







Introducing gcloud storage
up to 94% faster data transfers for Cloud Storage
Cloud Storage customers often ask us about the fastest way to ingest and retrieve data from their buckets. Getting the best performance often requires the users to know the right flags and parameters to optimize transfer speeds. In many situations, customers are using Cloud Storage with other Google Cloud services and are looking for one tool that can be used to manage all their Google Cloud assets.
Introducing gcloud storage - the latest addition to the Google Cloud CLI
The Google Cloud CLI (a.k.a., gcloud CLI) can be used to create and manage Google Cloud resources and services directly on the command line or via scripts. Gcloud storage is the newest addition to this set, which modernizes the CLI experience for Cloud Storage.
Data Transfer Performance
Data transfer rates are important to customers as they determine the rate of utilization of data to gain useful insights for their business. The new gcloud storage CLI offers significant performance improvements over the existing gsutil option which is a Python application that lets you access Cloud Storage via CLI.
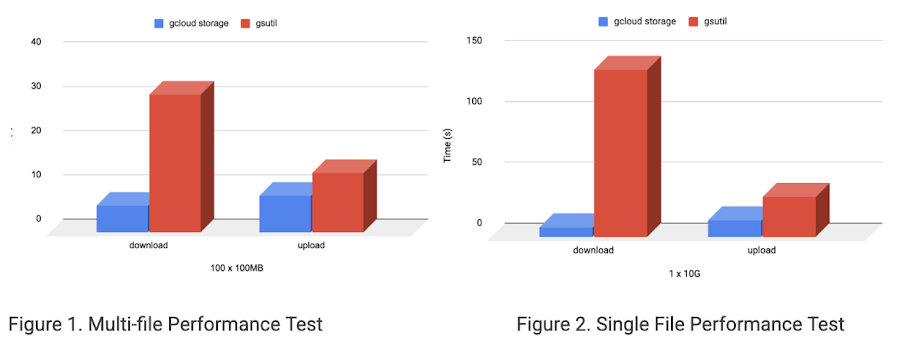
To demonstrate the performance difference between gsutil and the gcloud storage option, we tested single and multi-file scenarios. When transferring 100 files that were 100MB in size, gcloud storage is 79% faster than gsutil on download and 33% faster on upload using a parallel composite upload strategy. See Figure 1. With a 10GB file, gcloud storage is 94% faster than gsutil on download and 57% faster on upload. See Figure 2. These tests have been performed on Google Cloud Platform using n2d-standard-16 (8 vCPUs, 32 GB memory) and 1x375GB NVME in RAID0 in us-east4.
Faster transfer rates are a result of two primary innovations in gcloud storage. First, gcloud storage uses faster hashing tools for CRC32C data integrity checking that skip the complicated setup required for gsutil. Second, it utilizes a new parallelization strategy that treats task management as a graph problem, which allows more work to be done in parallel with far less overhead.
Improved usability
In addition to the performance improvements gcloud CLI provides, it also provides a consistent way to manage all Google Cloud resources like Cloud Storage buckets, Compute Engine VMs, and Google Kubernetes Engine clusters.
gcloud storage automatically detects optimal settings and speeds up transfers without requiring any flags from the users. In gcloud storage, all operations happen in parallel. As an example, parallel composite uploads are enabled automatically based on bucket configuration. This is a vast improvement compared to gsutil, which requires the -m (parallel operations) flag to improve the performance for uploads and downloads.
gcloud storage significantly reduces the number of top level commands that users have to manage their Cloud Storage resources. This is achieved by grouping commands under common headers - all bucket operations are grouped under gcloud storage buckets <command> and all object ops are grouped under gcloud storage objects <command>.
The transition to gcloud storage CLI is simple because we have introduced a shim that enables existing gsutil scripts to be executed as gcloud storage. This allows you to get all the performance benefits of the new CLI without having to rewrite any existing gsutil scripts for Cloud Storage.
Enabling gcloud storage
gcloud storage CLI is currently available and you can use it without any additional charges. You may install or upgrade to the latest version of the Google Cloud SDK to get the new CLI. To learn more about the gcloud storage CLI, please refer to the documentation here.
gcloud storage cp
NAME
gcloud storage cp - upload, download, and copy Cloud Storage objects
SYNOPSIS
gcloud storage cp [SOURCE …] DESTINATION [--additional-headers=HEADER=VALUE] [--all-versions, -A] [--no-clobber, -n] [--content-md5=MD5_DIGEST] [--continue-on-error, -c] [--daisy-chain, -D] [--do-not-decompress] [--manifest-path=MANIFEST_PATH, -L MANIFEST_PATH] [--preserve-posix, -P] [--print-created-message, -v] [--read-paths-from-stdin, -I] [--recursive, -R, -r] [--skip-unsupported, -U] [--storage-class=STORAGE_CLASS, -s STORAGE_CLASS] [--canned-acl=PREDEFINED_ACL, --predefined-acl=PREDEFINED_ACL, -a PREDEFINED_ACL --[no-]preserve-acl, -p] [--gzip-in-flight=[FILE_EXTENSIONS,…], -j [FILE_EXTENSIONS,…] | --gzip-in-flight-all, -J | --gzip-local=[FILE_EXTENSIONS,…], -z [FILE_EXTENSIONS,…] | --gzip-local-all, -Z] [--ignore-symlinks | --preserve-symlinks] [--decryption-keys=[DECRYPTION_KEY,…] --encryption-key=ENCRYPTION_KEY] [--cache-control=CACHE_CONTROL --content-disposition=CONTENT_DISPOSITION --content-encoding=CONTENT_ENCODING --content-language=CONTENT_LANGUAGE --content-type=CONTENT_TYPE --custom-time=CUSTOM_TIME --clear-custom-metadata | --custom-metadata=[CUSTOM_METADATA_KEYS_AND_VALUES,…] | --remove-custom-metadata=[METADATA_KEYS,…] --update-custom-metadata=[CUSTOM_METADATA_KEYS_AND_VALUES,…]] [--if-generation-match=GENERATION --if-metageneration-match=METAGENERATION] [--retain-until=DATETIME --retention-mode=RETENTION_MODE] [GCLOUD_WIDE_FLAG …]
DESCRIPTION
Copy data between your local file system and the cloud, within the cloud, and between cloud storage providers.
EXAMPLES
The following command uploads all text files from the local directory to a bucket:
gcloud storage cp *.txt gs://my-bucket
The following command downloads all text files from a bucket to your current directory:
gcloud storage cp gs://my-bucket/*.txt .
The following command transfers all text files from a bucket to a different cloud storage provider:
gcloud storage cp gs://my-bucket/*.txt s3://my-bucket
Use the --recursive option to copy an entire directory tree. The following command uploads the directory tree dir
gcloud storage cp --recursive dir gs://my-bucket
Recursive listings are similar to adding ** to a query, except ** matches only cloud objects and will not match prefixes. For example, the following would not match gs://my-bucket/dir/log.txt
gcloud storage cp gs://my-bucket/**/dir dir
** retrieves a flat list of objects in a single API call. However, ** matches folders for non-cloud queries. For example, a folder dir
gcloud storage cp ~/Downloads/**/dir gs://my-bucket
POSITIONAL ARGUMENTS
[SOURCE …]
The source path(s) to copy.
DESTINATION
The destination path.
FLAGS
--additional-headers=HEADER=VALUE
Includes arbitrary headers in storage API calls. Accepts a comma separated list of key=value pairs, e.g. header1=value1,header2=value2. Overrides the default storage/additional_headers property value for this command invocation.
--all-versions, -A
Copy all source versions from a source bucket or folder. If not set, only the live version of each source object is copied.
Note: This option is only useful when the destination bucket has Object Versioning enabled. Additionally, the generation numbers of copied versions do not necessarily match the order of the original generation numbers.
--no-clobber, -n
Do not overwrite existing files or objects at the destination. Skipped items will be printed. This option may perform an additional GET request for cloud objects before attempting an upload.
--content-md5=MD5_DIGEST
Manually specified MD5 hash digest for the contents of an uploaded file. This flag cannot be used when uploading multiple files. The custom digest is used by the cloud provider for validation.
--continue-on-error, -c
If any operations are unsuccessful, the command will exit with a non-zero exit status after completing the remaining operations. This flag takes effect only in sequential execution mode (i.e. processor and thread count are set to 1). Parallelism is default.
--daisy-chain, -D
Copy in "daisy chain" mode, which means copying an object by first downloading it to the machine where the command is run, then uploading it to the destination bucket. The default mode is a "copy in the cloud," where data is copied without uploading or downloading. During a copy in the cloud, a source composite object remains composite at its destination. However, you can use daisy chain mode to change a composite object into a non-composite object. Note: Daisy chain mode is automatically used when copying between providers.
--do-not-decompress
Do not automatically decompress downloaded gzip files.
--manifest-path=MANIFEST_PATH, -L MANIFEST_PATH
Outputs a manifest log file with detailed information about each item that was copied. This manifest contains the following information for each item:
- Source path.
- Destination path.
- Source size.
- Bytes transferred.
- MD5 hash.
- Transfer start time and date in UTC and ISO 8601 format.
- Transfer completion time and date in UTC and ISO 8601 format.
- Final result of the attempted transfer: OK, error, or skipped.
- Details, if any.
If the manifest file already exists, gcloud storage appends log items to the existing file.
Objects that are marked as "OK" or "skipped" in the existing manifest file are not retried by future commands. Objects marked as "error" are retried.
--preserve-posix, -P
Causes POSIX attributes to be preserved when objects are copied. With this feature enabled, gcloud storage will copy several fields provided by the stat command: access time, modification time, owner UID, owner group GID, and the mode (permissions) of the file.
For uploads, these attributes are read off of local files and stored in the cloud as custom metadata. For downloads, custom cloud metadata is set as POSIX attributes on files after they are downloaded.
On Windows, this flag will only set and restore access time and modification time because Windows doesn't have a notion of POSIX UID, GID, and mode.
--print-created-message, -v
Prints the version-specific URL for each copied object.
--read-paths-from-stdin, -I
Read the list of resources to copy from stdin. No need to enter a source argument if this flag is present. Example: "storage cp -I gs://bucket/destination" Note: To copy the contents of one file directly from stdin, use "-" as the source argument without the "-I" flag.
--recursive, -R, -r
Recursively copy the contents of any directories that match the source path expression.
--skip-unsupported, -U
Skip objects with unsupported object types.
--storage-class=STORAGE_CLASS, -s STORAGE_CLASS
Specify the storage class of the destination object. If not specified, the default storage class of the destination bucket is used. This option is not valid for copying to non-cloud destinations.
--canned-acl=PREDEFINED_ACL, --predefined-acl=PREDEFINED_ACL, -a PREDEFINED_ACL
Applies predefined, or "canned," ACLs to a resource. See docs for a list of predefined ACL constants: https://cloud.google.com/storage/docs/access-control/lists#predefined-acl
--[no-]preserve-acl, -p
Preserves ACLs when copying in the cloud. This option is Cloud Storage-only, and you need OWNER access to all copied objects. If all objects in the destination bucket should have the same ACL, you can also set a default object ACL on that bucket instead of using this flag. Preserving ACLs is the default behavior for updating existing objects. Use --preserve-acl to enable and --no-preserve-acl to disable.
At most one of these can be specified:
--gzip-in-flight=[FILE_EXTENSIONS,…], -j [FILE_EXTENSIONS,…]
Applies gzip transport encoding to any file upload whose extension matches the input extension list. This is useful when uploading files with compressible content such as .js, .css, or .html files. This also saves network bandwidth while leaving the data uncompressed in Cloud Storage.
When you specify the --gzip-in-flight option, files being uploaded are compressed in-memory and on-the-wire only. Both the local files and Cloud Storage objects remain uncompressed. The uploaded objects retain the Content-Type and name of the original files.
--gzip-in-flight-all, -J
Applies gzip transport encoding to file uploads. This option works like the --gzip-in-flight option described above, but it applies to all uploaded files, regardless of extension.
CAUTION: If some of the source files don't compress well, such as binary data, using this option may result in longer uploads.
--gzip-local=[FILE_EXTENSIONS,…], -z [FILE_EXTENSIONS,…]
Applies gzip content encoding to any file upload whose extension matches the input extension list. This is useful when uploading files with compressible content such as .js, .css, or .html files. This saves network bandwidth and space in Cloud Storage.
When you specify the --gzip-local option, the data from files is compressed before it is uploaded, but the original files are left uncompressed on the local disk. The uploaded objects retain the Content-Type and name of the original files. However, the Content-Encoding metadata is set to gzip and the Cache-Control metadata set to no-transform. The data remains compressed on Cloud Storage servers and will not be decompressed on download by gcloud storage because of the no-transform field.
Since the local gzip option compresses data prior to upload, it is not subject to the same compression buffer bottleneck of the in-flight gzip option.
--gzip-local-all, -Z
Applies gzip content encoding to file uploads. This option works like the --gzip-local option described above, but it applies to all uploaded files, regardless of extension.
CAUTION: If some of the source files don't compress well, such as binary data, using this option may result in files taking up more space in the cloud than they would if left uncompressed.
Flags to influence behavior when handling symlinks. Only one value may be set.
At most one of these can be specified:
--ignore-symlinks
Ignore file symlinks instead of copying what they point to.
--preserve-symlinks
Preserve symlinks instead of copying what they point to. With this feature enabled, uploaded symlinks will be represented as placeholders in the cloud whose content consists of the linked path. Inversely, such placeholders will be converted to symlinks when downloaded while this feature is enabled, as described at https://cloud.google.com/storage-transfer/docs/metadata-preservation#posix_to.
Directory symlinks are only followed if this flag is specified.
CAUTION: No validation is applied to the symlink target paths. Once downloaded, preserved symlinks will point to whatever path was specified by the placeholder, regardless of the location or permissions of the path, or whether it actually exists.
This feature is not supported on Windows.
ENCRYPTION FLAGS
--decryption-keys=[DECRYPTION_KEY,…]
A comma-separated list of customer-supplied encryption keys (RFC 4648 section 4 base64-encoded AES256 strings) that will be used to decrypt Cloud Storage objects. Data encrypted with a customer-managed encryption key (CMEK) is decrypted automatically, so CMEKs do not need to be listed here.
--encryption-key=ENCRYPTION_KEY
The encryption key to use for encrypting target objects. The specified encryption key can be a customer-supplied encryption key (An RFC 4648 section 4 base64-encoded AES256 string), or a customer-managed encryption key of the form projects/{project}/locations/{location}/keyRings/{key-ring}/cryptoKeys/{crypto-key}. The specified key also acts as a decryption key, which is useful when copying or moving encrypted data to a new location. Using this flag in an objects update command triggers a rewrite of target objects.
OBJECT METADATA FLAGS
--cache-control=CACHE_CONTROL
How caches should handle requests and responses.
--content-disposition=CONTENT_DISPOSITION
How content should be displayed.
--content-encoding=CONTENT_ENCODING
How content is encoded (e.g. gzip
--content-language=CONTENT_LANGUAGE
Content's language (e.g. en
--content-type=CONTENT_TYPE
Type of data contained in the object (e.g. text/html
--custom-time=CUSTOM_TIME
Custom time for Cloud Storage objects in RFC 3339 format.
At most one of these can be specified:
--clear-custom-metadata
Clears all custom metadata on objects. When used with --preserve-posix, POSIX attributes will still be stored in custom metadata.
--custom-metadata=[CUSTOM_METADATA_KEYS_AND_VALUES,…]
Sets custom metadata on objects. When used with --preserve-posix, POSIX attributes are also stored in custom metadata.
Flags that preserve unspecified existing metadata cannot be used with --custom-metadata or --clear-custom-metadata, but can be specified together:
--remove-custom-metadata=[METADATA_KEYS,…]
Removes individual custom metadata keys from objects. This flag can be used with --update-custom-metadata. When used with --preserve-posix, POSIX attributes specified by this flag are not preserved.
--update-custom-metadata=[CUSTOM_METADATA_KEYS_AND_VALUES,…]
Adds or sets individual custom metadata key value pairs on objects. Existing custom metadata not specified with this flag is not changed. This flag can be used with --remove-custom-metadata. When keys overlap with those provided by --preserve-posix, values specified by this flag are used.
PRECONDITION FLAGS
--if-generation-match=GENERATION
Execute only if the generation matches the generation of the requested object.
--if-metageneration-match=METAGENERATION
Execute only if the metageneration matches the metageneration of the requested object.
RETENTION FLAGS
--retain-until=DATETIME
Ensures the destination object is retained until the specified time in RFC 3339 format.
--retention-mode=RETENTION_MODE
Sets the destination object retention mode to either "Locked" or "Unlocked". When retention mode is "Locked", the retain until time can only be increased. RETENTION_MODE must be one of: Locked, Unlocked.
GCLOUD WIDE FLAGS
These flags are available to all commands: --access-token-file, --account, --billing-project, --configuration, --flags-file, --flatten, --format, --help, --impersonate-service-account, --log-http, --project, --quiet, --trace-token, --user-output-enabled, --verbosity.
Run $ gcloud help for details.
NOTES
This variant is also available:
gcloud alpha storage cpcp - Copy files and objects
bookmark_border
Important: gsutil is not the recommended CLI for Cloud Storage. Use gcloud storage commands in the Google Cloud CLI instead.
Synopsis
gsutil cp [OPTION]... src_url dst_url gsutil cp [OPTION]... src_url... dst_url gsutil cp [OPTION]... -I dst_url
Description
The gsutil cp command allows you to copy data between your local file system and the cloud, within the cloud, and between cloud storage providers. For example, to upload all text files from the local directory to a bucket, you can run:
gsutil cp *.txt gs://my-bucket
You can also download data from a bucket. The following command downloads all text files from the top-level of a bucket to your current directory:
gsutil cp gs://my-bucket/*.txt .
You can use the -n option to prevent overwriting the content of existing files. The following example downloads text files from a bucket without clobbering the data in your directory:
gsutil cp -n gs://my-bucket/*.txt .
Use the -r option to copy an entire directory tree. For example, to upload the directory tree dir:
gsutil cp -r dir gs://my-bucket
If you have a large number of files to transfer, you can perform a parallel multi-threaded/multi-processing copy using the top-level gsutil -m option (see gsutil help options):
gsutil -m cp -r dir gs://my-bucket
You can use the -I option with stdin to specify a list of URLs to copy, one per line. This allows you to use gsutil in a pipeline to upload or download objects as generated by a program:
cat filelist | gsutil -m cp -I gs://my-bucket
or:
cat filelist | gsutil -m cp -I ./download_dir
where the output of cat filelist is a list of files, cloud URLs, and wildcards of files and cloud URLs.
Note: Shells like bash and zsh sometimes attempt to expand wildcards in ways that can be surprising. You may also encounter issues when attempting to copy files whose names contain wildcard characters. For more details about these issues, see Wildcard behavior considerations.
How Names Are Constructed
The gsutil cp command attempts to name objects in ways that are consistent with the Linux cp command. This means that names are constructed depending on whether you're performing a recursive directory copy or copying individually-named objects, or whether you're copying to an existing or non-existent directory.
When you perform recursive directory copies, object names are constructed to mirror the source directory structure starting at the point of recursive processing. For example, if dir1/dir2 contains the file a/b/c, then the following command creates the object gs://my-bucket/dir2/a/b/c:
gsutil cp -r dir1/dir2 gs://my-bucket
In contrast, copying individually-named files results in objects named by the final path component of the source files. For example, assuming again that dir1/dir2 contains a/b/c, the following command creates the object gs://my-bucket/c:
gsutil cp dir1/dir2/** gs://my-bucket
Note that in the above example, the '**' wildcard matches all names anywhere under dir. The wildcard '*' matches names just one level deep. For more details, see URI wildcards.
The same rules apply for uploads and downloads: recursive copies of buckets and bucket subdirectories produce a mirrored filename structure, while copying individually or wildcard-named objects produce flatly-named files.
In addition, the resulting names depend on whether the destination subdirectory exists. For example, if gs://my-bucket/subdir exists as a subdirectory, the following command creates the object gs://my-bucket/subdir/dir2/a/b/c:
gsutil cp -r dir1/dir2 gs://my-bucket/subdir
In contrast, if gs://my-bucket/subdir does not exist, this same gsutil cp command creates the object gs://my-bucket/subdir/a/b/c.
Note: The Google Cloud Platform Console creates folders by creating "placeholder" objects that end with a "/" character. gsutil skips these objects when downloading from the cloud to the local file system, because creating a file that ends with a "/" is not allowed on Linux and macOS. We recommend that you only create objects that end with "/" if you don't intend to download such objects using gsutil.
Copying To/From Subdirectories; Distributing Transfers Across Machines
You can use gsutil to copy to and from subdirectories by using a command like this:
gsutil cp -r dir gs://my-bucket/data
This causes dir and all of its files and nested subdirectories to be copied under the specified destination, resulting in objects with names like gs://my-bucket/data/dir/a/b/c. Similarly, you can download from bucket subdirectories using the following command:
gsutil cp -r gs://my-bucket/data dir
This causes everything nested under gs://my-bucket/data to be downloaded into dir, resulting in files with names like dir/data/a/b/c.
Copying subdirectories is useful if you want to add data to an existing bucket directory structure over time. It's also useful if you want to parallelize uploads and downloads across multiple machines (potentially reducing overall transfer time compared with running gsutil -m cp on one machine). For example, if your bucket contains this structure:
gs://my-bucket/data/result_set_01/ gs://my-bucket/data/result_set_02/ ... gs://my-bucket/data/result_set_99/
you can perform concurrent downloads across 3 machines by running these commands on each machine, respectively:
gsutil -m cp -r gs://my-bucket/data/result_set_[0-3]* dir gsutil -m cp -r gs://my-bucket/data/result_set_[4-6]* dir gsutil -m cp -r gs://my-bucket/data/result_set_[7-9]* dir
Note that dir could be a local directory on each machine, or a directory mounted off of a shared file server. The performance of the latter depends on several factors, so we recommend experimenting to find out what works best for your computing environment.
Copying In The Cloud And Metadata Preservation
If both the source and destination URL are cloud URLs from the same provider, gsutil copies data "in the cloud" (without downloading to and uploading from the machine where you run gsutil). In addition to the performance and cost advantages of doing this, copying in the cloud preserves metadata such as Content-Type and Cache-Control. In contrast, when you download data from the cloud, it ends up in a file with no associated metadata, unless you have some way to keep or re-create that metadata.
Copies spanning locations and/or storage classes cause data to be rewritten in the cloud, which may take some time (but is still faster than downloading and re-uploading). Such operations can be resumed with the same command if they are interrupted, so long as the command parameters are identical.
Note that by default, the gsutil cp command does not copy the object ACL to the new object, and instead uses the default bucket ACL (see gsutil help defacl). You can override this behavior with the -p option.
When copying in the cloud, if the destination bucket has Object Versioning enabled, by default gsutil cp copies only live versions of the source object. For example, the following command causes only the single live version of gs://bucket1/obj to be copied to gs://bucket2, even if there are noncurrent versions of gs://bucket1/obj:
gsutil cp gs://bucket1/obj gs://bucket2
To also copy noncurrent versions, use the -A flag:
gsutil cp -A gs://bucket1/obj gs://bucket2
The top-level gsutil -m flag is not allowed when using the cp -A flag.
Checksum Validation
gsutil automatically performs checksum validation for copies to and from Cloud Storage. For more information, see Hashes and ETags.
Retry Handling
The cp command retries when failures occur, but if enough failures happen during a particular copy or delete operation, or if a failure isn't retryable, the cp command skips that object and moves on. If any failures were not successfully retried by the end of the copy run, the cp command reports the number of failures and exits with a non-zero status.
For details about gsutil's overall retry handling, see Retry strategy.
Resumable Transfers
gsutil automatically resumes interrupted downloads and interrupted resumable uploads, except when performing streaming transfers. In the case of an interrupted download, a partially downloaded temporary file is visible in the destination directory with the suffix _.gstmp in its name. Upon completion, the original file is deleted and replaced with the downloaded contents.
Resumable transfers store state information in files under ~/.gsutil, named by the destination object or file.
See gsutil help prod for details on using resumable transfers in production.
Streaming Transfers
Use '-' in place of src_url or dst_url to perform a streaming transfer.
Streaming uploads using the JSON API are buffered in memory part-way back into the file and can thus sometimes resume in the event of network or service problems.
gsutil does not support resuming streaming uploads using the XML API or resuming streaming downloads for either JSON or XML. If you have a large amount of data to transfer in these cases, we recommend that you write the data to a local file and copy that file rather than streaming it.
Sliced Object Downloads
gsutil can automatically use ranged GET requests to perform downloads in parallel for large files being downloaded from Cloud Storage. See sliced object download documentation for a complete discussion.
Parallel Composite Uploads
gsutil can automatically use object composition to perform uploads in parallel for large, local files being uploaded to Cloud Storage. See the parallel composite uploads documentation for a complete discussion.
Changing Temp Directories
gsutil writes data to a temporary directory in several cases:
-
when compressing data to be uploaded (see the
-zand-Zoptions) -
when decompressing data being downloaded (for example, when the data has
Content-Encoding:gzipas a result of being uploaded using gsutil cp -z or gsutil cp -Z) -
when running integration tests using the gsutil test command
In these cases, it's possible the temporary file location on your system that gsutil selects by default may not have enough space. If gsutil runs out of space during one of these operations (for example, raising "CommandException: Inadequate temp space available to compress <your file>" during a gsutil cp -z operation), you can change where it writes these temp files by setting the TMPDIR environment variable. On Linux and macOS, you can set the variable as follows:
TMPDIR=/some/directory gsutil cp ...
You can also add this line to your ~/.bashrc file and restart the shell before running gsutil:
export TMPDIR=/some/directory
On Windows 7, you can change the TMPDIR environment variable from Start -> Computer -> System -> Advanced System Settings -> Environment Variables. You need to reboot after making this change for it to take effect. Rebooting is not necessary after running the export command on Linux and macOS.
Synchronizing Over Os-Specific File Types (Such As Symlinks And Devices)
Please see the section about OS-specific file types in gsutil help rsync. While that section refers to the rsync command, analogous points apply to the cp command.
Options
-a predef_acl
Applies the specific predefined ACL to uploaded objects. See "gsutil help acls" for further details.
-A
Copy all source versions from a source bucket or folder. If not set, only the live version of each source object is copied.
Note: This option is only useful when the destination bucket has Object Versioning enabled. Additionally, the generation numbers of copied versions do not necessarily match the order of the original generation numbers.
-c
If an error occurs, continue attempting to copy the remaining files. If any copies are unsuccessful, gsutil's exit status is non-zero, even if this flag is set. This option is implicitly set when running gsutil -m cp....
Note: -c only applies to the actual copying operation. If an error, such as invalid Unicode file name, occurs while iterating over the files in the local directory, gsutil prints an error message and aborts.
-D
Copy in "daisy chain" mode, which means copying between two buckets by first downloading to the machine where gsutil is run, then uploading to the destination bucket. The default mode is a "copy in the cloud," where data is copied between two buckets without uploading or downloading.
During a "copy in the cloud," a source composite object remains composite at its destination. However, you can use "daisy chain" mode to change a composite object into a non-composite object. For example:
gsutil cp -D gs://bucket/obj gs://bucket/obj_tmp gsutil mv gs://bucket/obj_tmp gs://bucket/obj
Note: "Daisy chain" mode is automatically used when copying between providers: for example, when copying data from Cloud Storage to another provider.
-e
Exclude symlinks. When specified, symbolic links are not copied.
-I
Use stdin to specify a list of files or objects to copy. You can use gsutil in a pipeline to upload or download objects as generated by a program. For example:
cat filelist | gsutil -m cp -I gs://my-bucket
where the output of cat filelist is a one-per-line list of files, cloud URLs, and wildcards of files and cloud URLs.
-j <ext,...>
Applies gzip transport encoding to any file upload whose extension matches the -j extension list. This is useful when uploading files with compressible content such as .js, .css, or .html files. This also saves network bandwidth while leaving the data uncompressed in Cloud Storage.
When you specify the -j option, files being uploaded are compressed in-memory and on-the-wire only. Both the local files and Cloud Storage objects remain uncompressed. The uploaded objects retain the Content-Type and name of the original files.
Note that if you want to use the -m top-level option to parallelize copies along with the -j/-J options, your performance may be bottlenecked by the "max_upload_compression_buffer_size" boto config option, which is set to 2 GiB by default. You can change this compression buffer size to a higher limit. For example:
gsutil -o "GSUtil:max_upload_compression_buffer_size=8G" \ -m cp -j html,txt -r /local/source/dir gs://bucket/path
-J
Applies gzip transport encoding to file uploads. This option works like the -j option described above, but it applies to all uploaded files, regardless of extension.
Caution: If some of the source files don't compress well, such as binary data, using this option may result in longer uploads.
-L <file>
Outputs a manifest log file with detailed information about each item that was copied. This manifest contains the following information for each item:
-
Source path.
-
Destination path.
-
Source size.
-
Bytes transferred.
-
MD5 hash.
-
Transfer start time and date in UTC and ISO 8601 format.
-
Transfer completion time and date in UTC and ISO 8601 format.
-
Upload id, if a resumable upload was performed.
-
Final result of the attempted transfer, either success or failure.
-
Failure details, if any.
If the log file already exists, gsutil uses the file as an input to the copy process, and appends log items to the existing file. Objects that are marked in the existing log file as having been successfully copied or skipped are ignored. Objects without entries are copied and ones previously marked as unsuccessful are retried. This option can be used in conjunction with the -c option to build a script that copies a large number of objects reliably, using a bash script like the following:
until gsutil cp -c -L cp.log -r ./dir gs://bucket; do sleep 1 done
The -c option enables copying to continue after failures occur, and the -L option allows gsutil to pick up where it left off without duplicating work. The loop continues running as long as gsutil exits with a non-zero status. A non-zero status indicates there was at least one failure during the copy operation.
Note: If you are synchronizing the contents of a directory and a bucket, or the contents of two buckets, see gsutil help rsync.
-n
No-clobber. When specified, existing files or objects at the destination are not replaced. Any items that are skipped by this option are reported as skipped. gsutil performs an additional GET request to check if an item exists before attempting to upload the data. This saves gsutil from retransmitting data, but the additional HTTP requests may make small object transfers slower and more expensive.
-p
Preserves ACLs when copying in the cloud. Note that this option has performance and cost implications only when using the XML API, as the XML API requires separate HTTP calls for interacting with ACLs. You can mitigate this performance issue using gsutil -m cp to perform parallel copying. Note that this option only works if you have OWNER access to all objects that are copied. If you want all objects in the destination bucket to end up with the same ACL, you can avoid these performance issues by setting a default object ACL on that bucket instead of using cp -p. See gsutil help defacl.
Note that it's not valid to specify both the -a and -p options together.
-P
Enables POSIX attributes to be preserved when objects are copied. gsutil cp copies fields provided by stat. These fields are the user ID of the owner, the group ID of the owning group, the mode or permissions of the file, and the access and modification time of the file. For downloads, these attributes are only set if the source objects were uploaded with this flag enabled.
On Windows, this flag only sets and restores access time and modification time. This is because Windows doesn't support POSIX uid/gid/mode.
-R, -r
The -R and -r options are synonymous. They enable directories, buckets, and bucket subdirectories to be copied recursively. If you don't use this option for an upload, gsutil copies objects it finds and skips directories. Similarly, if you don't specify this option for a download, gsutil copies objects at the current bucket directory level and skips subdirectories.
-s <class>
Specifies the storage class of the destination object. If not specified, the default storage class of the destination bucket is used. This option is not valid for copying to non-cloud destinations.
-U
Skips objects with unsupported object types instead of failing. Unsupported object types include Amazon S3 objects in the GLACIER storage class.
-v
Prints the version-specific URL for each uploaded object. You can use these URLs to safely make concurrent upload requests, because Cloud Storage refuses to perform an update if the current object version doesn't match the version-specific URL. See generation numbers for more details.
-z <ext,...>
Applies gzip content-encoding to any file upload whose extension matches the -z extension list. This is useful when uploading files with compressible content such as .js, .css, or .html files, because it reduces network bandwidth and storage sizes. This can both improve performance and reduce costs.
When you specify the -z option, the data from your files is compressed before it is uploaded, but your actual files are left uncompressed on the local disk. The uploaded objects retain the Content-Type and name of the original files, but have their Content-Encoding metadata set to gzip to indicate that the object data stored are compressed on the Cloud Storage servers and have their Cache-Control metadata set to no-transform.
For example, the following command:
gsutil cp -z html \ cattypes.html tabby.jpeg gs://mycats
does the following:
-
The
cpcommand uploads the filescattypes.htmlandtabby.jpegto the bucketgs://mycats. -
Based on the file extensions, gsutil sets the
Content-Typeofcattypes.htmltotext/htmlandtabby.jpegtoimage/jpeg. -
The
-zoption compresses the data in the filecattypes.html. -
The
-zoption also sets theContent-Encodingforcattypes.htmltogzipand theCache-Controlforcattypes.htmltono-transform.
Because the -z/-Z options compress data prior to upload, they are not subject to the same compression buffer bottleneck that can affect the -j/-J options.
Note that if you download an object with Content-Encoding:gzip, gsutil decompresses the content before writing the local file.
-Z
Applies gzip content-encoding to file uploads. This option works like the -z option described above, but it applies to all uploaded files, regardless of extension.
Caution: If some of the source files don't compress well, such as binary data, using this option may result in files taking up more space in the cloud than they would if left uncompressed.
--stet
If the STET binary can be found in boto or PATH, cp will use the split-trust encryption tool for end-to-end encryption.

















 5605
5605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









