







本次要总结的论文题目是FLEN: Leveraging Field for Scalable CTR Prediction,发表于KDD2020,论文链接是FLEN,参考的论文实现代码是flen-code,首先得说这篇论文不值得精读,我大概 断断续续 花了半个星期读完论文和代码,发现根本不值得我思考这么久,实现代码和论文里某些细节不是很符合,对论文里的实验结果表示怀疑。感觉就是篇水文,但是既然读完了,就总结下吧,也许是我水平有限,无法领略文章的深度呢。
文章目录
动机
- 现在的CTR模型普遍基于multi-field 类别型的特征,如何对这种multi-field的类别型特征建模 对 CTR的效果至关重要,同时,如果对所有multi-field 类别特征建模,需要大量参数,故其无法应用于实际的生产环境。
- 本论文提出了FLEN方法,并已经实际应用在美图的线上环境上,其创新点主要有三点
- 在只需增加少量参数和时间复杂度允许的情况下,捕捉到 inter-field and intra-field feature(域内和域间)有用的特征。
- 提出的Dicefactor结构可以缓解FM模型中梯度耦合的问题。
这里面说的 缓解所谓”梯度耦合“问题就是个玄学了,首先说下啥是梯度耦合,指的是FM模型中特征交叉时,不同特征的参数向量 算内积 互相影响着 学习时,可能会让这两个不同域的特征参数向量 朝着同一方向 更新。从而让模型的表达能力受限。
模型
样本定义

这里假设 样本特征有M个域,将
F
(
n
)
F(n)
F(n) 定义为第
n
n
n 个特征的域,则一个样本可以这样来表示
X
=
c
o
n
c
a
t
(
x
1
,
x
2
,
.
.
.
,
x
M
)
X = concat(x_1, x_2,...,x_M)
X=concat(x1,x2,...,xM)
x
m
=
c
o
n
c
a
t
(
x
n
∣
F
(
n
)
=
m
)
x_m= concat(x_n|F(n)=m)
xm=concat(xn∣F(n)=m)
注意:这里面全是onehot或者multi-hot特征。
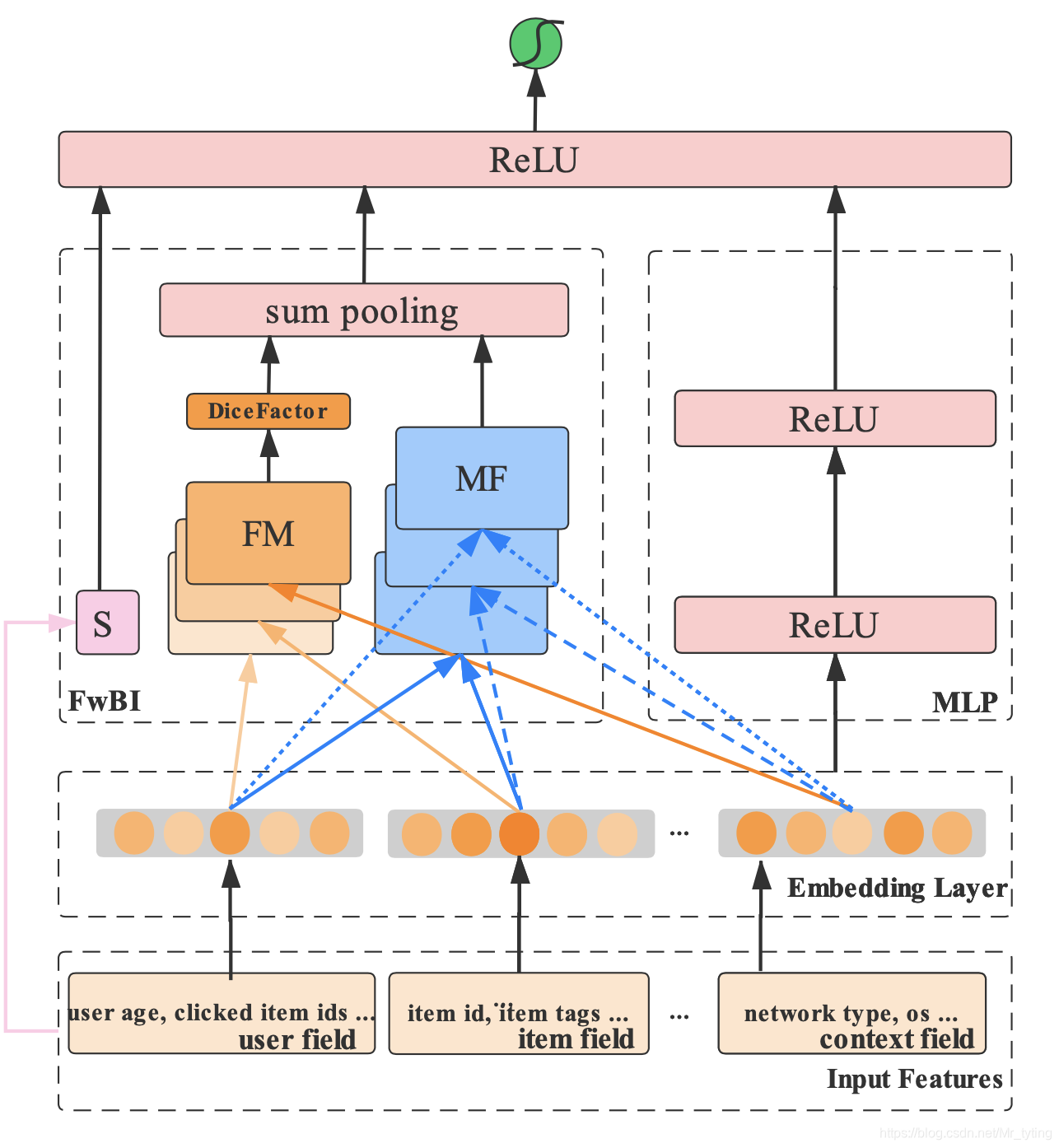
Embedding Layer
对于每个特征
x
n
x_n
xn,可通过如下计算,得到embedding矩阵
e
n
=
V
n
x
n
e_n=V_nx_n
en=Vnxn
其中
V
n
V_n
Vn 为模型需要学习的参数。
由此得到域的embedding矩阵,由这个域内的所有特征的embedding求和得到
e
m
=
∑
n
∣
F
(
n
)
=
m
e
n
e_m = \sum_{n|F(n)=m} e_n
em=n∣F(n)=m∑en
Field-wise Bi-Interaction Pooling Layer
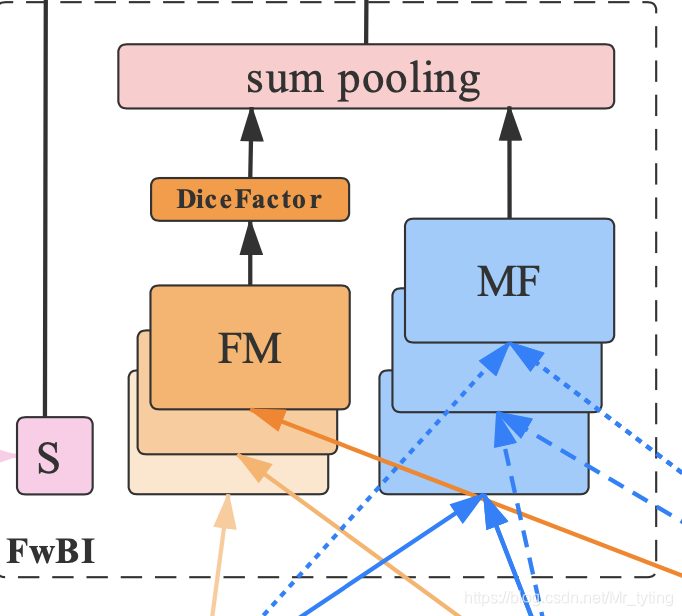
我们看上图,由三部分组成,第一部分是 S S S, 第二部分是 F M FM FM,第三部分是 M F MF MF
S
S
S 部分是:
h
S
=
w
0
+
∑
i
=
1
N
∑
j
=
1
K
i
w
i
[
j
]
x
i
[
j
]
h_S = w_0+\sum_{i=1}^N\sum_{j=1}^{K_i} w_i[j]x_i[j]
hS=w0+i=1∑Nj=1∑Kiwi[j]xi[j]
上式中 w 0 w_0 w0 对于所有特征是一样的, N N N 表示特征数量, k i k_i ki 表示第 i i i 个特征的取值个数。 w i [ j ] w_i[j] wi[j] 表示 第 i i i个特征的第 j j j个取值的权重, x i [ j ] x_i[j] xi[j] 表示第 i i i 个特征第 j j j 个取值。这里面 记 W s = w 0 ∣ ∣ w i W_s = w_0 || w_i Ws=w0∣∣wi
注意假设这里面全是onehot或者multi-hot特征
M
F
MF
MF 部分:
h
M
F
=
∑
i
=
1
M
∑
j
=
i
+
1
M
e
i
⊙
e
j
r
[
i
]
[
j
]
h_{MF} = \sum_{i=1}^{M}\sum_{j=i+1}^{M} e_i \odot e_j\ r[i][j]
hMF=i=1∑Mj=i+1∑Mei⊙ej r[i][j]
上式中
M
M
M 表示field个数,
e
i
e_i
ei 表示第
i
i
i 个field的embedding,
⊙
\odot
⊙ 表示field-wise,
r
[
i
]
[
j
]
r[i][j]
r[i][j] 表示第
i
i
i 个域和第
j
j
j 个域的权重,是一个根据经验设置的超参数?论文中并没有讲到,实现代码中直接置为1了。
论文中讲到 M F MF MF 部分是为了 学习 域之间的交互关系。
F
M
FM
FM 部分:
h
f
m
=
e
m
⊙
e
m
hf_m = e_m \odot e_m
hfm=em⊙em
h
t
m
=
∑
n
,
F
(
n
)
=
m
e
n
⊙
e
n
ht_m = \sum_{n, F(n)=m} e_n \odot e_n
htm=n,F(n)=m∑en⊙en
h
F
M
=
∑
m
(
h
f
m
−
h
t
m
)
r
[
m
]
[
m
]
h_{FM}=\sum_{m}(hf_m - ht_m)r[m][m]
hFM=m∑(hfm−htm)r[m][m]
论文中提到 这是为了捕捉 域内的特征交互关系。
由此上述部分的计算记为
Φ
(
W
s
,
R
,
W
f
w
B
I
)
\Phi(W_s, R, W_{fwBI})
Φ(Ws,R,WfwBI),详细数学公式可表示如下:
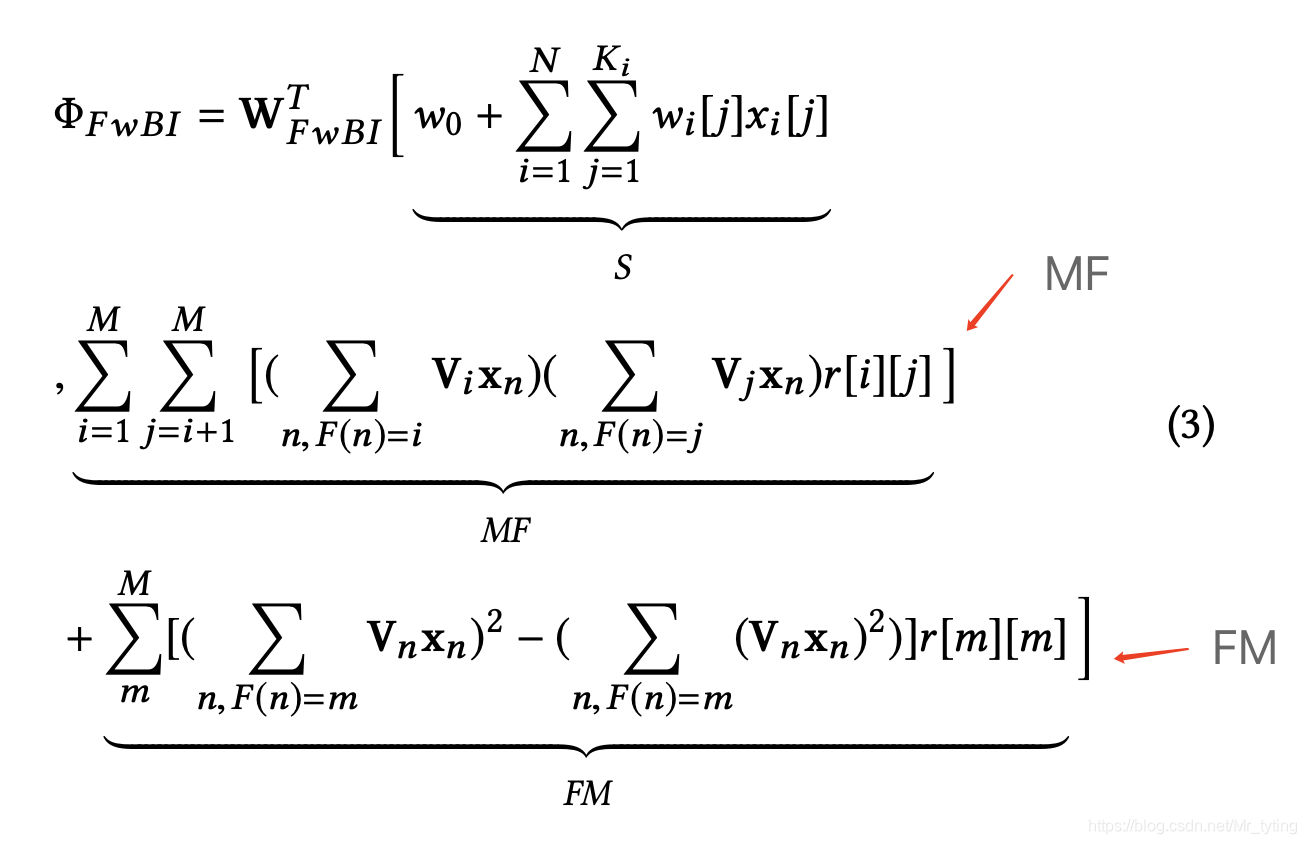
注意上式中:
(
V
x
)
2
=
V
x
⊙
V
x
(Vx)^2 = Vx \odot Vx
(Vx)2=Vx⊙Vx
当只有一个域时,即
M
=
1
,
r
m
,
m
=
1
2
M = 1, r_{m,m} = \frac{1}{2}
M=1,rm,m=21 时:
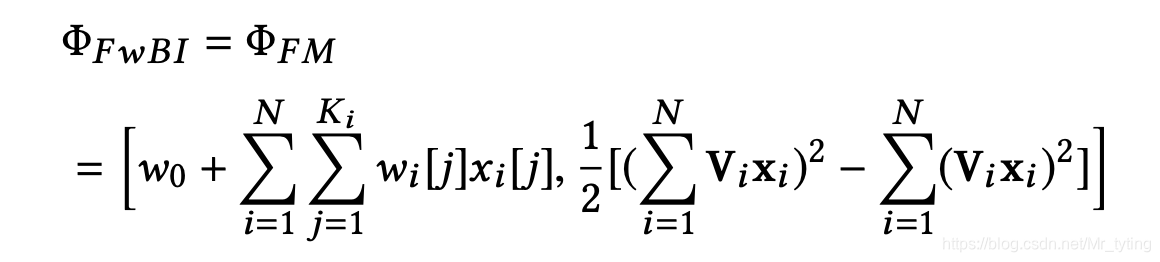
当
M
=
N
M=N
M=N 时:
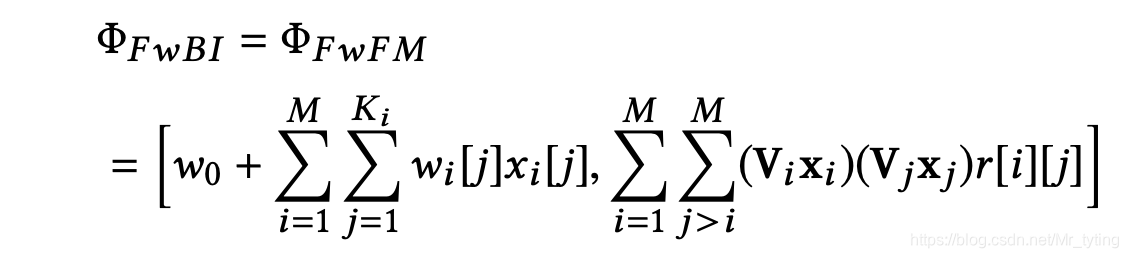
由此得到该部分的输出
h
F
w
B
I
h_{FwBI}
hFwBI。
Dicefactor
上面已经讲到FM模型可能会导致”梯度耦合“ 的问题,因此论文中提出 Dicefactor 方法,简单而言,就是在MF部分,计算 域之间 交互关系时,按照一定的概率丢弃部分交叉路径。
训练阶段:
p
[
i
]
∼
B
e
r
n
o
u
l
l
i
(
β
)
p[i] ∼ Bernoulli(β)
p[i]∼Bernoulli(β)
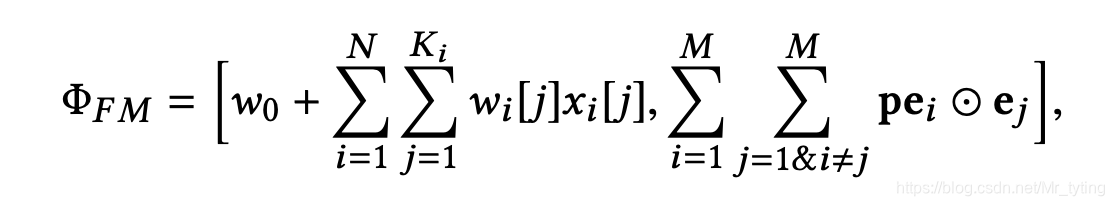
预测阶段:
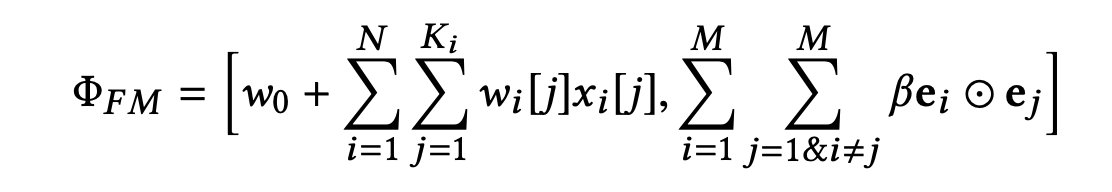
论文中讲到 这样可以减缓 “梯度耦合” 的问题,但是从实验结果来看,收益很小。
MLP
该部分的输入为:
h
0
=
c
o
n
c
a
t
(
e
1
,
e
2
,
.
.
.
,
e
M
)
h_0= concat(e_1,e_2,...,e_M)
h0=concat(e1,e2,...,eM)
然后过 多层的全连接得到 h L h_L hL。
Prediction Layer
比较简单如下:
h
F
=
c
o
n
c
a
t
(
h
F
w
B
I
,
h
L
)
h_F = concat(h_{FwBI, h_L})
hF=concat(hFwBI,hL)
h
F
=
σ
(
W
F
T
h
F
)
h_F = \sigma(W_F^T\ h_F)
hF=σ(WFT hF)
损失函数为交叉熵。
实验结果
论文中对实验进行了详细分析,这里我们只看最后效果
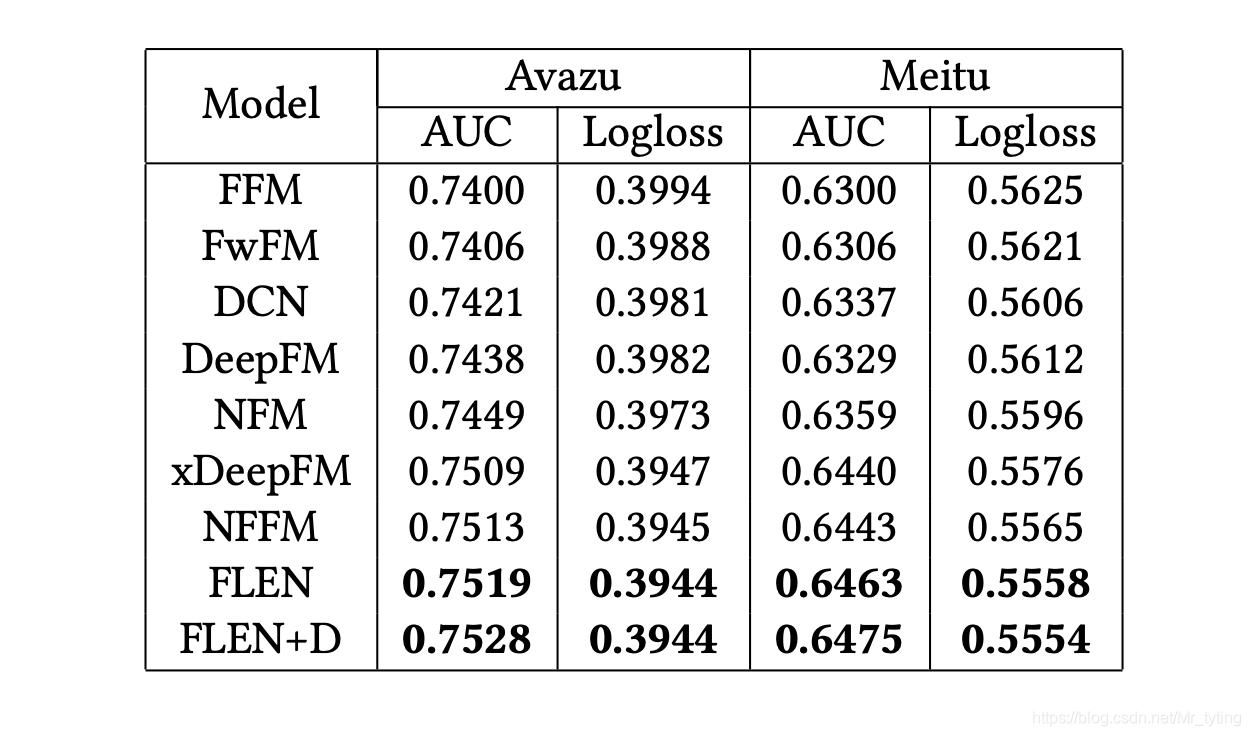
其中FLEN+D 表示加了 Dicefactor 的flen,整体看来,加了所谓的Dicefactor 效果也没好多少,整体收益不大。
核心代码
Field-wise Bi-Interaction
def call(self, inputs, trainable=None, **kwargs):
print("Tracing field_wise_bi_interaction.call()")
left = []
right = []
for i in range(self.num_fields):
for j in range(i + 1, self.num_fields):
left.append(i)
right.append(j)
embeddings = tf.reshape(inputs, [-1, self.num_fields, self.embedding_size])
embeddings_left = tf.gather(params=embeddings, indices=left, axis=1)
embeddings_right = tf.gather(params=embeddings, indices=right, axis=1)
embeddings_prod = tf.multiply(x=embeddings_left, y=embeddings_right)
field_weighted_embedding = tf.multiply(x=embeddings_prod, y=self.kernel)
field_weighted_embedding = tf.reduce_sum(field_weighted_embedding, axis=1)
if self.use_bias:
field_weighted_embedding = tf.nn.bias_add(field_weighted_embedding, self.bias)
if self.activation is not None:
field_weighted_embedding = self.activation(field_weighted_embedding)
return field_weighted_embedding
显然上述代码只计算了 MF部分。
Dicefactor
self.embedding_layers = {}
self.dice_bn_layer = BatchNormalization(momentum=0.9)
self.dice_dropout_layer = Dropout(0.7)
self.dice_fc_layers = jarvis.layers.FullyConnect(units=32, name='dice_fc')
embeddings = tf.concat(values=embeddings, axis=1)
fm_embedding = tf.concat(fm_embeds, axis=1)
fm_embedding = self.dice_fc_layers(fm_embedding)
fm_embedding = self.dice_bn_layer(fm_embedding)
fm_embedding = self.dice_dropout_layer(fm_embedding)
可以看出,这里面并没有实现 p [ i ] ∼ B e r n o u l l i ( β ) p[i] ∼ Bernoulli(β) p[i]∼Bernoulli(β),这也是比较令人疑惑的地方。
个人总结
- 这篇论文是 说 缓解”梯度耦合“的问题,不过论文中没有从实验结果证明是真的缓解了,这也是CTR论文的通病,都说解决解决了什么,其实也没人知道是否真的解决了。
- 开源代码中有几处细节与论文的实现并不一样,由此让人怀疑其论文中的实验结果。
- 如果论文中实验结果是真的,该方法的收益也并不大,个人觉得不值得上线尝试,并且在有关文章下,有读者评论效果还不如deepfm,当然个中细节不得而知。
参考文章
- https://arxiv.org/pdf/1911.04690.pdf
- https://github.com/aimetrics/jarvis














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









