







本文地址:http://blog.csdn.net/mounty_fsc/article/details/51438447
《Robust Text Detection in Natural Scene Images》论文笔记
这篇文章是2014年PAMI上的文章,是目前文本检测领域的state of the art.
该算法是基于MSERs的,主要内容有:
算法流程
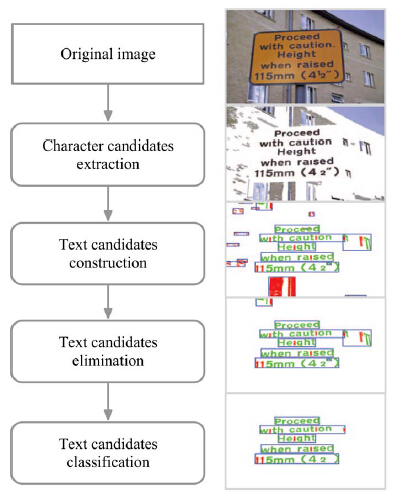
1 Character candidates extraction
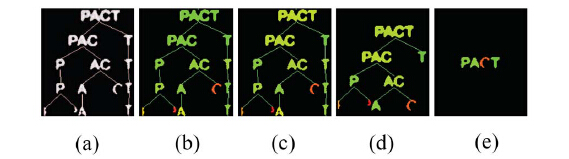
使用MSERs算法来产生字符候选区域,但是MSER算法可能产生过多的重复区域,因而需要剔除非文字的候选区域。根据MSER算法的性质,可以构造一棵MSERs树,每个MSER对应为一个可能的字符候选区域。
剔除的依据是,如果一个候选区域被认为是字符,则父子结点都不可能是字符了,(因为文字不会有相互包含关系),但问题是判断一个结点是否为字符讲花费大量计算,一种比较好的方法是通过父子结点的关系来判断是否为字符,如果其MSER的variation小的则为字符(即stable的字符)。
但variation最小的不一定就是字符,所以作者提出了regularized variation具体的做法是,先用linear reduction的方法,对一棵MSERs树中度为1的连接进行删除,然后在用tree accumulation对度为2的连接中进行删除。


2 Text Candidates Construction
上一步生成了字符候选区域,这一步通过字符候选区域构建文本行。
使用的是single-link(agglomerate)聚类算法,是一种层次聚类算法,需要定义点跟点(1中候选字符区域)的距离。
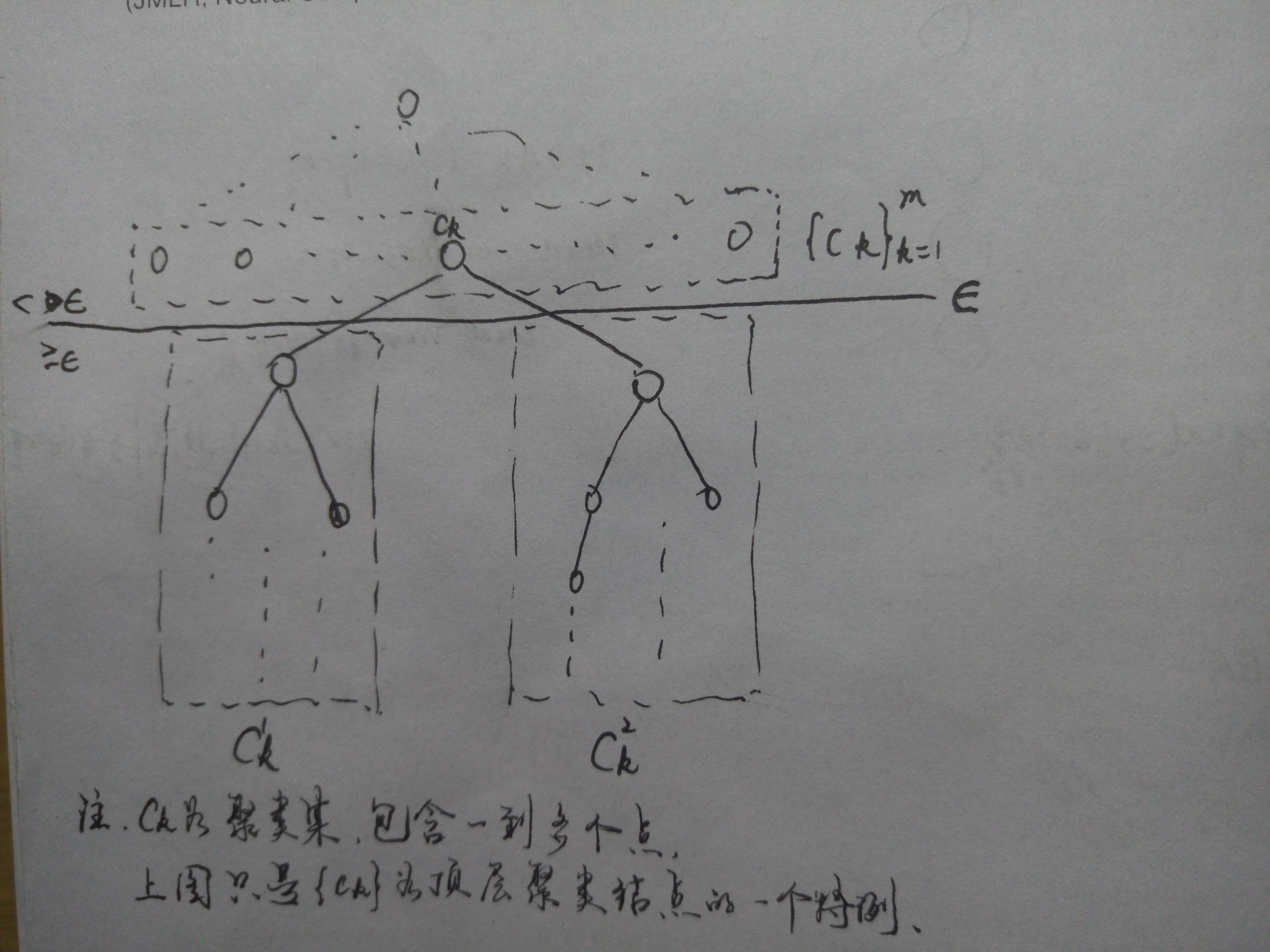
在层次聚类中
ε
为一个阈值,最后的生成的聚类,聚类与聚类间的距离(两个聚类中每个点的距离)都大于
ε
,聚类内的值都小于该值,作者利用这个性质设计了一个self-training的逻辑回归分类器,来计算距离参数
d(u,v;w)=wTxu,v
中的
w
以及

3 Text Candidates Elimination
通过以上的步骤,得到了文本候选区域,但是之前的步骤得到的文本候选区域只有9%是真正的文本,所以作者接下来又设计了一个分类器来分类文本候选区域。
这个阶段涉及两个分类器,一个是Character分类器一个是Text分类器。首先通过Character分类器可以得到Text中预测的一个观测
O(m,n;p)
,
m
是包含字符数量,
最后使用贝叶斯分类器来对文本分类,及
4 Extension to Multi-Orientation Text Detection
这个部分是为了解决检测非水平方向文本行的问题(但注意,文本还是在同一行上排列的),思路是使用启发式方法,在1中生成字符候选区域后,使用3中Character分类器构造文本候选区域pair的优先级依次是(char,char),(non-char,char),(non-char,non-char),然后根据这些pair的优先级拓展文本的方向,来确定各个文本行的方向。确定文本行的方向后,再使用之前的方法进行检测。
5 Experiment
最后的实验是在ICDAR 2011,multilingual database, street view database以及multi-orientation database几个数据集及方面展开的。















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









