







关注公众号,发现CV技术之美
▊ 写在前面
Transformer在处理视觉任务方面取得了很大的进展。然而,现有的视觉Transformer仍然不具备在不同尺度的视觉特征之间建立attention的能力。造成这个问题的原因有两方面:1)每层的输入embedding都是等尺度的,没有跨尺度特征;2)一些视觉Transformer牺牲了小尺度的特征embedding,以降低Self-Attention模块的计算成本。
为了弥补这一缺陷,作者提出了跨尺度embedding层(Cross-scale Embedding Layer,CEL) 和长短距离注意层(Long Short Distance Attention,LSDA) 。CEL将每个embedding与不同尺度的多个patch融合 ,为模型提供跨尺度embedding。LSDA将自注意模块分为短距离模块和长距离模块 ,降低了计算成本,但在embedding中保留了小规模和大规模的特性。
通过这两种设计,模型实现了跨尺度的attention。此外,作者还提出了视觉Transformer的动态位置偏差(dynamic position bias),以使目前的相对位置偏差方法能够应用于可变大小的图像 。基于这些提出的模块,作者构建了新的视觉Transformer架构,称为CrossFormer。实验表明,CrossFormer在多个具有代表性的视觉任务上,特别是目标检测和分割上,优于其他Transformer结构。
▊ 1. 论文和代码地址

CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention
论文:https://arxiv.org/abs/2108.00154
代码:https://github.com/cheerss/CrossFormer
▊ 2. Motivation
Transformer在自然语言处理(NLP)方面取得了巨大的成功。受益于其高效的自注意模块,Transformer天生就具有建立远程依赖的能力,这对许多视觉任务也很重要。因此,已经有大量的研究探索了基于Transformer的视觉架构。
原始Transformer需要一系列的embedding作为输入。为了适应视觉任务,大多数现有的视觉Transformer通过将图像分割成相同大小的patch来产生embedding。例如,一个224×224图像可以被分割成56×56个4×4大小的patch,然后这些patch通过线性层投影成为embedding序列。
在Transformer内部,自注意模块可以在任意两个embedding之间建立依赖关系。然而,普通自注意机制的显存和计算成本对于视觉任务来说太大了,因为视觉embedding的序列长度比NLP的要长得多。因此,目前也有一些工作提出了许多Self-Attention机制的替代品,以较低的成本近似Self-Attention模块。
虽然上述工作取得了一些进展,但现有的视觉Transformer仍然存在限制其性能的问题——它们不能在不同尺度的特征之间建立attention,而这种能力对视觉任务非常重要 。例如,一个图像通常包含许多不同尺度的对象,而建立它们之间的关系需要一个跨尺度的注意机制。此外,一些任务,如实例分割,需要大规模(粗粒度)特征和小规模(细粒度)特征之间的交互。
现有的视觉Transformer无法处理这些情况,原因有两个原因:
1)embedding序列用相同大小的patch生成的,所以embedding在同一层只拥有一个尺度的特征 。
2)目前的一些transformer模型为了减少self-attention的计算量,将相邻的key和value特征进行了合并 。因此,即使embedding同时具有不同尺度的特征,合并操作也会造成每个embedding的小规模(细粒度)特征的损失,从而阻碍了跨尺度的attention。
为了解决这一问题,作者设计了新的embedding层和自注意模块:
1)跨尺度embedding层(Cross-scale Embedding Layer,CEL) ,作者在Transformer使用了一个金字塔结构,将模型自然地分为多个stage。CEL出现在每个stage的开始阶段,接收上一个stage的输出作为输入,使用多个不同尺度的卷积核进行采样patch。然后,每个embedding都是通过投影和concat这些patch来构建的,因此构建的embedding是多尺度的,而不是单尺度的。
2)长短距离注意层(Long Short Distance Attention,LSDA) ,作者提出了一种替代普通的Self-Attention的方法。为了保持小规模的特征,所有的embedding将不会被合并。LSDA可以分为短距离注意(SDA) 和长距离注意(LDA) 。SDA构建相邻embedding之间的依赖关系,而LDA负责远离距离的embedding之间的依赖关系。此外,LSDA还降低了自注意模块的成本,并且LSDA还不会损害小规模或大规模的特征,有助于多尺度的特征信息交互。
此外,相对位置偏差(RPB)是视觉Transformer的有效位置表示方法。但是,它仅适用于输入图像大小固定的情况下。对于目标检测等任务,输入的图片通常是不固定的。为了使其更加灵活,作者提出了一个可训练的模块,称为动态位置偏差(DPB),它接收两个embedding的距离作为输入,并输出它们的位置偏差 。DPB在训练阶段进行了端到端优化,并且适用于可变的图像大小。
基于上面提出的几个模块,作者构建了四种不同计算量和参数量的多尺度视觉Transformer,称为CrossFormer。实验表明,CrossFormer在多个具有代表性的视觉任务上,特别是目标检测和分割上,优于其他Transformer结构。作者认为这是因为图像分类只需要关注一个目标和大规模特征,而密集的预测任务更依赖于跨尺度注意。
▊ 3. 方法
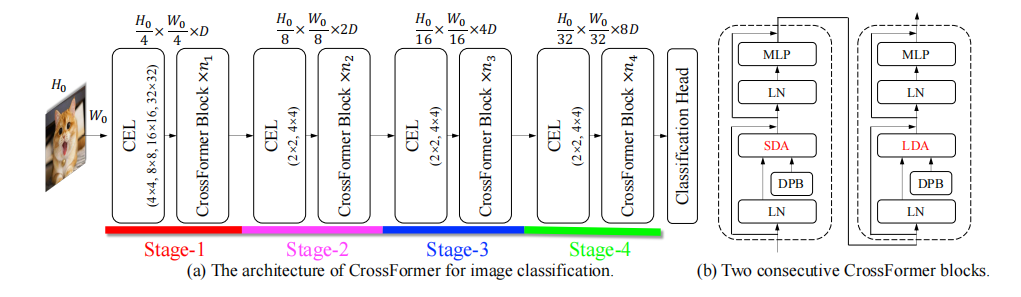
Crossformer的模型结构如上图所示,Crossformer采用了金字塔结构,自然地将模型分为四个阶段。每个阶段由一个跨尺度embedding层和几个Crossformer Block组成。CEL接收上一个阶段的输出作为输入,并生成跨尺度的embedding。
在这个过程中,CEL(除了Stage-1)将embedding的数量减少到四分之一,而金字塔结构的维度增加了一倍。然后CEL后面接上Crossformer Block,并在网络的最后接上特定任务的head以完成特定的任务。
3.1跨尺度embedding层(CEL)

跨尺度embedding层用于生成每个阶段的输入embedding。上图展示了Stage1的CEL。它接收一个图像作为输入,使用四个不同大小的核来采样patch。四个核的步长保持不变,以便它们生成相同数量的embedding。
如上图所示,每四个对应的patch都有相同的中心,但有不同的尺度。这四个patch将被投影并concat为一个embedding。在实现上,采样和embedding的过程可以通过四个卷积层来实现。
对于跨尺度embedding,有一个问题是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3857
3857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









