..) :
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/edacdd950cd5c0bba605e07f1360fb15.png) (显然如此)
(显然如此)
上面只是给出了 前一层在后一层的感受野,如何计算最后一层在原始图片上的感受野呢? 从后向前级联一下就可以了(先计算最后一层到倒数第二层的感受野,再计算倒数第二层到倒数第三层的感受野,依次从后往前推导就可以了)
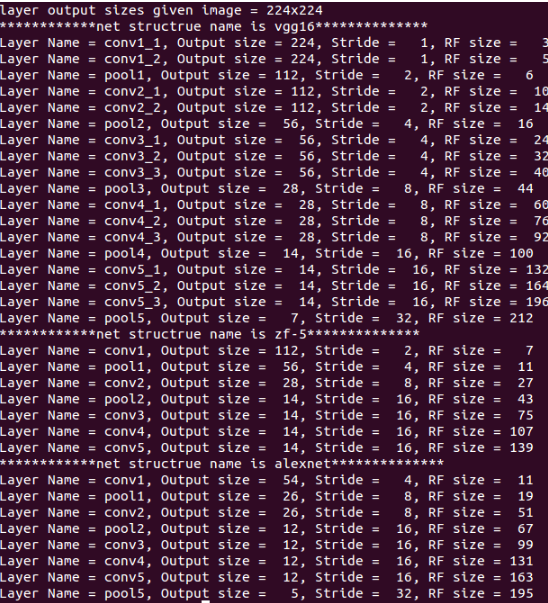
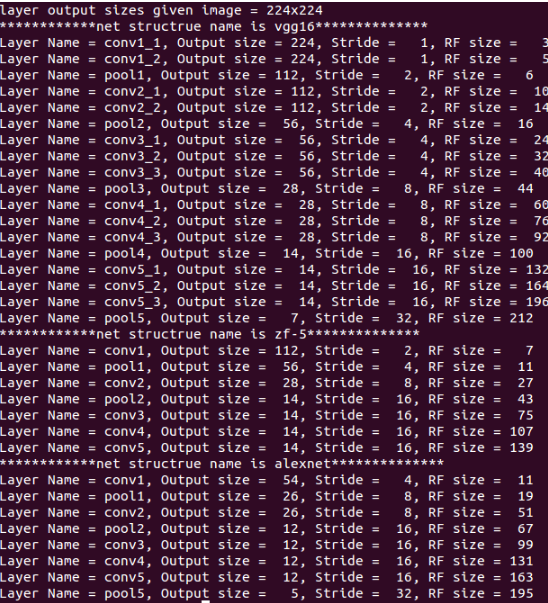
卷积神经网络物体检测之感受野大小计算 - machineLearning - 博客园 中用如下核心代码计算了 Alexnet zf-5和VGG16网络每层输出feature map的感受野大小。
net_struct = {'alexnet': {'net':[[11,4,0],[3,2,0],[5,1,2],[3,2,0],[3,1,1],[3,1,1],[3,1,1],[3,2,0]],
'name':['conv1','pool1','conv2','pool2','conv3','conv4','conv5','pool5']},
'vgg16': {'net':[[3,1,1],[3,1,1],[2,2,0],[3,1,1],[3,1,1],[2,2,0],[3,1,1],[3,1,1],[3,1,1],
[2,2,0],[3,1,1],[3,1,1],[3,1,1],[2,2,0],[3,1,1],[3,1,1],[3,1,1],[2,2,0]],
'name':['conv1_1','conv1_2','pool1','conv2_1','conv2_2','pool2','conv3_1','conv3_2',
'conv3_3', 'pool3','conv4_1','conv4_2','conv4_3','pool4','conv5_1','conv5_2','conv5_3','pool5']},
'zf-5':{'net': [[7,2,3],[3,2,1],[5,2,2],[3,2,1],[3,1,1],[3,1,1],[3,1,1]],
'name': ['conv1','pool1','conv2','pool2','conv3','conv4','conv5']}}
imsize = 224
def outFromIn(isz, net, layernum):#从前向后算输出维度
totstride = 1
insize = isz
for layer in range(layernum):
fsize, stride, pad = net[layer]
outsize = (insize - fsize + 2*pad) / stride + 1
insize = outsize
totstride = totstride * stride
return outsize, totstride
def inFromOut(net, layernum):#从后向前算感受野 返回该层元素在原始图片中的感受野
RF = 1
for layer in reversed(range(layernum)):
fsize, stride, pad = net[layer]
RF = ((RF -1)* stride) + fsize
return RF

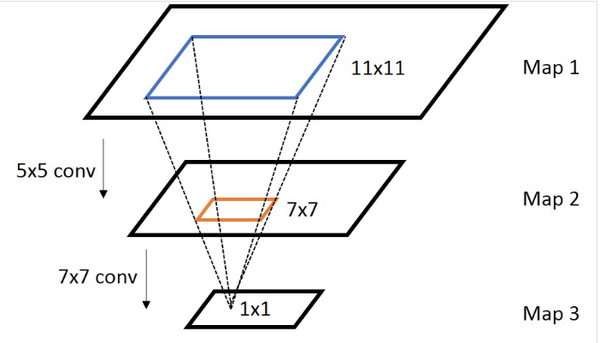
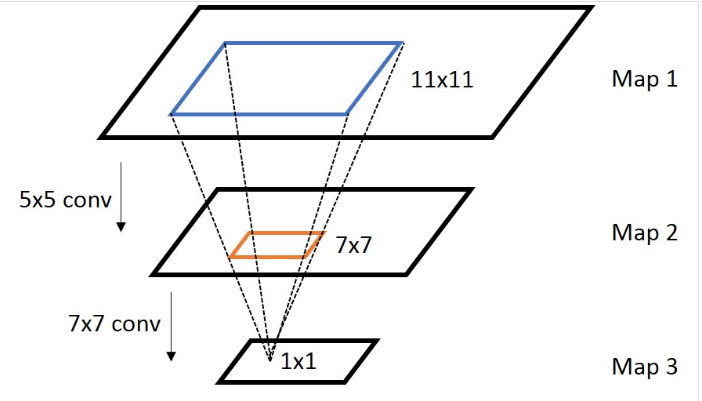
【再谈谈感受野上面的坐标映射 (Coordinate Mapping)】
为了完整性直接摘录博客内容了:
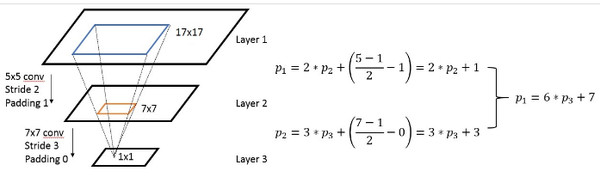
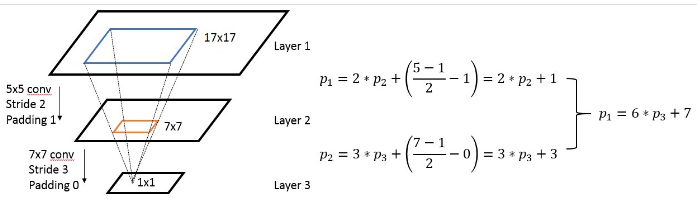
通常,我们需要知道网络里面任意两个feature map之间的坐标映射关系(一般是中心点之间的映射),如下图,我们想得到map 3上的点p3映射回map 2所在的位置p2(橙色框的中心点)

计算公式:
- 对于 Convolution/Pooling layer:
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/667fd79ea37377857456a313d9ca0809.png)
- 对于Neuronlayer(ReLU/Sigmoid/…) :
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/838914020430837a7bdb1f33af5ed44d.png)
上面是计算任意一个layer输入输出的坐标映射关系,如果是计算任意feature map之间的关系,只需要用简单的组合就可以得到,下图是一个简单的例子:

最后说一下 前面那张PPT里的公式。
- 对于上面 A simple solution:其实也是何凯明在SPP-net中采用的方法。其实就是巧妙的化简一下公式 令每一层的padding都为
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/4349906dad82db117e94e8204076cd3d.png)
- 当
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/80b50c697d86c5679fc746282b0e1946.png) 为奇数
为奇数 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/3e6c83d7a10ff622e96bf69b95991d35.png) 所以
所以 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/c5bf7f6f7da13c3c8ddc82a618de30ed.png)
- 当 为偶数
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/4dd5481f421622376669976d89120197.png) 所以
所以 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/c5bf7f6f7da13c3c8ddc82a618de30ed.png+-0.5)
- 而
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/09ddd44d82b13fd61f56d10f53fa5941.png) 是坐标值,不可能取小数 所以基本上可以认为 。公式得到了化简:感受野中心点的坐标只跟前一层
是坐标值,不可能取小数 所以基本上可以认为 。公式得到了化简:感受野中心点的坐标只跟前一层 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/3c6d5befea0ecfbc02fbfacdec21287e.png) 有关。
有关。
- 当
- 对于上面的 A general solution: 其实就是把 公式 级联消去整合一下而已。
<img src=“ https://pic4.zhimg.com/v2-7e30f0972bfb5399436844952f3990b3_b.png” data-rawwidth=“279” data-rawheight=“72” class=“content_image” width=“279”/> 
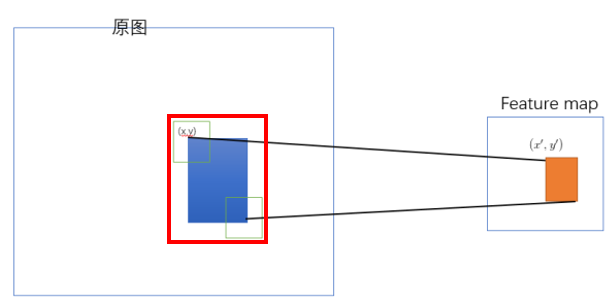
SPP-net的ROI映射做法详解
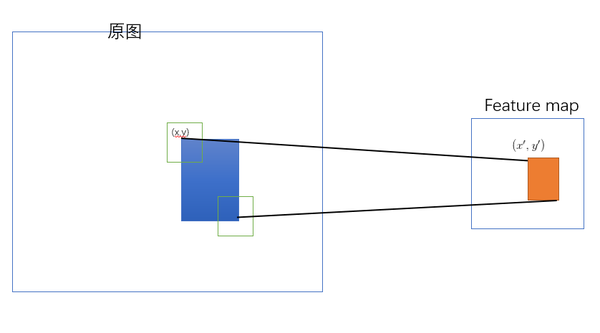
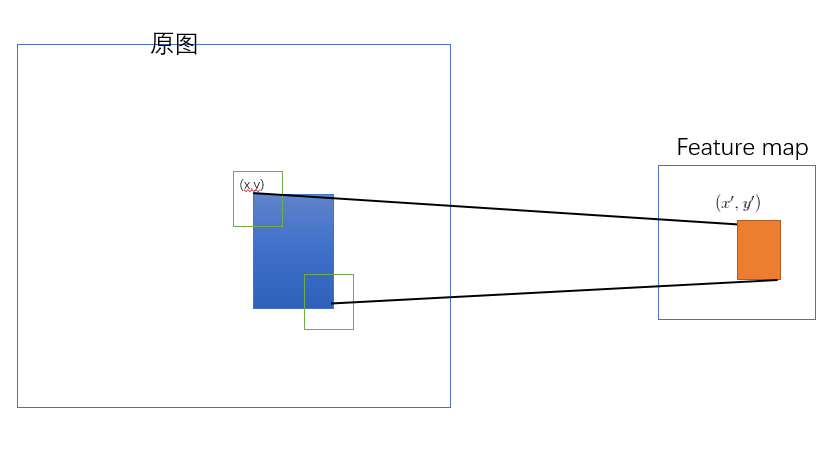
SPP-net 是把原始ROI的左上角和右下角 映射到 feature map上的两个对应点。 有了feature map上的两队角点就确定了 对应的 feature map 区域(下图中橙色)。

如何映射?
左上角的点(x,y)映射到 feature map上的![[公式]](https://i-blog.csdnimg.cn/blog_migrate/454bd8ee4f9098ecc810f6e8996e5210.png) : 使得 在原始图上感受野(上图绿色框)的中心点 与(x,y)尽可能接近。
: 使得 在原始图上感受野(上图绿色框)的中心点 与(x,y)尽可能接近。
对应点之间的映射公式是啥?
- 就是前面每层都填充padding/2 得到的简化公式 :
- 需要把上面公式进行级联得到
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/51c0c45f78f1bef00f941b2280031b63.png) 其中
其中 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/d2fde4c380a39ec20f71443ca09b008f.png)
- 对于feature map 上的 它在原始图的对应点为
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/43efb4a12e9fa2a8ff604a38625646d0.png)
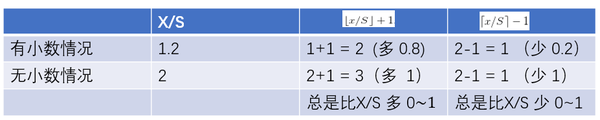
- 论文中的最后做法:把原始图片中的ROI映射为 feature map中的映射区域(上图橙色区域)其中 左上角取:
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/727c2855137cb4bc2786b44ccceccbe4.png) , ;右下角的点取: 界取y’的x值:
, ;右下角的点取: 界取y’的x值:![[公式]](https://i-blog.csdnimg.cn/blog_migrate/cbcf97c19564ba87ca7c853d9cb8730f.png) 。 下图可见
。 下图可见 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/603c55ee7cf3a7f804d14e435370ecf1.png) ,
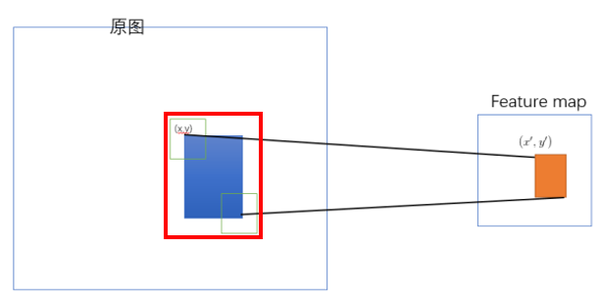
, ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/f96c43d8c0ab40e447565e69cada766f.png) 的作用效果分别是增加和减少。也就是 左上角要向右下偏移,右下角要想要向左上偏移。个人理解采取这样的策略是因为论文中的映射方法(左上右下映射)会导致feature map上的区域反映射回原始ROI时有多余的区域(下图左边红色框是比蓝色区域大的)
的作用效果分别是增加和减少。也就是 左上角要向右下偏移,右下角要想要向左上偏移。个人理解采取这样的策略是因为论文中的映射方法(左上右下映射)会导致feature map上的区域反映射回原始ROI时有多余的区域(下图左边红色框是比蓝色区域大的)
<img src=“ https://pic4.zhimg.com/v2-09c3f5fbb3eeccc6af58d5a5bf8e00c3_b.png” data-rawwidth=“927” data-rawheight=“186” class=“origin_image zh-lightbox-thumb” width=“927” data-original=“ https://pic4.zhimg.com/v2-09c3f5fbb3eeccc6af58d5a5bf8e00c3_r.jpg”/> 


参考:
《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
Concepts and Tricks In CNN(长期更新)
卷积神经网络物体检测之感受野大小计算 - machineLearning - 博客















 2387
2387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
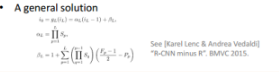{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}