






关注公众号,发现CV技术之美
本文整理了收录于 ICCV 2023 会议的数据集论文,涵盖了水下图像视频、阴影去除、目标检测、跟踪分割、交互、超分辨率等领域。
视频背景音乐合成数据集
Video Background Music Generation: Dataset, Method and Evaluation
为了解决在编辑视频时可以根据视频输入自动生成背景音乐曲目,避免手动选择音乐时的耗时耗费。
本文介绍了一套完整的视频背景音乐生成方法,包括数据集、基准模型和评估指标。
其中,SymMV 是一个包含各种音乐标注的视频和符号音乐数据集。作者称,这是第一个具有丰富音乐标注的视频音乐数据集。
另外,V-MusProd 基准模型,利用了和弦、旋律和伴奏等音乐先验知识,结合了视频-音乐的语义、颜色和运动等特征关系,用于生成视频背景音乐。
为了解决视频音乐对应关系缺乏客观衡量标准的问题,设计一种基于检索的衡量标准 VMCP,它建立在一个强大的视频音乐表征学习模型之上。
实验表明,使用SymMV数据集,V-MusProd 在音乐质量和视频对应性方面都优于最先进的方法。
论文链接:https://arxiv.org/abs/2211.11248
项目链接(待):https://github.com/zhuole1025/SymMV

DiLiGenT-Pi
DiLiGenT-Pi: Photometric Stereo for Planar Surfaces with Rich Details - Benchmark Dataset and Beyond
DiLiGenT-Π 是一个新的真实世界数据集,旨在填补在光度立体照相技术中缺乏对富含细节的近平面表面的现实世界数据集的空白。包含了 30 个具有丰富表面细节的近平面物体。
论文链接:https://photometricstereo.github.io/imgs/diligentpi/paper.pdf
项目链接(开源):https://photometricstereo.github.io/diligentpi.html

水下视频数据集
Self-supervised Monocular Underwater Depth Recovery, Image Restoration, and a Real-sea Video Dataset
DRUVA(Dataset of Real-world Underwater Videos of Artifacts)是一个用于深海水域的真实世界水下视频数据集。包含 20 个不同文物(主要是尺寸为 0.5 米至 1 米的水下岩石)在浅水区的视频序列。每个文物一个视频,时长约 1 分钟,包含文物在距离摄像机 0.5 米至 4 米深处的近 360 ◦方位视角。
DRUVA 可供水下(UW)研究人员用于三维重建、使用神经辐射场(NeRFs)进行新型视图合成、视频插值和 extrapolation(外推法)等。
论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Varghese_Self-supervised_Monocular_Underwater_Depth_Recovery_Image_Restoration_and_a_Real-sea_ICCV_2023_paper.pdf
项目链接:https://github.com/nishavarghese15/DRUVA

水生物数据集
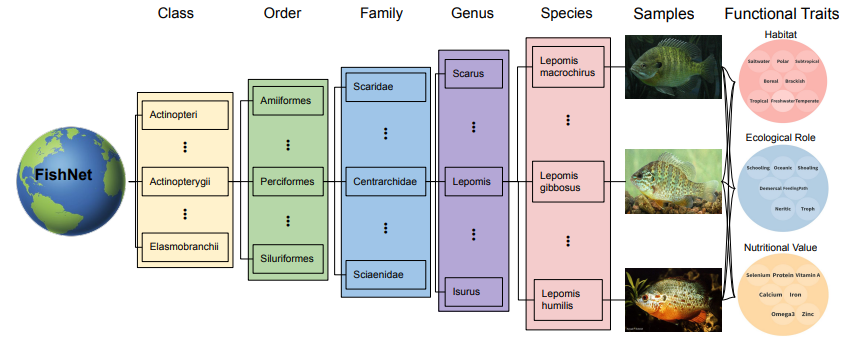
FishNet: A Large-scale Dataset and Benchmark for Fish Recognition, Detection, and Functional Traits Prediction
FishNet 是一个大规模多样化的数据集,包含了来自 17357 种水生物的 94532 张精心整理的图像。这些图像根据水生物的生物分类学(目、科、属、种)进行了组织。旨在满足对能够识别、定位和预测物种及其功能特征的系统需求。
论文链接:https://openaccess.thecvf.com//content/ICCV2023/html/Khan_FishNet_A_Large-scale_Dataset_and_Benchmark_for_Fish_Recognition_Detection_ICCV_2023_paper.html
项目链接:https://fishnet-2023.github.io/
视觉与语言
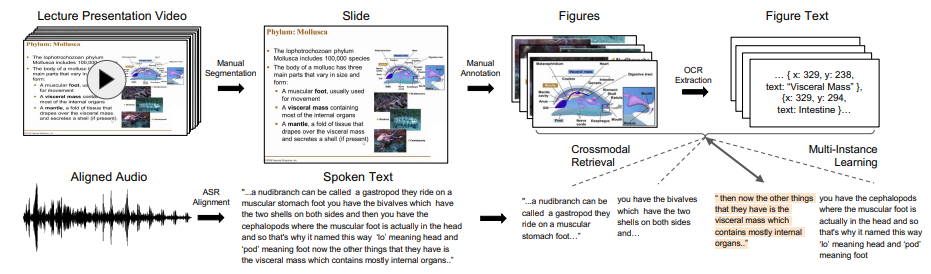
Lecture Presentations Multimodal Dataset: Towards Understanding Multimodality in Educational Videos
Lecture Presentations Multimodal (LPM) Dataset是一个大规模的数据集,旨在作为测试视觉与语言模型在多模态理解教育视频方面能力的基准。该数据集包含了对齐的幻灯片和口头语言,涵盖了180多小时的视频和9000多张幻灯片,涉及来自不同学科(如计算机科学、牙科、生物学)的10名讲师。
论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Lee_Lecture_Presentations_Multimodal_Dataset_Towards_Understanding_Multimodality_in_Educational_Videos_ICCV_2023_paper.pdf
项目链接(开源):https://github.com/dondongwon/LPMDataset
手部姿势
RenderIH: A Large-scale Synthetic Dataset for 3D Interacting Hand Pose Estimation
RenderIH是一个大规模的合成数据集,旨在提供准确和多样化的姿势标注,以用于交互手部研究。该数据集包含了100万张照片逼真的图像,具有各种不同的背景、视角和手部纹理。
在本次任务中,为了生成自然且多样化的交互姿势,提出一种新的姿势优化算法。以及为了提高姿势估计的准确性,引入基于Transformer的姿势估计网络TransHand,以利用交互手部之间的相关性,并验证了RenderIH在提升结果方面的有效性。
实验证明,在合成数据上进行预训练可以显著将误差从6.76mm降低到5.79mm,而TransHand超越了现有方法。
论文链接:https://arxiv.org/abs/2309.09301
项目链接(开源):https://github.com/adwardlee/RenderIH

超分辨率
A Large-Scale Multi-Reference Dataset for Reference-based Super-Resolution
LMR(Large-scale Multi-Reference)是一个大规模的多参考图像超分辨率(RefSR)数据集。包含 112,142 组300x300 的训练图像,是现有最大的 RefSR 数据集的 10 倍。图像的尺寸也大得多。更重要的是,每组图像配备了 5 个不同相似度级别的参考图像。
另外,提出一种新的多参考超分辨率基准方法:MRefSR,包括一个用于任意数量参考图像特征融合的多参考关注模块(MAM)和一个用于融合特征选择的空间感知过滤模块(SAFM)。
MRefSR 在定量和定性评估方面都比最先进的方法有显著改进。
论文链接:https://arxiv.org/abs/2303.04970
项目链接(待):https://github.com/wdmwhh/MRefSR

目标跟踪
360VOT: A New Benchmark Dataset for Omnidirectional Visual Object Tracking
360VOT 是一个新的大规模全景追踪基准数据集,旨在为全景视觉物体追踪提供支持。这个数据集包含了 120 个序列,总计超过 11.3 万张高分辨率帧,采用等距投影。追踪的目标涵盖了 32 个不同的类别,场景多样。
此外,还提供了 4 种无偏差的ground truth,包括(旋转)边界框和(旋转)边界视场,以及为 360° 图像量身定制的新指标,从而可以准确评估全景跟踪性能。
论文链接:https://arxiv.org/abs/2307.14630
项目链接(开源):https://360vot.hkustvgd.com/

细粒度物体理解
EgoObjects: A Large-Scale Egocentric Dataset for Fine-Grained Object Understanding
EgoObjects 是一个大规模的主观视角数据集,旨在进行细粒度物体理解,该领域被认为是主观视角视觉的一个基础研究课题。其试验版本包含了来自 50 多个国家的 250名参与者使用 4 种可穿戴设备收集的超过 9,000 个视频,以及来自 368 个物体类别的超过 650,000 个物体标注。与先前的数据集不同,EgoObjects 不仅仅包含了物体类别标签,还为每个物体提供了实例级别的标识,并包括了超过 14,000 个独特的物体实例。
论文链接:https://arxiv.org/abs/2309.08816
项目链接:https://github.com/facebookresearch/EgoObjects

城市建模
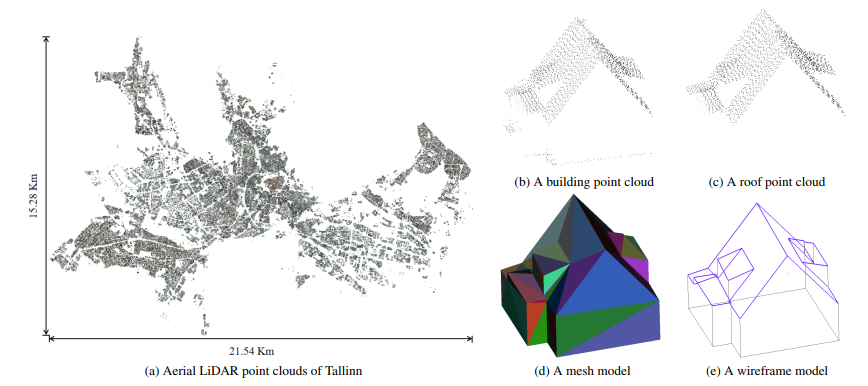
Building3D: A Urban-Scale Dataset and Benchmarks for Learning Roof Structures from Point Clouds
Building3D 是一个城市尺度数据集,用于利用航空激光雷达点云进行建筑物屋顶建模。它包括超过16万栋建筑物,覆盖了Estonia 的16个城市,总计约998平方公里。除了网格模型和真实世界LiDAR点云外,这是首次发布线框模型。Building3D 将促进未来在城市建模、航空路径规划、网格简化和语义/部件分割等方面的研究。
论文链接:https://arxiv.org/abs/2307.11914
项目链接(开源):https://building3d.ucalgary.ca/
美学评估数据集
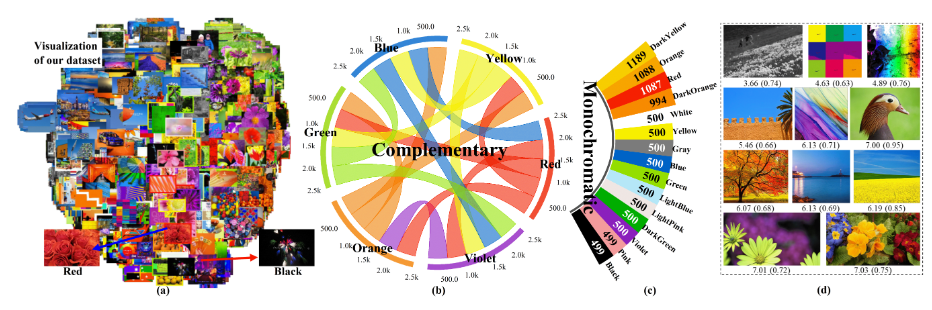
Thinking Image Color Aesthetics Assessment: Models, Datasets and Benchmarks
首个面向图像【色彩】的美学评估数据集,1万7千张左右图像,按色彩搭配的类型进行标注。
论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/He_Thinking_Image_Color_Aesthetics_Assessment_Models_Datasets_and_Benchmarks_ICCV_2023_paper.pdf
项目链接:https://github.com/woshidandan/Image-Color-Aesthetics-Assessment
文档去除阴影
High-Resolution Document Shadow Removal via A Large-Scale Real-World Dataset and A Frequency-Aware Shadow Erasing Net
SD7K 是一个用于高分辨率文档去除阴影的大规模实际世界数据集。它包括了超过7,000对高分辨率(2462 x 3699)的真实世界文档图像,这些图像来自不同光照条件下的各种样本。相比现有的数据集,这个数据集的规模大了10倍。
论文链接:https://arxiv.org/abs/2308.14221
项目链接(开源):https://github.com/CXH-Research/DocShadow-SD7K

合成视觉数据集(XAI)
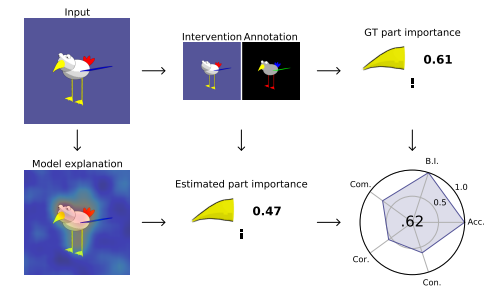
FunnyBirds: A Synthetic Vision Dataset for a Part-Based Analysis of Explainable AI Methods
FunnyBirds 是一个新的合成视觉数据集,旨在支持可解释人工智能(XAI)研究。该数据集解决了XAI领域中一个尚未解决的问题,即如何自动评估解释的质量,因为XAI缺乏ground-truth解释。FunnyBirds数据集允许进行语义上有意义的图像干预,例如移除个体对象的部分,这具有三个重要的影响:
首先,它使得可以在部分层面上分析解释,这比现有方法在像素级别上评估更接近人类理解。
其次,通过比较对移除部分的输入的模型输出,可以估计出应该在解释中反映的ground-truth部分重要性。
第三,通过将个体解释映射到一个共同的部分重要性空间,可以在一个统一的框架中分析各种不同类型的解释。
利用这些工具,研究者们对24种不同组合的神经模型和XAI方法进行了评估,以全自动和系统化的方式展示了评估方法的优缺点。
论文链接:https://arxiv.org/abs/2308.06248
项目链接:https://github.com/visinf/funnybirds
主观视角人际互动数据集
HoloAssist: an Egocentric Human Interaction Dataset for Interactive AI Assistants in the Real World
HoloAssist是一个大规模的主观视角人际互动数据集,旨在为开发可以在物理世界中与人类互动的智能代理提供支持。在这个数据集中,两名参与者共同完成物理操作任务。任务执行者戴着混合现实头戴式设备,可以捕捉到七个同步的数据流。任务指导者实时观看执行者的主观视角视频,并通过口头指导来引导他们完成任务。HoloAssist 的数据采集时间长达 169 个小时,采集对象包括 350 对不同的指导者和执行者。
论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Wang_HoloAssist_an_Egocentric_Human_Interaction_Dataset_for_Interactive_AI_Assistants_ICCV_2023_paper.pdf
项目链接:https://holoassist.github.io/

三维全身姿态
H3WB: Human3.6M 3D WholeBody Dataset and Benchmark
Human3.6M 3D WholeBody (H3WB)数据集使用 COCO Wholebody 布局为 Human3.6M 数据集提供全身标注。H3WB 包括 100K 幅图像上的 133 个全身关键点标注,得益于新开发的多视图处理流程。
在本次任务中,还提出了三项任务:
从二维完整全身姿态提取三维全身姿态;
从二维不完整全身姿态提取三维全身姿态;
从单张 RGB 图像估算三维全身姿态。
此外,还针对这些任务报告了几种常用方法的基线。以及提供了 TotalCapture 的自动三维全身标注,实验表明,与 H3WB 配合使用有助于提高性能。
论文链接:https://arxiv.org/abs/2211.15692
项目链接:https://github.com/wholebody3d/wholebody3d

热红外盲道分割
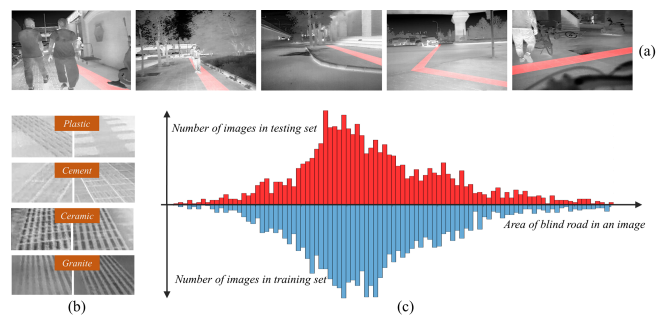
Atmospheric Transmission and Thermal Inertia Induced Blind Road Segmentation with a Large-Scale Dataset TBRSD
TBRSD(Thermal Blind Road Segmentation Dataset)是一个用于热红外盲道分割的大规模数据集。该数据集的目的是为了训练和评估热红外图像分割模型,以增强计算机视觉辅助盲人行走系统的安全性。数据集中包含了5180个像素级别的手动标注,用于指示图像中盲道的位置。
论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Chen_Atmospheric_Transmission_and_Thermal_Inertia_Induced_Blind_Road_Segmentation_with_ICCV_2023_paper.pdf
项目链接:https://xzbai.buaa.edu.cn/datasets.html
视觉目标检测
V3Det: Vast Vocabulary Visual Detection Dataset
V3Det是一个用于视觉目标检测的大规模词汇视觉检测数据集,具有精确标注的大规模图像边界框。该数据集具有以下吸引人的特点:
词汇量大: V3Det包含来自13,204个类别的真实世界图像上的物体边界框,比现有的大规模词汇目标检测数据集(如LVIS)大10倍。
分层类别组织: V3Det的广泛词汇通过一个分层类别树组织,该树标注了类别之间的包含关系,鼓励在广泛和开放词汇的目标检测中探索类别关系。
丰富的标注: V3Det包括在243,000张图像中精确标注的物体,以及由人类专家和强大的聊天机器人编写的每个类别的专业描述。
通过提供广泛的探索空间,V3Det可以在广泛和开放词汇的目标检测方面进行广泛的基准测试,从而为未来研究提供新的观察、实践和见解。
论文链接:https://arxiv.org/abs/2304.03752
项目链接:https://v3det.openxlab.org.cn/

海上全景障碍物检测
LaRS: A Diverse Panoptic Maritime Obstacle Detection Dataset and Benchmark
LaRS(Lakes, Rivers and Seas)是一个用于海上全景障碍物检测的基准数据集。它旨在弥补海上障碍物检测领域缺乏多样性数据集的问题,以充分捕捉一般海上环境的复杂性。
LaRS 包括了超过 4000 帧的关键帧,每个帧都进行了逐像素标注,还包括了前面的九帧以利用时间纹理,总计超过 40,000 帧。每个关键帧都标注了 11 个物体和物质类别以及 19 个全局场景属性。
论文链接:https://arxiv.org/abs/2308.09618
项目链接(开源):https://lojzezust.github.io/lars-dataset/

360°全景图像数据集
Beyond the Pixel: a Photometrically Calibrated HDR Dataset for Luminance and Color Prediction
Laval Photometric Indoor HDR Dataset 是第一个大规模的光度校准的高动态范围(HDR)360°全景图像数据集。
论文链接:https://arxiv.org/abs/2304.12372
项目链接:https://lvsn.github.io/beyondthepixel/

珍稀动物数据集
LoTE-Animal: A Long Time-span Dataset for Endangered Animal Behavior Understanding
LoTE-Animal(Large-scale Endangered Animal Dataset)是一个为了促进深度学习在珍稀物种保护中的应用而收集的大规模珍稀动物数据集,历时12年。
数据集包含了丰富的变化,如生态季节、天气条件、时间段、视角和栖息地场景。到目前为止,已经收集到了至少50万个视频和120万张图像。其中选择并标注了11种濒危动物以进行行为理解,包括1万个视频序列用于动作识别任务,2.8万张图像用于目标检测、实例分割和姿态估计任务。此外,还收集了7千张同一物种的网络图像作为源域数据,用于域自适应任务。
论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Liu_LoTE-Animal_A_Long_Time-span_Dataset_for_Endangered_Animal_Behavior_Understanding_ICCV_2023_paper.pdf
项目链接:https://lote-animal.github.io/

6DoF
Aria Digital Twin: A New Benchmark Dataset for Egocentric 3D Machine Perception
Aria Digital Twin (ADT)是一个使用Aria眼镜捕获的以自我为中心的数据集,包含大量物体、环境和人类层面 ground-truth 的数据。
ADT 包含 Aria 佩戴者在两个真实室内场景中进行的 200 个真实世界活动序列,其中有 398 个对象实例(324 个静态和 74 个动态)。每个序列包括:
两个单色摄像头流、一个 RGB 摄像头流和两个 IMU 流的原始数据;
完整的传感器校准;
ground-truth 数据,包括 Aria 设备的连续 6 自由度 (6DoF) 姿态、物体 6DoF 姿态、三维眼球注视矢量、三维人体姿态、二维图像分割、图像深度图;
照片般逼真的合成渲染。
论文链接:https://arxiv.org/abs/2306.06362


END
加入「计算机视觉」交流群👇备注:CV
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









