






一篇CLIP应用在语义分割上的论文
论文标题:
DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
作者信息:

代码地址:
https://github.com/raoyongming/DenseCLIP
Abstract
CLIP模型对下游分类任务取得很好的效果,作者通过隐式和显式的利用CLIP中的预训练知识,提出一个密集型预测任务的框架,该框架通用于各种模型和主干网络,并在分割任务上有很好的效果。
Introduction
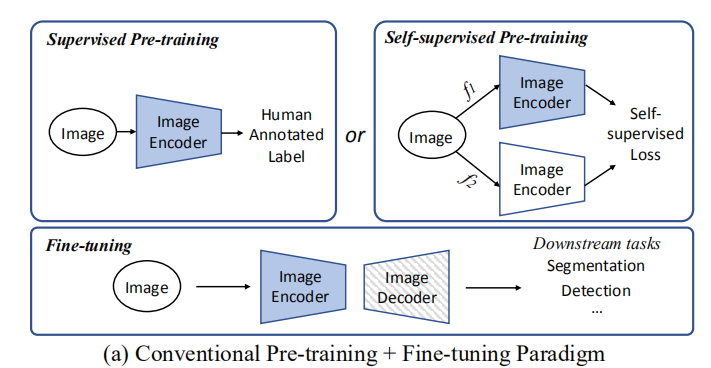
(首先讨论了经典的预训练应用范式)把backbone在大规模数据集预训练,然后根据任务接一个detector或则分割的decoder。
CLIP模型也可以通过这种方式进行应用,修改语言模型的输出并应用于分类任务,但是和其预训练任务相似,应用面太窄,不够通用,无法应用于密集型的预测任务。
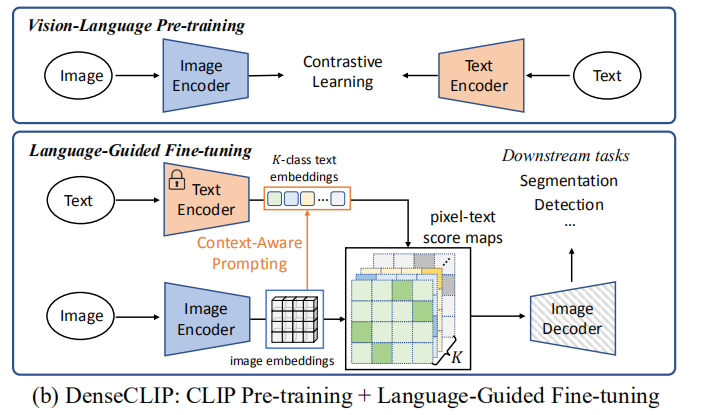
(作者的贡献)提出了DenseCLIP框架,将CLIP中的原始图像-文本匹配问题转换为像素-文本匹配问题,使用像素-文本score map来明确地指导密集预测模型的学习(图b)。该框架可以应用于任何主干模型。
Approach
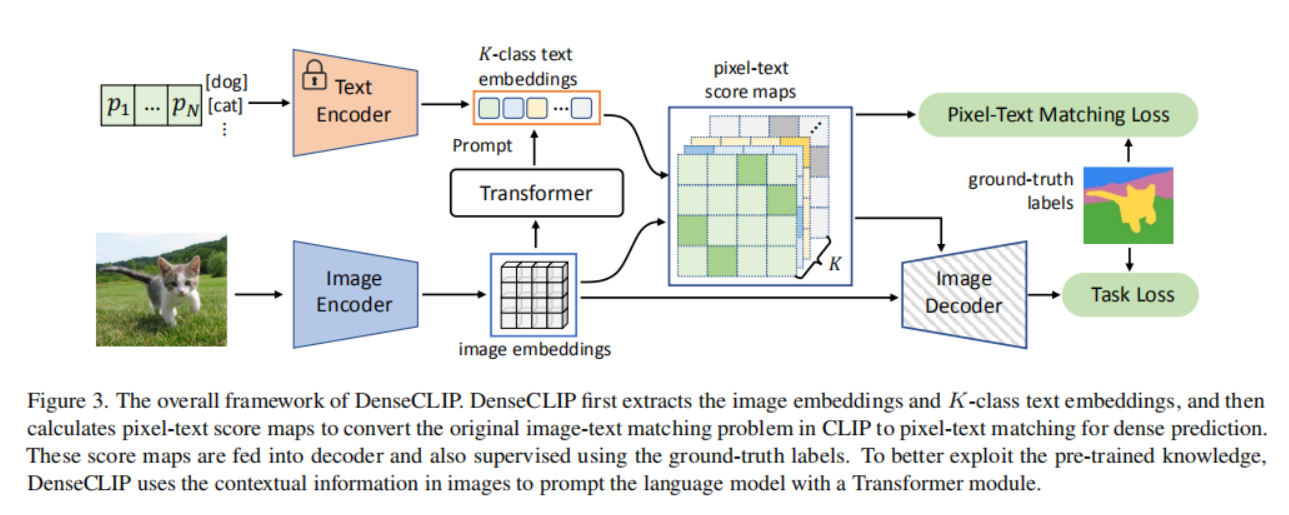
3.1. Preliminaries: Overview of CLIP
CLIP模型扩展应用在密集型任务上有两个难点:
1.首先是密集型预测任务应用backbone的就比较少,有一些应用就是把CLIP中的img encoder直接拿来用,但是忽视了text encoder的重要作用。
2.CLIP本身是分类任务,由于上游对比预训练任务和下游每像素预测任务之间存在巨大差距,将知识从CLIP转移到密集预测更加困难。主要原因还是输入输出的形式不一样。
3.2. Language-Guided Dense Prediction
作者认为除了CLIP中img encoder所表示的全局特征以外,最后一层是能表示 language-compatible feature map。CLIP在应用backbone的时候做了改进,加入了一个attention pooling layer(https://blog.csdn.net/rocking_struggling/article/details/127291295),在特征
x
4
x_4
x4上应用得到global feature
x
4
‾
\overline{x_4}
x4,之后将它们concat输出到多头自注意力层:
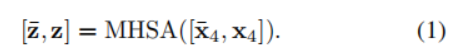
其中
z
4
‾
\overline{z_4}
z4被应用于Img decode的输出,而
z
4
{z_4}
z4被忽略掉了,作者认为:
(1)
z
4
{z_4}
z4仍然保留了足够的空间信息,因此可以作为一个特征图。
(2)MHSA对输入元素是类似的,故
z
4
{z_4}
z4应该和
z
4
‾
\overline{z_4}
z4类似。
作者将
z
4
{z_4}
z4和CLIP的text encoder的输出特征
t
t
t做乘法,获得pixel-text score map。
pixel-text score map有两个作用:
(1)直接作为低分辨率的分割结果,引入监督计算辅助分割损失。
(2)和
x
4
x_4
x4的concat输入到Image Deocoder中去,获得分割结果计算损失。
3.3. Context-Aware Prompting
(作者对text encoder部分做的一些改进)
作者认为CLIP中的text prompt: a photo of a [CLS]效果不是很好,尤其是对于分割任务而言。对于[CLS]描述应该越清晰越好,于是作者采用CoOp的思想,生成learnable textual contexts放在[CLS]的前面,输入到text encoder中去:
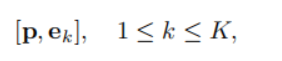
其中,
p
p
p是生成的contexts,
e
k
e_k
ek是类别。生成这些
p
p
p叫Vision-to-language prompting,分别叫pre-model prompting和post-model prompting:
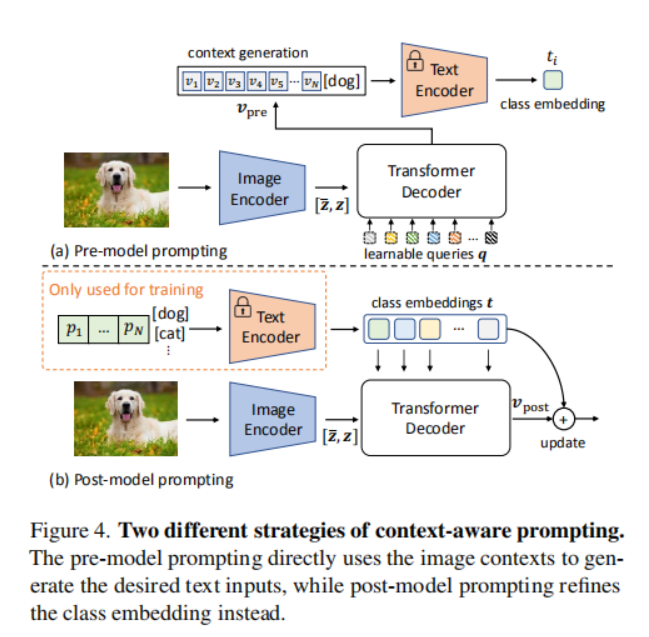
pre-model prompting:建立一个可学习的序列
q
q
q,然后和图像特征
z
z
zconcat输入到Decoder中去获得text
v
p
r
e
v_{pre}
vpre,把
v
p
r
e
v_{pre}
vpre替换
p
p
p。
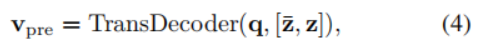
post-model prompting:把已经text encoder的特征
t
t
t和图像特征
z
z
zconcat暑促到Decoder中去获得text
v
p
o
s
t
v_{post}
vpost,并用它更新
t
t
t:
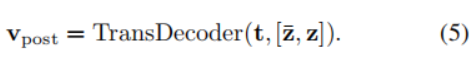

3.4. Instantiations
作者这个框架分别应用在语义分割、检测\实例分割上面,为此还设计了不同的损失函数。
语义分割的辅助损失函数:
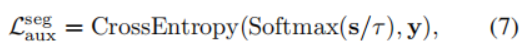
检测\实例分割损失函数:
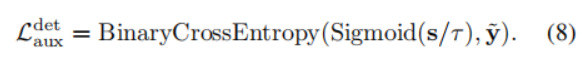
作者还说可以用任何主干网络替换CLIP中的Image Encoder,因为在text feature的指导下,backbone可以更快更好的学习,表明了DenseCLIP的强通用性。
Experiments
















 1400
1400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









