








 超级会员免费看
超级会员免费看


 本文介绍了一个利用VBA宏批量提取Word文档批注信息的工具,旨在提高文档质量检查效率。通过VBA可以获取批注的详细信息,包括路径、页码、内容、作者、时间和解决状态,并可选择只抓取未解决批注,最终整理成Excel表格。
本文介绍了一个利用VBA宏批量提取Word文档批注信息的工具,旨在提高文档质量检查效率。通过VBA可以获取批注的详细信息,包括路径、页码、内容、作者、时间和解决状态,并可选择只抓取未解决批注,最终整理成Excel表格。
前言
关于word文档的工具,之前做过这个:
这个工具在我设想中的是用来在项目的后期检查文档中是否还有TBD/TODO这类关键词未清理,检查文档的完成状态。而后,继续探索对于文档质量检查的工具,于是我发现我们很多文档的review是通过批注完成的(当然也有借助网站的),而这些批注的待解决状态并不是非常的直观:

尤其是文档较长的时候,需要一条一条的过(当然了,word里也支持跳到下一个未解决)。如果只有一个文档还好,如果你作为交付负责人,要负责许多文档的交付质量时,一个文档一个文档的看肯定是不现实的,因此我觉得有必要做这样一个统计归档的工具。当然,已经有review网站或者平台做了这种事情,所以我这个工具主要是作为练手,或者是没买这类平台的人。
终极构想
图形化界面操作:
1.选取目录,之后递归得到所有word文档;
2.对每一个word文档,抓取所有的批注,包括文档路径、批注页码、行号、批注内容、原文、批注者、批注时间、批注解决状态,其中批注解决状态是需要的核心信息;
3.设置选项,可以只抓取未解决的批注;
4.抓取成功后将信息整理到需要的excel文档中,以供评审。
抓取批注信息
python抓取批注
最开始我想的是用python来抓取docx里的批注信息,也仿写了代码:
def docx_comments_get(file):
document = ZipFile(file)
xml = document.read("word/comments.xml")
wordObj = BeautifulSoup(xml.decode("utf-8"), features="xml")
texts = wordObj.findAll("w:t")
for text in texts:
print(text.text)
pass
def main():
docx_comments_get("D:\MyWork\python\测试文档.docx")但是发现这样做只能抓取批注内容,对于其他的信息很难获取,即使打开了docx里comments.xml源文件,里面的内容也很有限:

其他的信息就散落在他的xml文件里,我的确是不太会处理。所以通过python去提取批注的完整信息这条路基本就走不通了。
VBA抓取批注
于是我就转换了一个方向,通过VBA来获取内部的批注信息,微软自己的工具对word的支持应该做的不能差吧。继续这个方向发现确实,VBA可以把一个word内部的批注信息提供的非常完善。通过word的开发工具进入visual basic的编程界面,开始编写宏文件。
下面是我最终的宏代码:
Public Sub exportWordComments_Click()
FileName = Application.ActiveDocument '文件名.docx
varResult = VBA.Split(FileName, ".")
FileNameStr = varResult(0) '去除后缀的文件名
Path = Application.ActiveDocument.Path
FilePath = Path & "\" & FileName '当前文件的完整路径
LogPath = Path & "\" & FileNameStr & "_comments.txt" '批注信息的输出目录
'Debug.Print (FilePath)
If FileName = "False" Then
Exit Sub
End If
Rows = ActiveDocument.Comments.Count '总的批注数量
'Debug.Print (Rows)
Open LogPath For Output As #1 '输出txt文件
Print #1, "==================================================="
For i = 1 To Rows
PageNumber = ActiveDocument.Comments(i).Scope.Information(wdActiveEndPageNumber) '批注在第几页
CharacterLineNumber = ActiveDocument.Comments(i).Scope.Information(wdFirstCharacterLineNumber) '批注在这页的第几行
Scope = ActiveDocument.Comments(i).Scope '批注原文
ScopeComment = ActiveDocument.Comments(i).Range '批注内容
ScopeDate = ActiveDocument.Comments(i).Date '批注时间
ScopeAuthor = ActiveDocument.Comments(i).Contact '批注作者
ScopeDone = ActiveDocument.Comments(i).Done '批注是否被解决
'Debug.Print ("原文:" & ActiveDocument.Comments(i).Scope) '原文
'Debug.Print (ActiveDocument.Comments(i).Done)
'Debug.Print (ActiveDocument.Comments(i).Contact)
'Debug.Print (ActiveDocument.Comments(i).Creator)
'Debug.Print (ActiveDocument.Comments(i).Date)
'Debug.Print (ActiveDocument.Comments(i).Index)
'Debug.Print (ActiveDocument.Comments(i).Parent)
'Debug.Print (ActiveDocument.Comments(i).Reference)
'Debug.Print ("批注内容:" & ActiveDocument.Comments(i).Range) '批注内容
'Debug.Print (ActiveDocument.Comments(i).IsInk)'是否包含链接
Print #1, "文件:" & FilePath
Print #1, "页:" & PageNumber
Print #1, "行:" & CharacterLineNumber
Print #1, "原文:" & Scope
Print #1, "批注:" & ScopeComment
Print #1, "日期:" & ScopeDate
Print #1, "批注者:" & ScopeAuthor
Print #1, "是否解决:" & ScopeDone
Print #1, "==================================================="
Next
Print #1, ""
Close #1
End Sub执行宏命令后,会在word的目录下出现一个 文件名_comments.txt 文件,打开文件可以看到如下信息:
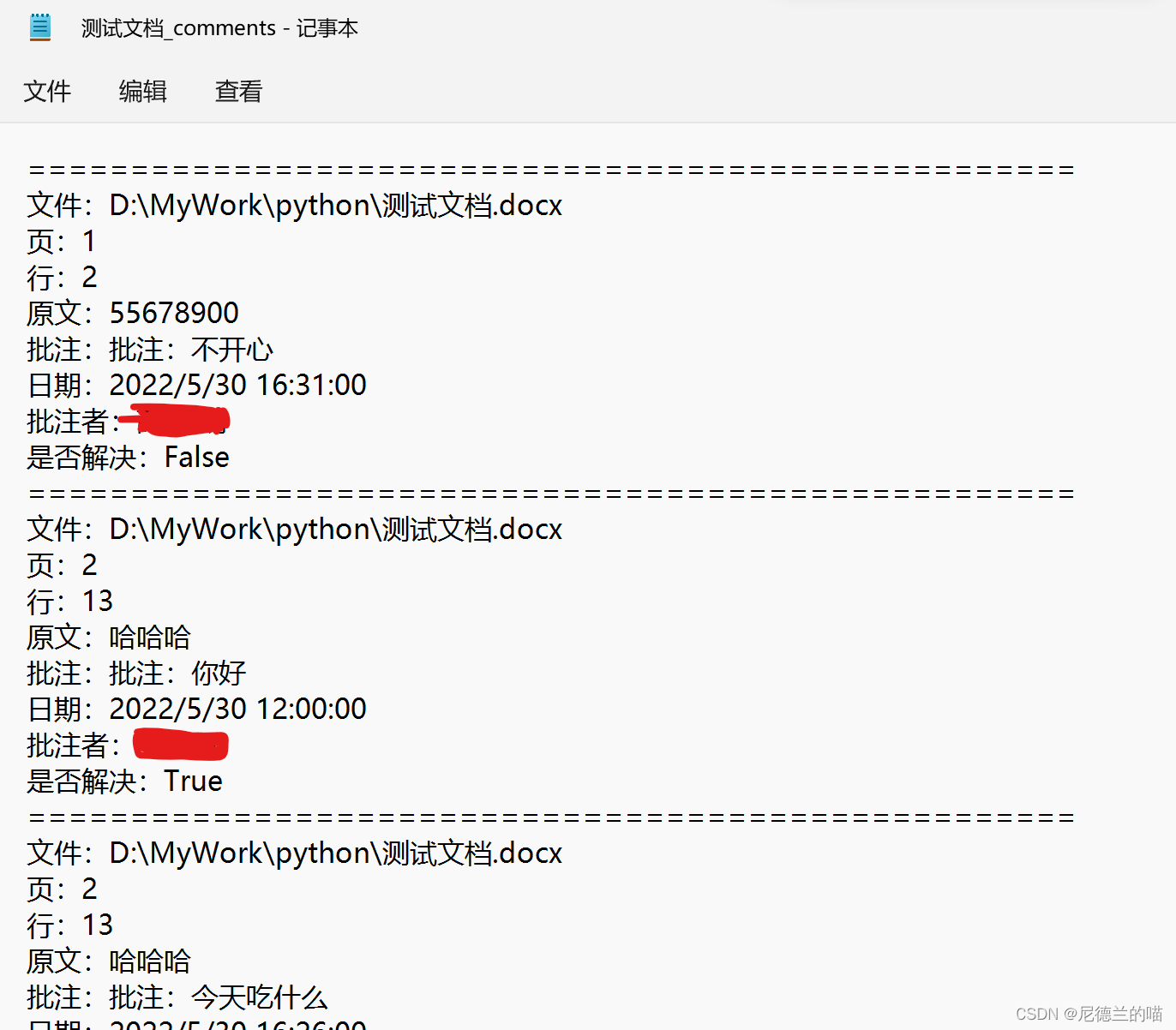
后记
最关键的第一步打通之后,接下来就是通过python递归所有带处理文件,对每一个文件调用宏生成txt,整理所有txt为excel表,对整个程序做图形界面以便使用。
请待后续~


















 794
794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











