







1.基本形式

2.线性回归
1)输入一维,输出一维

2)输入多维,输出一维


3)输入多维,输出多维

4)广义线性模型

3.对数几率回归

4.线性判别分析

5.多分类学习


6.类别不平衡问题


# 导入包
from sklearn.datasets import make_classification
from collections import Counter
from imblearn.over_sampling import RandomOverSampler
# 生成样本集,用于分类算法:3类,5000个样本,特征维度为2
X, y = make_classification(n_samples=5000, n_features=2, n_informative=2,
n_redundant=0, n_repeated=0, n_classes=3,
n_clusters_per_class=1,
weights=[0.01, 0.05, 0.94],
class_sep=0.8, random_state=0)
# 打印每个类别样本数
print(Counter(y))

# 过采样
ros = RandomOverSampler(random_state=0)
X_resampled, y_resampled = ros.fit_resample(X, y)
# 打印过采样后每个类别样本数
print(sorted(Counter(y_resampled).items()))
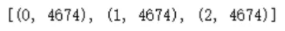

# 导入包
from imblearn.over_sampling import SMOTE
# 过采样
sm = SMOTE(random_state=42)
X_res, y_res = sm.fit_resample(X, y)
# 打印过采样后每个类别样本数
print('Resampled dataset shape %s' % Counter(y_res))


# 导入包
from imblearn.under_sampling import RandomUnderSampler
# 欠采样
rus = RandomUnderSampler(random_state=0)
X_resampled, y_resampled = rus.fit_resample(X, y)
# 打印欠采样后每个类别样本数
print(sorted(Counter(y_resampled).items()))


# 导入包
from imblearn.combine import SMOTEENN
# 过采样与欠采样结合
smote_enn = SMOTEENN(random_state=0)
X_resampled, y_resampled = smote_enn.fit_resample(X, y)
# 打印采样后每个类别样本数
print(sorted(Counter(y_resampled).items()))

# 导入包
from imblearn.combine import SMOTETomek
# 过采样与欠采样结合
smote_tomek = SMOTETomek(random_state=0)
X_resampled, y_resampled = smote_tomek.fit_resample(X, y)
# 打印采样后每个类别样本数
print(sorted(Counter(y_resampled).items()))
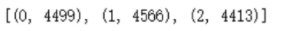

# 导入相关包
from sklearn.svm import SVC
# 添加惩罚项
clf = SVC(C=0.8, probability=True, class_weight={0:0.25, 1:0.75})















 1340
1340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









