






关注公众号,发现CV技术之美
大模型走向空间智能、具身智能之路!
智源,斯坦福,北大,牛津,东大联合推出SpatialBot , 通过理解和使用深度图来理解空间。

论文标题: SpatialBot: Precise Depth Understanding with Vision Language Models
论文链接: https://arxiv.org/abs/2406.13642
项目主页: https://github.com/BAAI-DCAI/SpatialBot
RGB+Depth可以作为多模态大模型(MLLM/VLM)理解空间的途径,但是:
现有模型无法直接理解深度图输入。比如CLIP在训练时,没有见过深度图。
现有大模型数据集,大多仅用RGB就可以分析、回答。模型不会主动到深度图中索引知识。

因此,作者提出:
三个层次的 SpatialQA 数据集。在low level引导模型理解深度图,在middle level让模型将depth与RGB对齐,在high level设计多个深度相关任务,标注了50k的数据,让模型在理解深度图的基础上,使用深度信息完成任务。
SpatialBench 榜单。精心设计和标注的QA,测试模型深度理解能力。
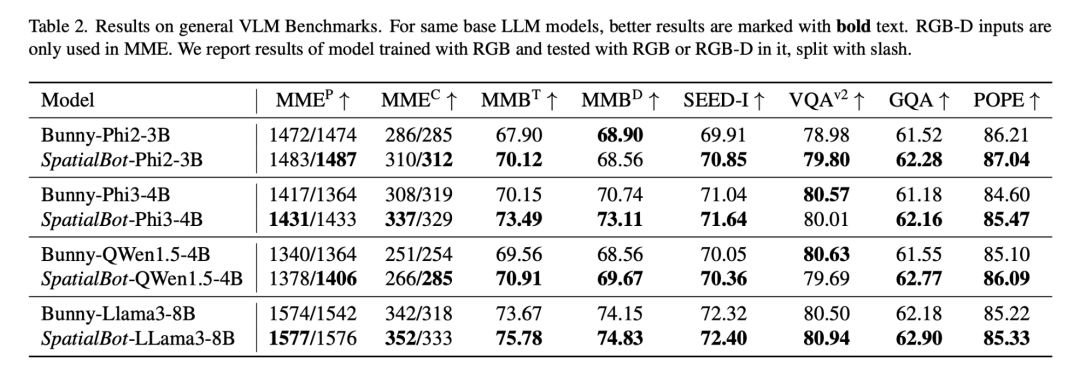
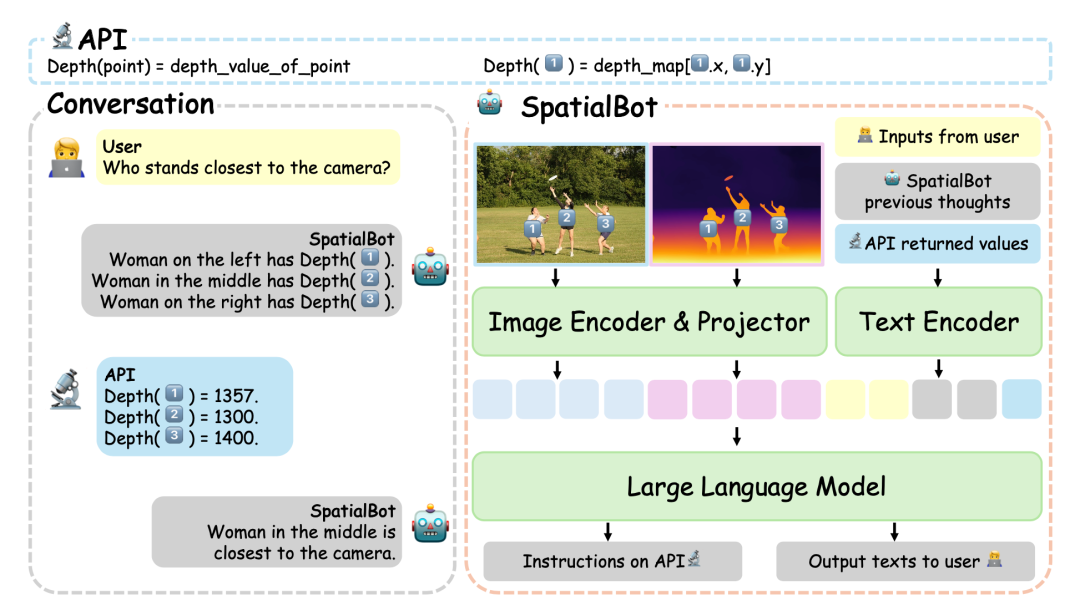
SpatialBot 模型。模型在需要时,可以通过API获取准确的深度信息。SpatialBot基于3B到8B的多个base LLM,在SpatialBench、常用MLLM数据集(MME, MMBench等)和具身数据上取得显著提升。

技术细节
作者将深度图转化为3通道的伪RGB图,在兼顾室内高精度、室外大范围场景的需求下,尽可能保留所有深度信息供模型索引。以毫米为单位,囊括1mm到131m。
SpatialQA是RGBD的MLLM数据集,作者公布了详细的如何将现有CV任务的RGB或RGBD数据集,MLLM训练集,转化为SpatiaQA的pipeline,以及其中的数据标注细节。
最近大火的Cambrain-1 (LeCun Yann, Saining Xie)提出MLLM四大问题,其中之一是物体远近关系判断(proximity)。其实,在此之前,在SpatialBot提出的DepthAPI, 就以99+%的准确率解决了深度信息和远近关系的问题。
实验效果和DepthAPI

END
欢迎加入「大模型」交流群👇备注:LLM
















 1121
1121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









