







主要是对[https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Super-Resolution?tab=readme-ov-file]大佬的教程的理解及其翻译,添加了很多自己的东西,个人认为更新手友好一点。实现基于论文《Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network》
文章目录
1.网络概览
SRGAN–超分辨率生成对抗网络,顾名思义由生成器网络和鉴别器网络组成。生成器的目标是学会足够真实地对图像进行超分辨率,使得经过训练可以识别此类人造来源的迹象的鉴别器无法再可靠地分辨出差异。并且两个网络是同时进行训练的。
生成器不仅通过最小化内容损失、进行学习,而且还通过监视鉴别器的方法来学习。通过让生成器以从其输出反向传播时产生的梯度的形式访问鉴别器的内部工作,生成器可以调整自己的参数,从而改变鉴别器的输出,使其对自己有利。
1.1Generator(生成器)
这里使用的是SRResNet结构作为生成器,所以其实SRResNet也是可以自己单独训练的。
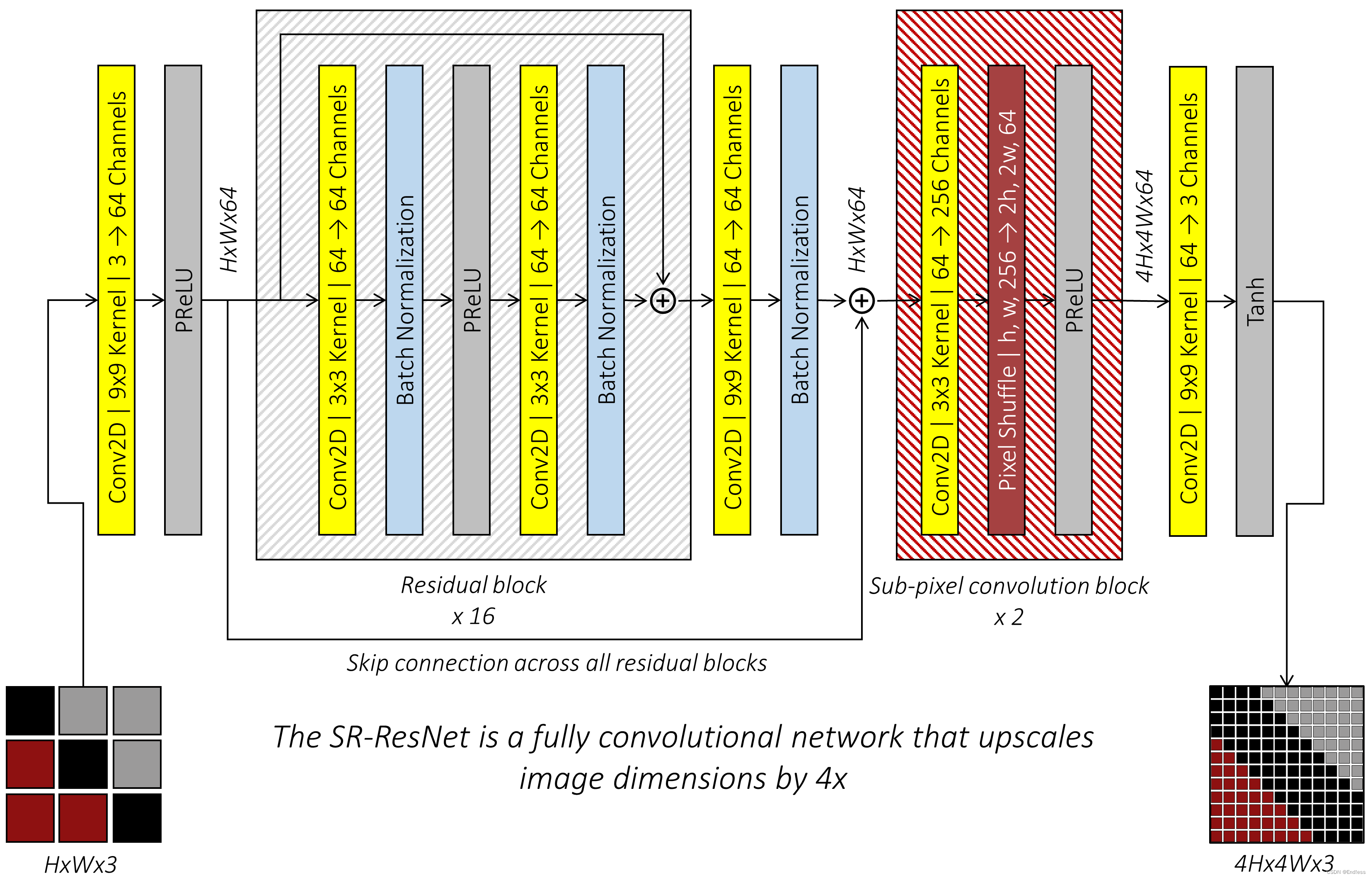
- 首先,将低分辨率图像与较大的卷积核大小进行卷积9×9迈出一步1,生成相同分辨率的特征图,但64通道。应用参数ReLU ( PReLU ) 激活。
- 该特征图通过16 残差块,每个块由一个卷积组成3×3内核和步幅1、批量归一化和PReLU激活、另一个但类似的卷积以及第二个批量归一化。每个卷积层中都保持分辨率和通道数。
- 一系列残差块的结果通过一个卷积层,3×3内核和步幅1,并进行批量归一化。分辨率和通道数保持不变。除了每个残差块中的跳跃连接(根据定义),还有一个更大的跳跃连接横跨所有残差块和这个卷积层。
- 2 子像素卷积块,每个块的尺度增加2(随后进行PReLU激活),产生净 4 倍升级。通道数量保持不变。
- 最后,使用较大的卷积核9×9迈出一步1以更高的分辨率应用,结果经过Tanh激活,生成具有以下范围内RGB 通道的超分辨率图像[−1,1]。
1.2Discriminator (鉴别器)
首先回到它的最本质的特征,用于鉴别一个图片是否由生成器生成的,所以本质上它就是在做分类的工作——二元图像分类器。
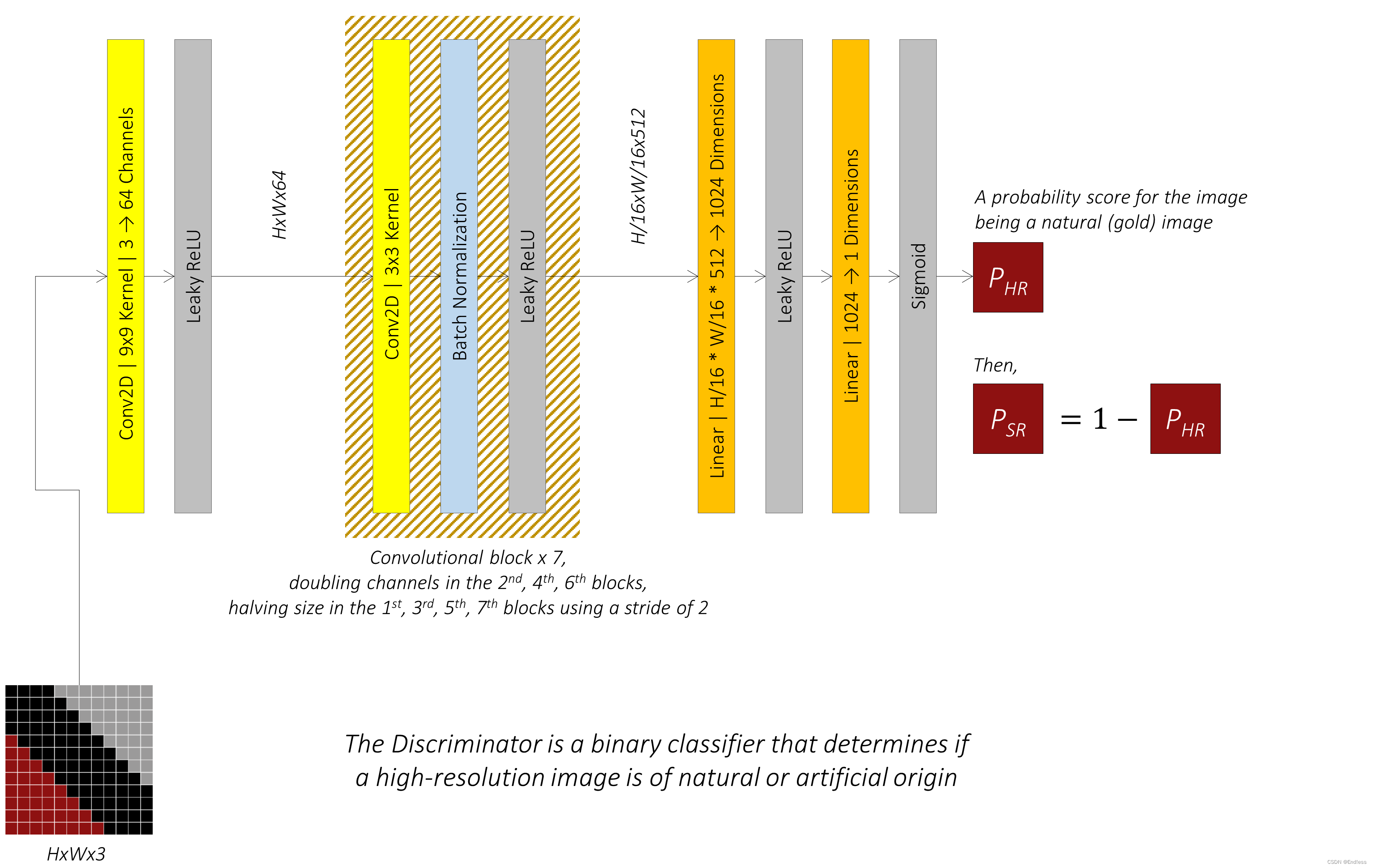
- 将高分辨率图像(真实的/生成的)与一个较大的卷积核做卷积操作( 9 × 9 9\times9 9×9卷积核, s t r i d e = 1 stride=1 stride=1),生成相同分辨率的特征图,64通道。接着是一个Leaky ReLU激活函数。
- 这个特征图通过 7 个卷积块,每个卷积块包含一个3×3的卷积核、批量归一化和Leaky ReLU激活函数。偶数索引的卷积块中通道数量加倍。奇数索引的卷积块中,特征图尺寸通过步幅为2减半。
- 经过这一系列卷积块处理后的结果被展平,并通过线性变换转换成一个尺寸为 1024 的向量,然后应用Leaky ReLU激活函数。
- 最终的线性变换产生一个对数几率(logit),通过Sigmoid激活函数转换成概率分数。这表明原始输入图像是自然(gold)图像的概率。这里原文gold代指的是真实的图像,而不是生成的。
1.3交叉训练
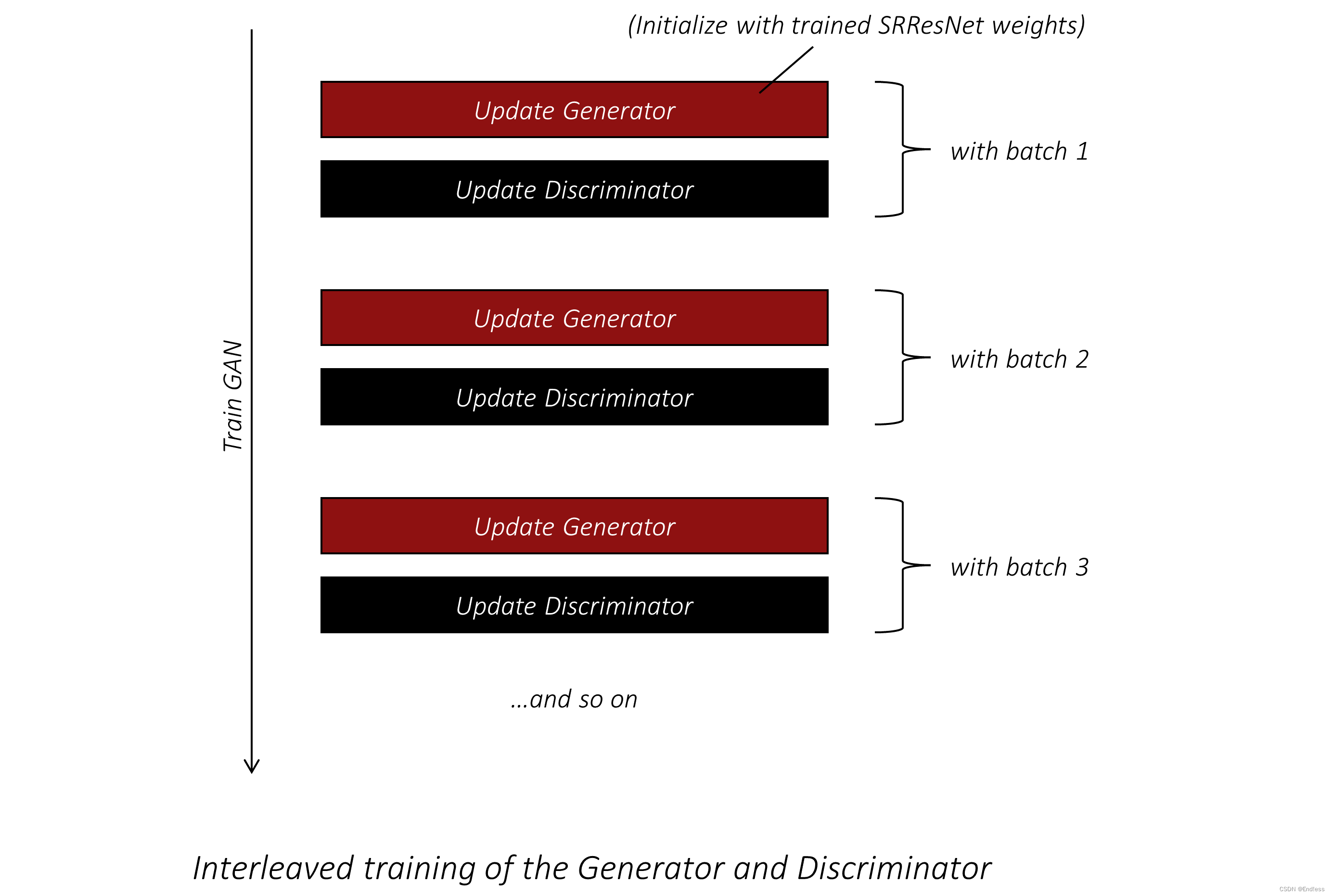
现在的一个疑问可能是,生成器和鉴别器是如何相互训练的?我们先训练哪一个?
他们是一起训练的(如下图所示)。一般来说,任何 GAN 都以交错方式进行训练,其中生成器和鉴别器在短时间内交替训练。
1.4 判别器更新
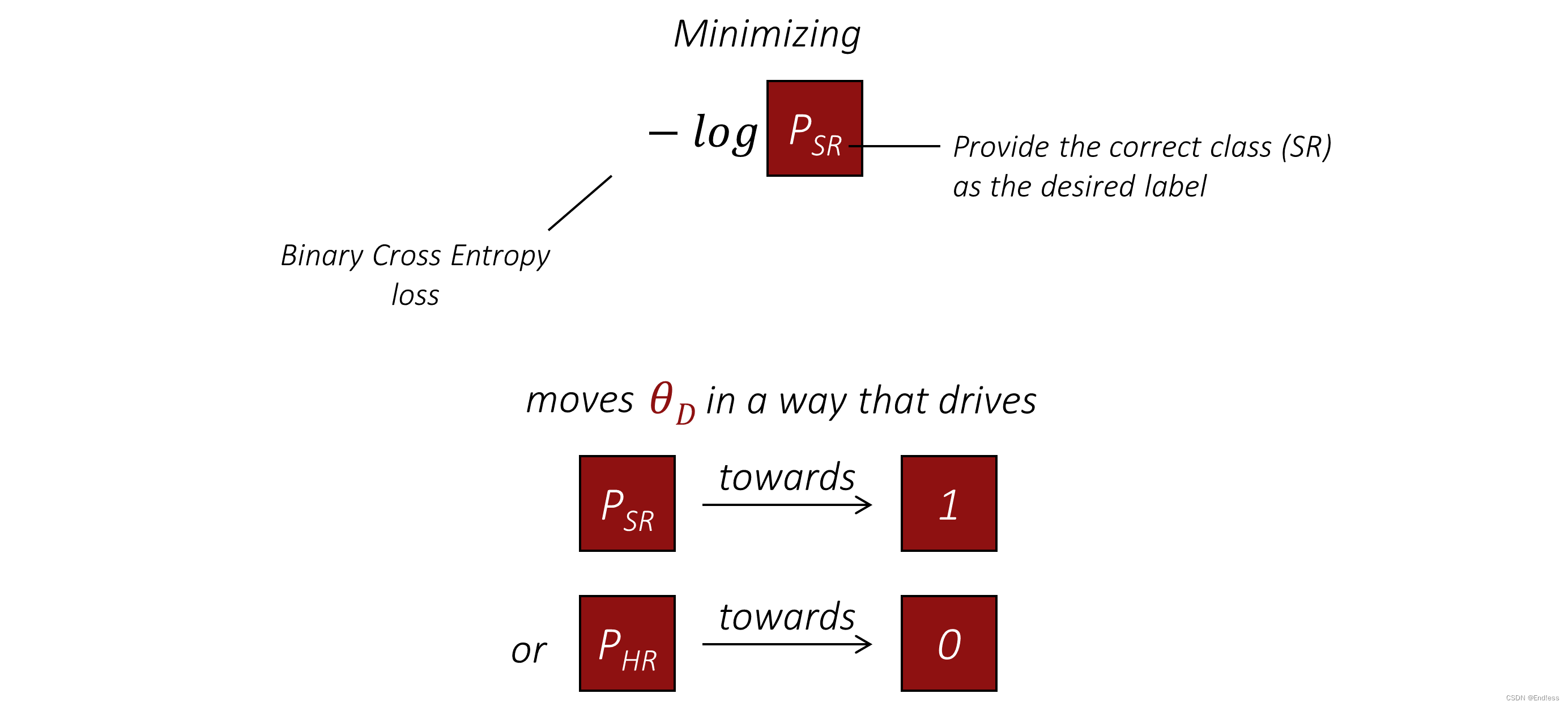
由于判别器将学习区分自然(gold)高分辨率图像和生成器生成的图像,在训练过程中,它会同时被提供自然图像和超分辨率图像,并附有相应的标签(HR vs SR)。
HR: high resolution(自然的高分辨率) SR: super resolution(低分辨率生成的)
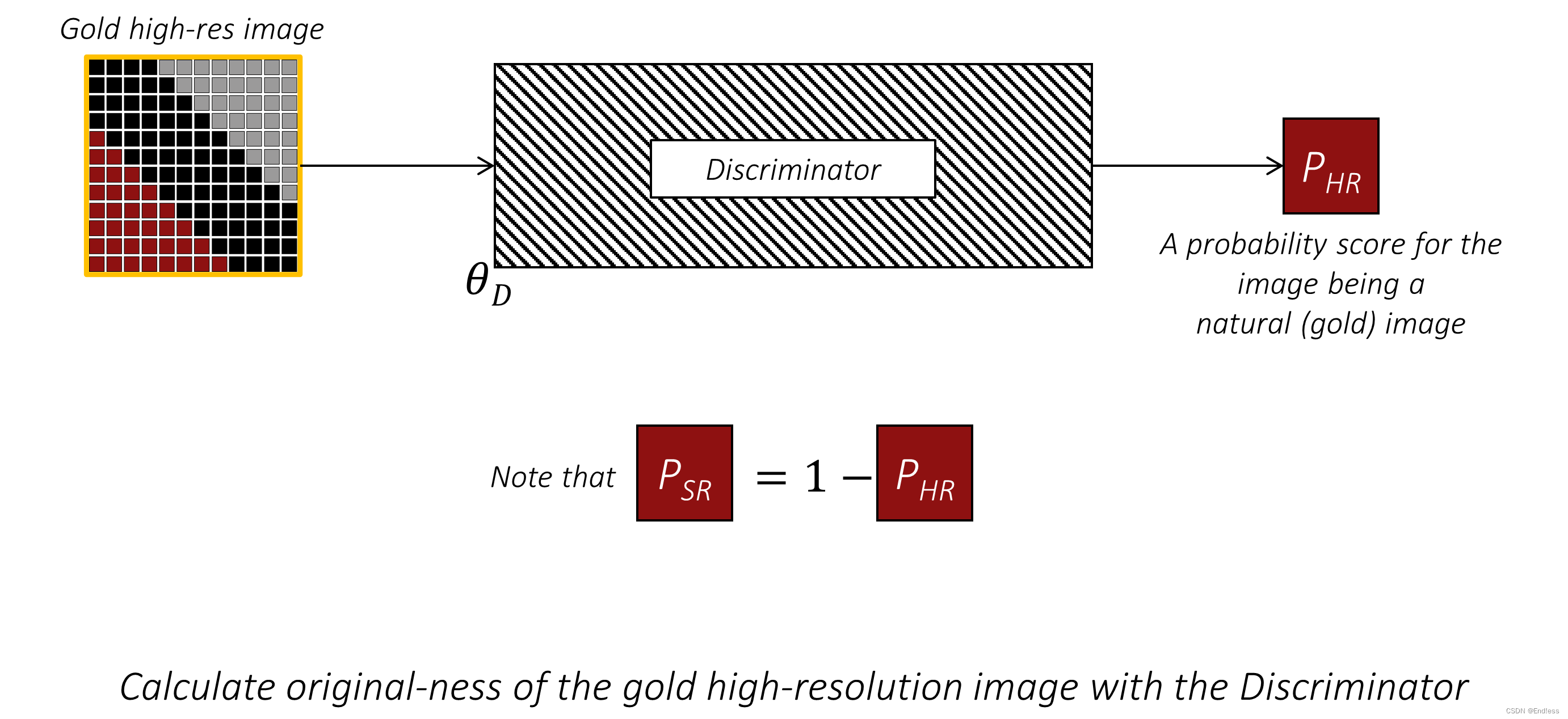
例如,在前向传播过程中,判别器被提供一张自然的高分辨率图像,并生成一个概率分数
P
H
R
P_{HR}
PHR,表示其为自然图像的概率。我们希望鉴别器能够正确地将其识别为Gold图像,并且
P
H
R
P_{HR}
PHR尽可能高。
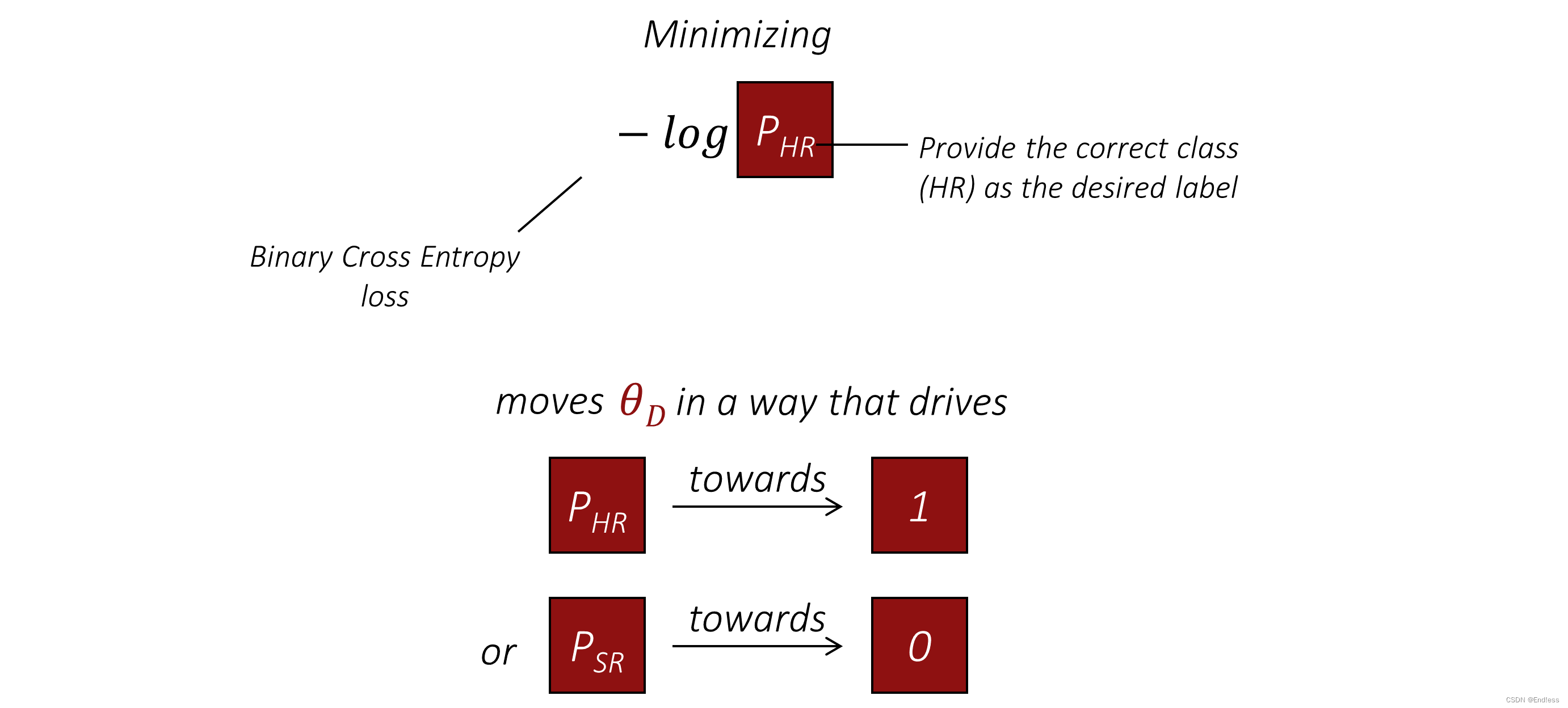
这里简单来说,就是希望鉴别网络通过最小化 − l o g ( P H R ) -log(P_{HR}) −log(PHR),从而学习到的参数 θ D \theta_{D} θD尽可能的使网络能分辨出Gold图片(真实的图片),也就是上图中的 P H R − > 1 P_{HR}-> 1 PHR−>1。
同样的,对于
P
S
R
P_{SR}
PSR也是,我们希望网络学习到的参数
θ
D
\theta_{D}
θD,使得在有一个SR(super resolution,生成的图片)输入时,能让
P
S
R
P_{SR}
PSR的值接近于1。也就是下面这两个图。
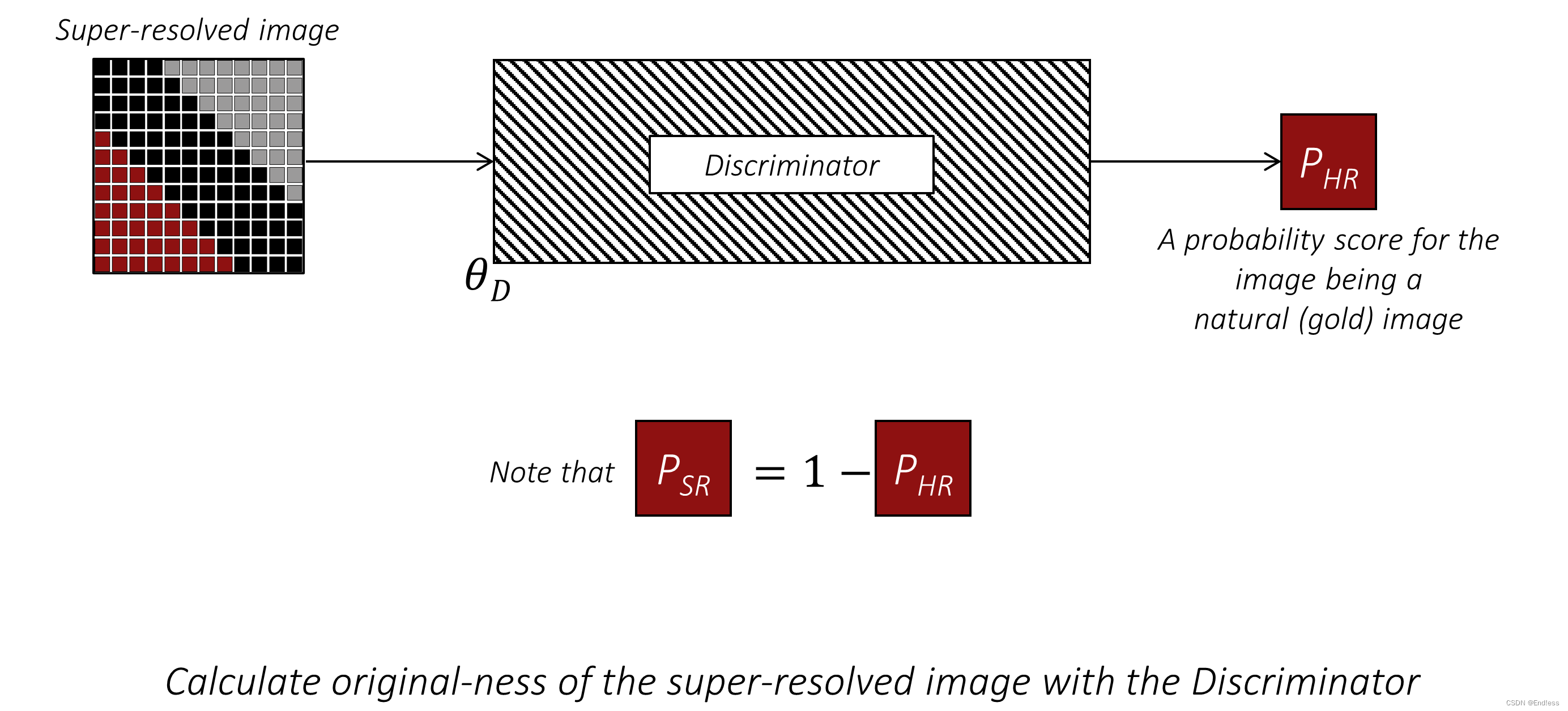
 总而言之,其实就还是那句话,回到本质来说:就是一个二元图片分类器。
总而言之,其实就还是那句话,回到本质来说:就是一个二元图片分类器。
1.5 生成器更新
损失函数造成的问题
在具体实现中,可能会出现SRResNet单独使用看起来图片并不是那么的清晰,相较于SRGAN来说。下面是一个比较明显的示例。

明显SRResNet的图像更平滑一点,下面分析一下原因(稍微有点偏理论,但很好理解):
当对低分辨率图像块或图像进行超分辨率处理时,生成的高分辨率版本通常有多种可能性。换句话说,低分辨率图像中的一小块模糊图像块可以自行解析为多种高分辨率图像块,每个图像块都被视为有效结果。例如下图:
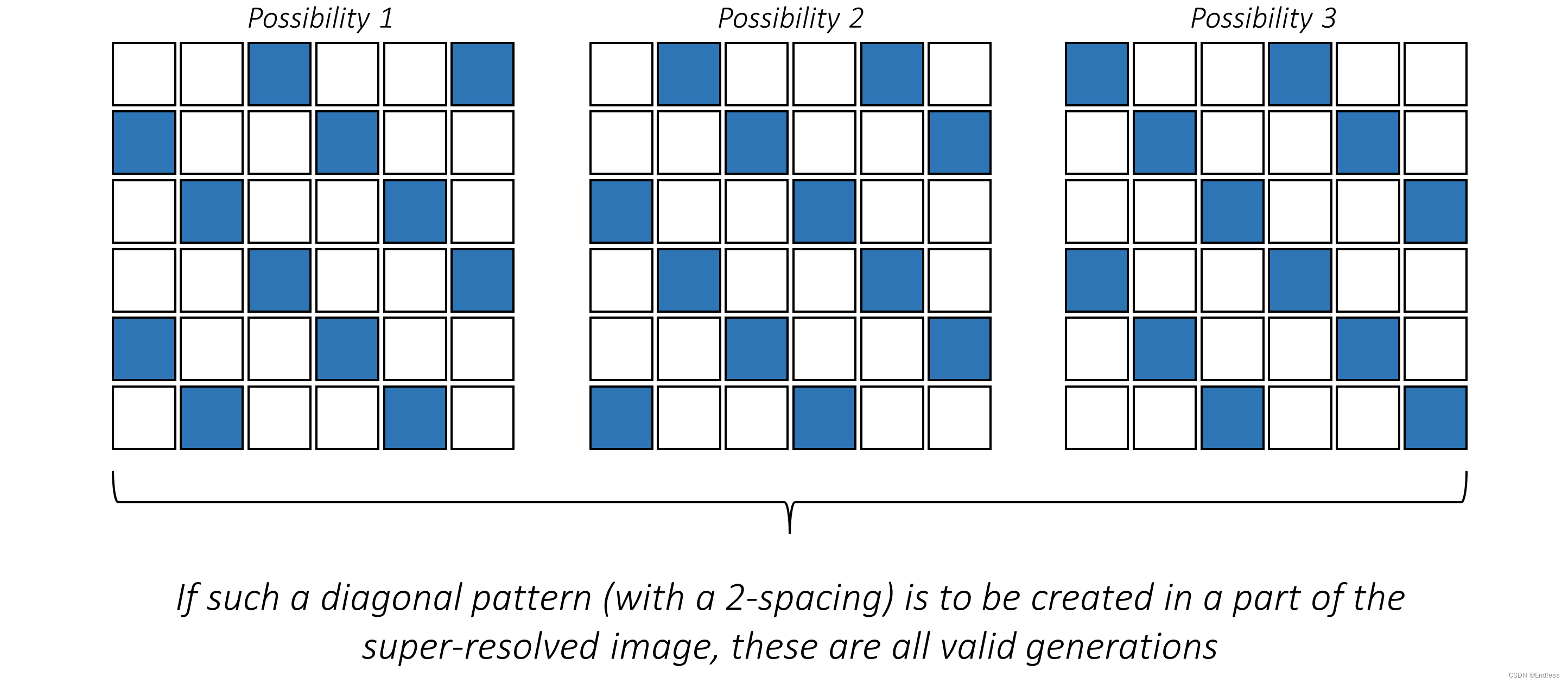
对于一个模糊的图像来说,这三个都很有可能是高分辨率下的图像。那么模型会怎么做决断呢?
像 SRResNet 这样的在 RGB 空间中用content loss训练的网络,不太愿意产生这样的结果。相反,它选择产生某种本质上是精细细节的高分辨率可能性的平均值的东西。这句话有点难理解,想象一下,网络为了追求最小化loss,会取一个更平均的东西,但是这就会导致包含很少或根本没有细节。但对于网络来说是一个安全的预测,因为它训练的自然或地面实况补丁可以是这些可能性中的任何一种,并且产生任何其他有效可能性都会导致非常高的 MSE。
这个过程像下图展示的一样。
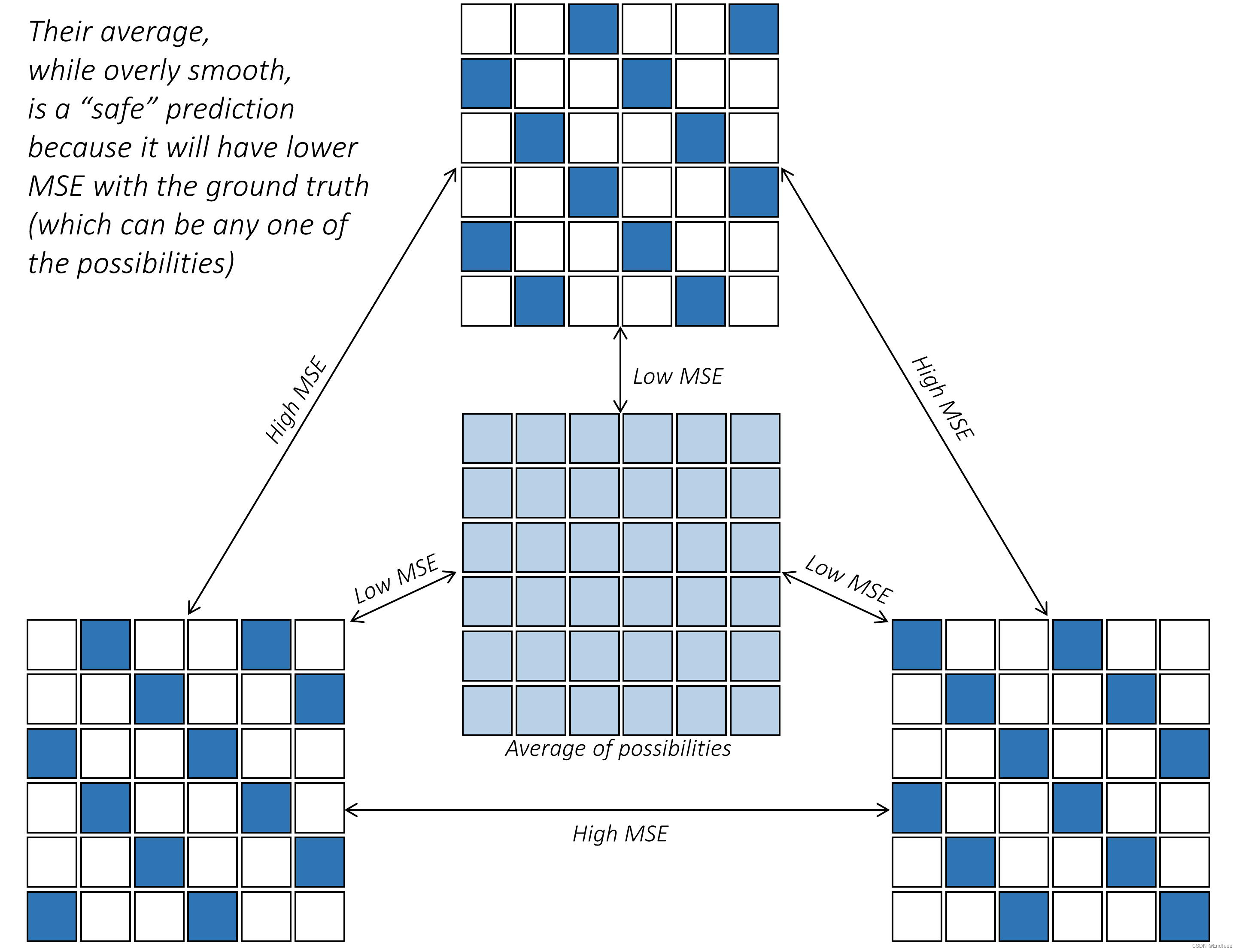
换句人话说就是:对于可能的几种结果,模型的策略是不冒险,不是3选1,而是学了一个这3个平均。
那么有没有一种方法可以不管图像中RGB像素的具体配置,而是直接提取其核心意义?有的,训练过的卷积神经网络(CNN)正是这样做的——它们能够生成描述图像本质的“更深层次”的特征。也就是说,在RGB空间中逻辑上相似的图像模式,通过训练过的CNN处理后,会得到类似的特征表示。
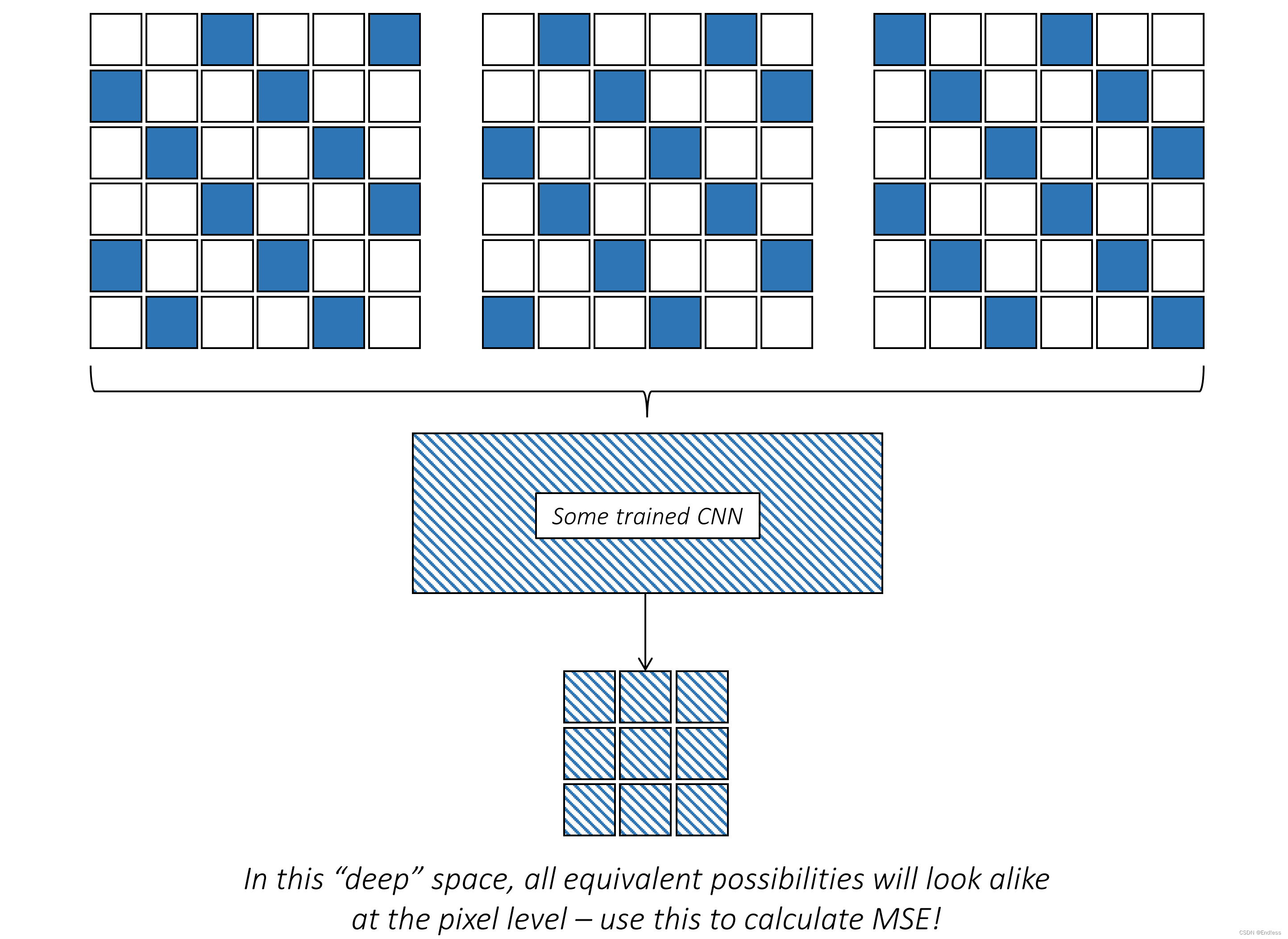
很显然,这种新的“深度”表示空间更适合计算内容损失!我们的超分辨率模型不再需要害怕创新——只要生成的结果在逻辑上合理,细节与RGB空间中的真实图像不完全一样也不会受到惩罚。(鼓励模型不再像原来那样教条,而是勇于冒风险生成一个确定的,也就是有更多细节的图片)
Part 1-生成器更新问题
在前向传递过程中,生成器会生成一个超分辨率图像,其尺寸是提供给它的低分辨率图像的 4 倍。
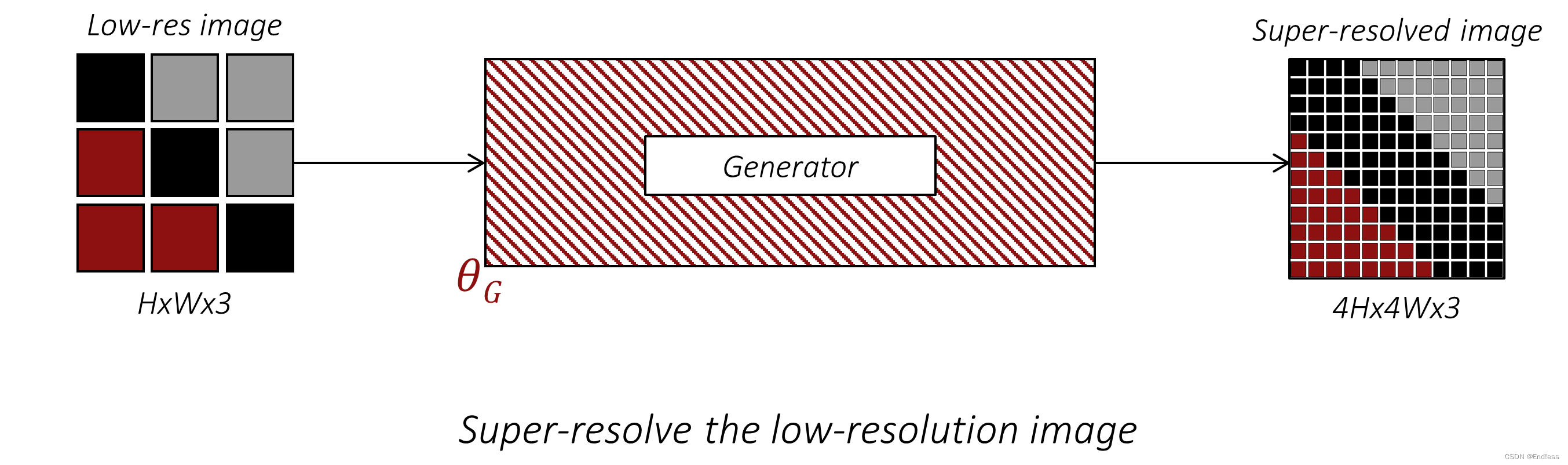
由于上一节所述的原因,我们不会使用RGB 空间中的 MSE 作为content loss,而是将两个都经过预训练的 CNN(具体来说是在 Imagenet 分类任务上预先训练过的VGG19 网络。该网络在第 5 个最大池化层之后的第 4 个卷积处被截断。)
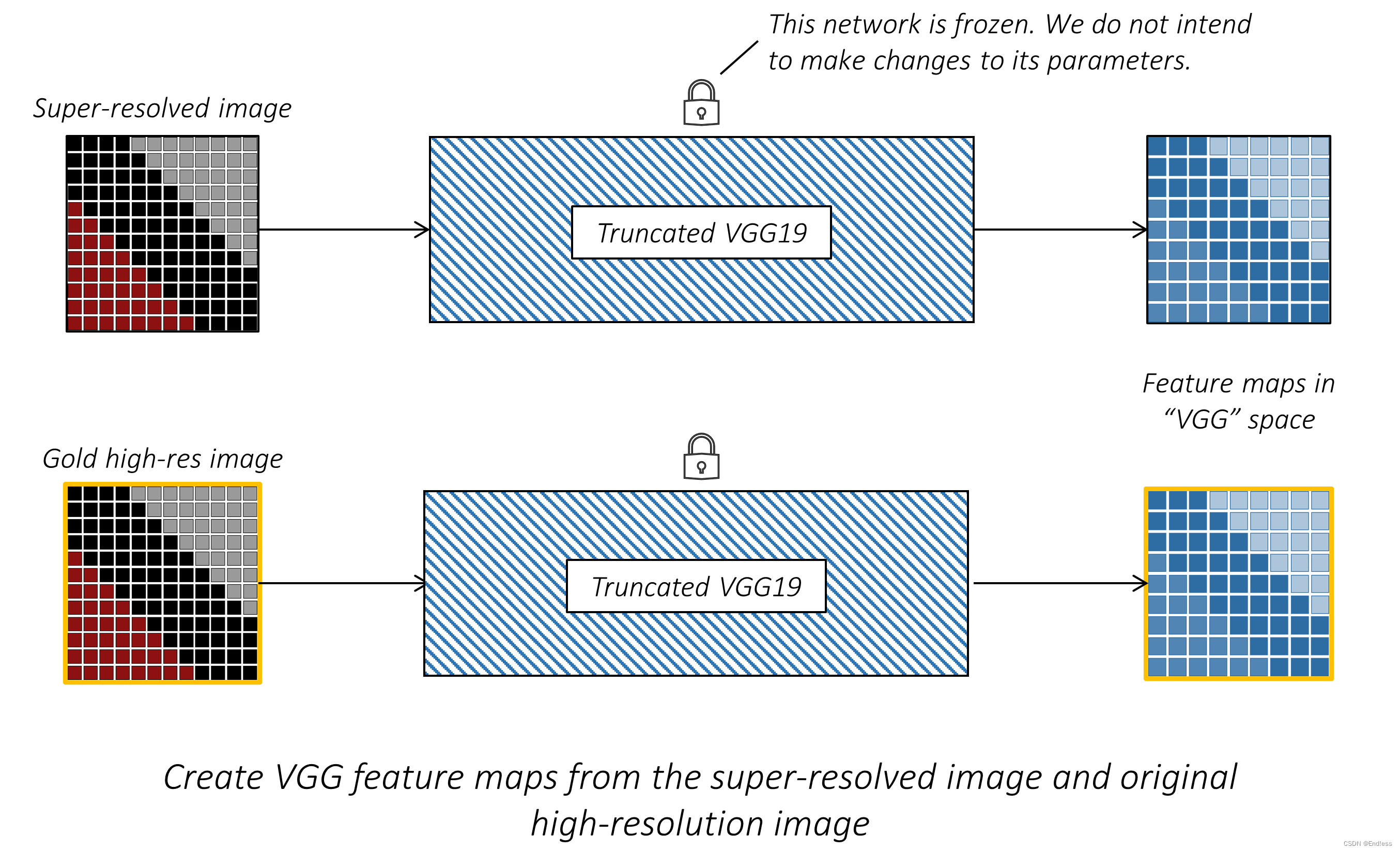
并且如上图中所示,是不会改变VGG19网络中的参数的。
也就是在 VGG 空间中使用基于 MSE 的内容损失来间接地将超分辨率图像与原始的黄金高分辨率图像进行比较。比较过程类似于下面的:
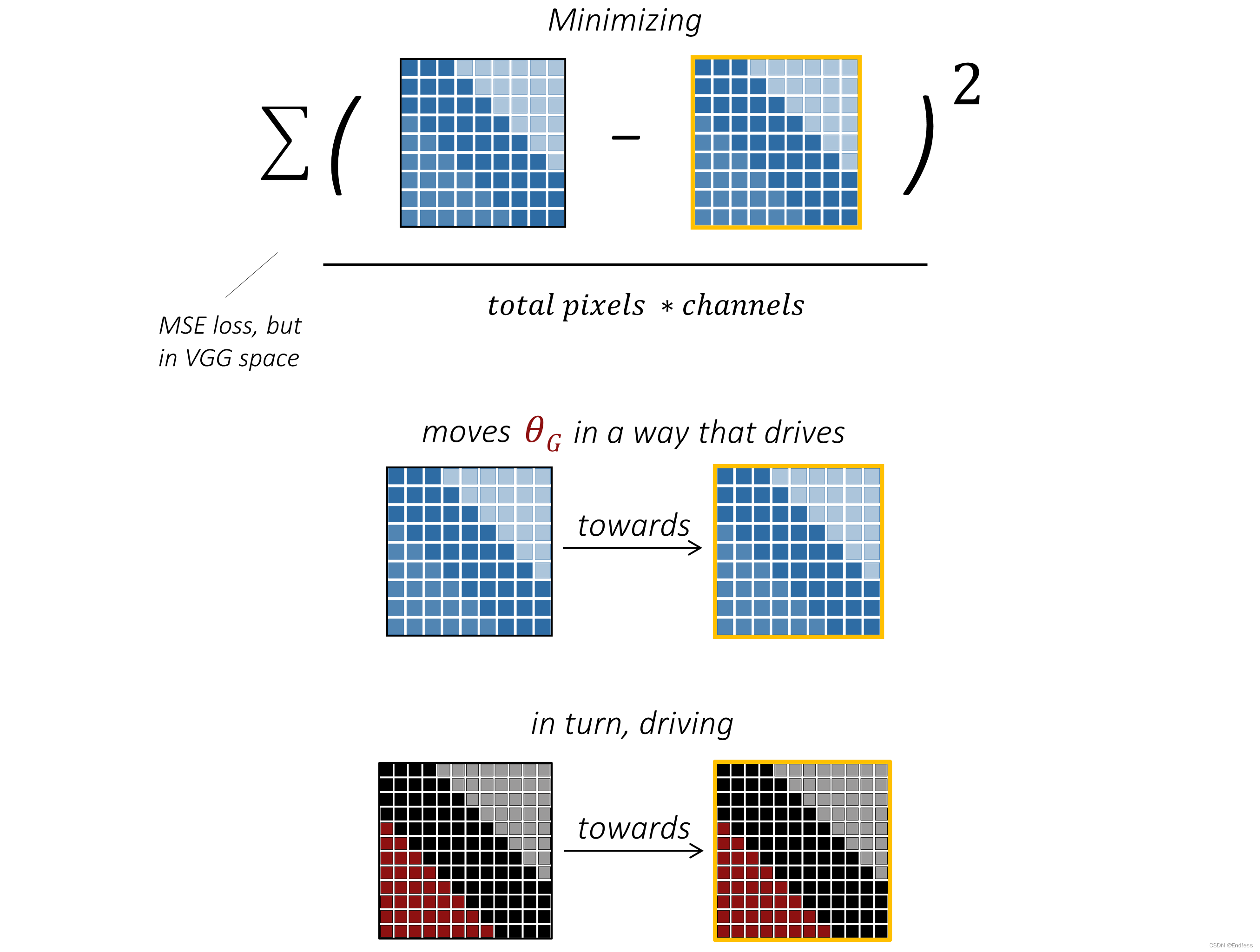
上图中所展示的过程很直观的说明,通过这个在VGG空间的MSE loss使得生成器尽可能生成一个和原图一样的图片(补充:过程是,将一个高分辨率图片变得模糊,在将这个模糊的图给generator,让他生成一个尽量跟原来高分辨率图片像的图片)
Part 2-GAN
现在我们来看如何让Generator变的更强,也就是如何让Generator产生的图片,在经过Discriminator后获得一个尽可能高的
P
H
R
P_{HR}
PHR,换言之,让Discriminator分辨不出来。过程类似于下图:
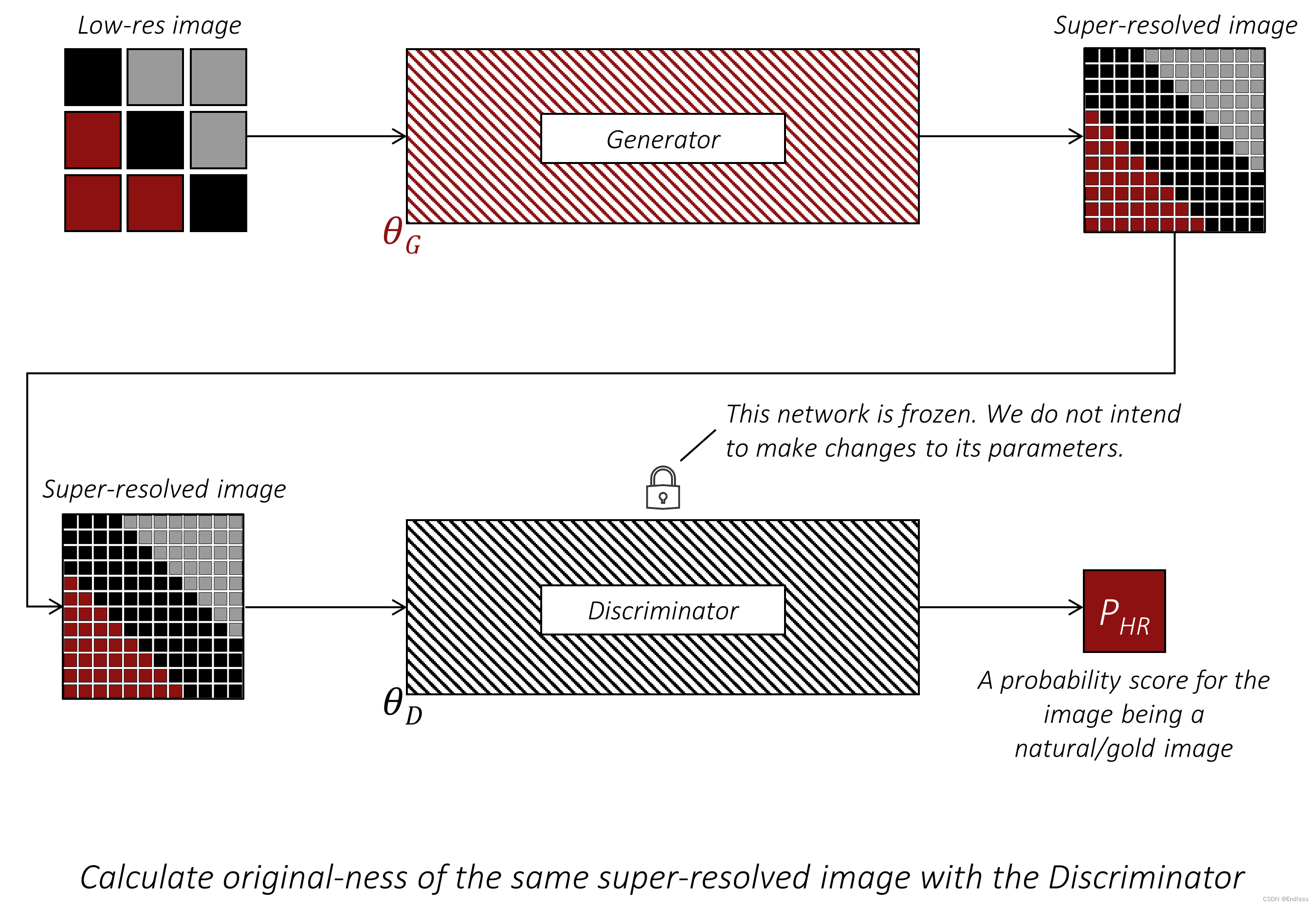
需要注意上图中的Discriminator的权重现在是锁住的,因为这步我们的目标是训练Generator。
理解完这张图后,再次重复一下Generator的目标:获得一个尽可能高的
P
H
R
P_{HR}
PHR。那么先尝试理解一下下面的完整版的损失函数:
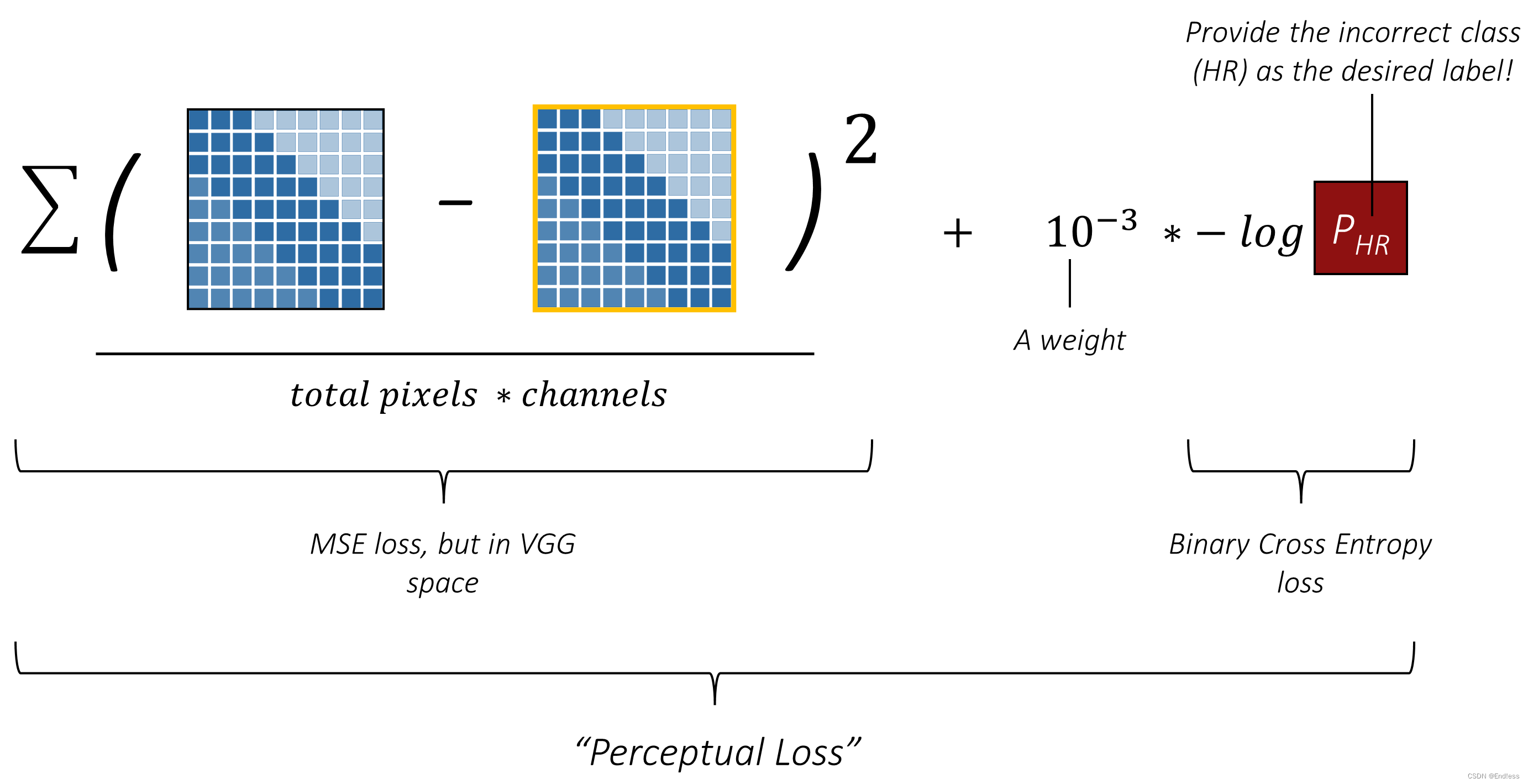
第一部分的在VGG空间中的MSE loss刚才已经说过;而第二部分是判别器判定生成的图片为自然图片的概率。先不管糅杂的数学表达,这个loss的含义就是:我希望生成器朝着“尽可能像原始图像的方向生成,并且同时要尽可能的让判别器认为生成的图片就是原图”。而这就是原始论文中提出的Perceptual Loss.
2.实现
2.1 先看结果:

结果还是比较明显的,右下角的Original HR是输入的原图;其中左上角Bicubic是对原图的模糊处理,作为SRResNet,SRGAN的输入,在这个例子中可以明显看出,SRGAN更勇于尝试——更有棱角,更锐利一点。而SRResNet稍微模糊一点,在这个例子中,因为汉字的细节较多,所以可能反而SRResNet的平均一点的效果对于我们来说更好一点,如果换一个图片STGAN就会明显更清晰一点,例如上面的地球,和下面这些列子:


可以发现效果还是很好的!!
那么下面就是一些代码的解释。
2.2 主要组件
- 卷积块(Convolutional Block)
卷积块由卷积层、批归一化层(可选)和激活层(可选)组成,用于特征提取和非线性变换。
class ConvolutionalBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, batch_norm=False, activation=None):
super(ConvolutionalBlock, self).__init__()
layers = [nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding=kernel_size // 2)]
if batch_norm:
layers.append(nn.BatchNorm2d(out_channels))
if activation == 'prelu':
layers.append(nn.PReLU())
elif activation == 'leakyrelu':
layers.append(nn.LeakyReLU(0.2))
elif activation == 'tanh':
layers.append(nn.Tanh())
self.conv_block = nn.Sequential(*layers)
def forward(self, input):
return self.conv_block(input)
- 子像素卷积块(SubPixel Convolutional Block)
子像素卷积块通过卷积层增加通道数,然后使用像素混洗(PixelShuffle)层进行上采样,最后通过PReLU激活层进行非线性变换。
class SubPixelConvolutionalBlock(nn.Module):
def __init__(self, kernel_size=3, n_channels=64, scaling_factor=2):
super(SubPixelConvolutionalBlock, self).__init__()
self.conv = nn.Conv2d(n_channels, n_channels * (scaling_factor ** 2), kernel_size, padding=kernel_size // 2)
self.pixel_shuffle = nn.PixelShuffle(upscale_factor=scaling_factor)
self.prelu = nn.PReLU()
def forward(self, input):
output = self.conv(input)
output = self.pixel_shuffle(output)
output = self.prelu(output)
return output
- 残差块(Residual Block)
残差块由两个卷积块组成,并在块的输入和输出之间添加了残差连接(skip connection),以缓解深层网络的梯度消失问题。
class ResidualBlock(nn.Module):
def __init__(self, kernel_size=3, n_channels=64):
super(ResidualBlock, self).__init__()
self.conv_block1 = ConvolutionalBlock(n_channels, n_channels, kernel_size, batch_norm=True, activation='prelu')
self.conv_block2 = ConvolutionalBlock(n_channels, n_channels, kernel_size, batch_norm=True, activation=None)
def forward(self, input):
residual = input
output = self.conv_block1(input)
output = self.conv_block2(output)
output += residual
return output
- SRResNet
SRResNet网络是生成器的基础结构,由一个初始卷积块、多个残差块、一个卷积块和多个子像素卷积块组成,最后通过一个卷积块输出超分辨率图像。
class SRResNet(nn.Module):
def __init__(self, large_kernel_size=9, small_kernel_size=3, n_channels=64, n_blocks=16, scaling_factor=4):
super(SRResNet, self).__init__()
self.conv_block1 = ConvolutionalBlock(3, n_channels, large_kernel_size, batch_norm=False, activation='prelu')
self.residual_blocks = nn.Sequential(*[ResidualBlock(small_kernel_size, n_channels) for _ in range(n_blocks)])
self.conv_block2 = ConvolutionalBlock(n_channels, n_channels, small_kernel_size, batch_norm=True, activation=None)
n_subpixel_convolution_blocks = int(math.log2(scaling_factor))
self.subpixel_convolutional_blocks = nn.Sequential(*[SubPixelConvolutionalBlock(small_kernel_size, n_channels, 2) for _ in range(n_subpixel_convolution_blocks)])
self.conv_block3 = ConvolutionalBlock(n_channels, 3, large_kernel_size, batch_norm=False, activation='tanh')
def forward(self, lr_imgs):
output = self.conv_block1(lr_imgs)
residual = output
output = self.residual_blocks(output)
output = self.conv_block2(output)
output += residual
output = self.subpixel_convolutional_blocks(output)
sr_imgs = self.conv_block3(output)
return sr_imgs
- 生成器(Generator)
生成器的架构与SRResNet相同,可以通过预训练的SRResNet模型进行初始化。
class Generator(nn.Module):
def __init__(self, large_kernel_size=9, small_kernel_size=3, n_channels=64, n_blocks=16, scaling_factor=4):
super(Generator, self).__init__()
self.net = SRResNet(large_kernel_size, small_kernel_size, n_channels, n_blocks, scaling_factor)
def initialize_with_srresnet(self, srresnet_checkpoint):
srresnet = torch.load(srresnet_checkpoint)['model']
self.net.load_state_dict(srresnet.state_dict())
print("\nLoaded weights from pre-trained SRResNet.\n")
def forward(self, lr_imgs):
return self.net(lr_imgs)
- 判别器(Discriminator)
判别器由多个卷积块和两个全连接层组成,用于判断输入图像是否为高分辨率图像。
class Discriminator(nn.Module):
def __init__(self, kernel_size=3, n_channels=64, n_blocks=8, fc_size=1024):
super(Discriminator, self).__init__()
in_channels = 3
conv_blocks = []
for i in range(n_blocks):
out_channels = (n_channels if i == 0 else in_channels * 2) if i % 2 == 0 else in_channels
conv_blocks.append(ConvolutionalBlock(in_channels, out_channels, kernel_size, stride=1 if i % 2 == 0 else 2, batch_norm=i != 0, activation='leakyrelu'))
in_channels = out_channels
self.conv_blocks = nn.Sequential(*conv_blocks)
self.adaptive_pool = nn.AdaptiveAvgPool2d((6, 6))
self.fc1 = nn.Linear(out_channels * 6 * 6, fc_size)
self.leaky_relu = nn.LeakyReLU(0.2)
self.fc2 = nn.Linear(fc_size, 1)
def forward(self, imgs):
batch_size = imgs.size(0)
output = self.conv_blocks(imgs)
output = self.adaptive_pool(output)
output = self.fc1(output.view(batch_size, -1))
output = self.leaky_relu(output)
logit = self.fc2(output)
return logit
- 截断的VGG19网络(Truncated VGG19)
截断的VGG19网络用于计算在VGG特征空间中的MSE损失。
class TruncatedVGG19(nn.Module):
def __init__(self, i, j):
super(TruncatedVGG19, self).__init__()
vgg19 = torchvision.models.vgg19(pretrained=True)
maxpool_counter = 0
conv_counter = 0
truncate_at = 0
for layer in vgg19.features.children():
truncate_at += 1
if isinstance(layer, nn.Conv2d):
conv_counter += 1
if isinstance(layer, nn.MaxPool2d):
maxpool_counter += 1
conv_counter = 0
if maxpool_counter == i - 1 and conv_counter == j:
break
assert maxpool_counter == i - 1 and conv_counter == j, "Invalid i and j values for VGG19!"
self.truncated_vgg19 = nn.Sequential(*list(vgg19.features.children())[:truncate_at + 1])
def forward(self, input):
return self.truncated_vgg19(input)


















 1415
1415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











