







关注公众号,发现CV技术之美
▊ 写在前面
最近的研究表明,使用对比图像文本对进行大规模的预训练可能是从自然语言监督中学习高质量视觉表示的有前途的方法。得益于更广泛的监督来源,这一新范式在下游分类任务和可迁移性方面展现出了不错的结果。
然而,将从图像-文本对中学习到的知识转移到更复杂的密集预测任务的问题几乎没有被研究 。在这项工作中,作者通过隐式和显式地利用CLIP的预训练的知识,提出了一个新的密集预测框架。
具体而言,作者将CLIP中的原始图像-文本匹配问题 转换为像素-文本匹配问题 ,并使用像素-文本得分图来指导密集预测模型的学习。通过进一步使用来自图像的上下文信息来提示语言模型,能够促进模型更好地利用预训练的知识。
本文的方法与模型无关,可以应用于任意密集预测模型和各种预训练的视觉主干,包括CLIP模型和ImageNet预训练的模型。广泛的实验证明了本文的方法在语义分割,目标检测和实例分割任务上的卓越性能。
▊ 1. 论文和代码地址

DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
论文:https://arxiv.org/abs/2112.01518
代码:https://github.com/raoyongming/DenseCLIP▊ 2. Motivation
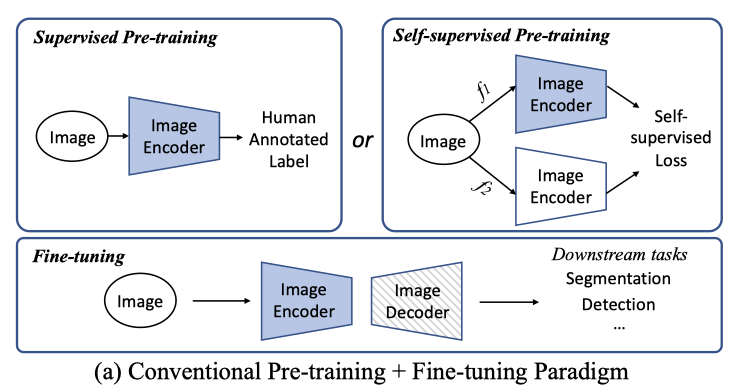
“预训练+微调”的范式在很大程度上推动了各种下游计算机视觉任务的SOTA水平,包括图像分类、目标检测、语义分割和动作识别。由于每像素预测的标注和计算成本很高,因此预训练对于密集预测任务更为关键。
如上图所示,预训练通常是由监督的分类或者自监督学习来学习的。然后,将特定任务模块(如检测器或解码器)添加到主干中,并使用较少的训练数据在目标数据集上对整个模型进行优化。
与仅基于图像的常规监督和自监督预训练方法不同,对比语言-图像预训练 (CLIP) 是通过探索大规模噪声图像-文本对的对比学习来学习高质量视觉表示的新框架。通过利用图像和相关文本之间的语义关系,这个新框架从文本的丰富和语义级监督中受益,同时享受更广泛和更便宜的数据源。由于语言监督,通过CLIP预训练的模型在没有标注或非常有限的标注的情况下在各种视觉分类任务上取得了不错的结果。
目前的工作已经可以将CLIP模型转移到下游的视觉分类任务中。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 913
913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









