








在本文中,我们将研究如何针对疾病症状训练一个小型医疗保健语言模型。为此,我们将从HuggingFace获取数据集(用于训练我们的模型):https://huggingface.co/datasets/QuyenAnhDE/Diseases_Symptoms
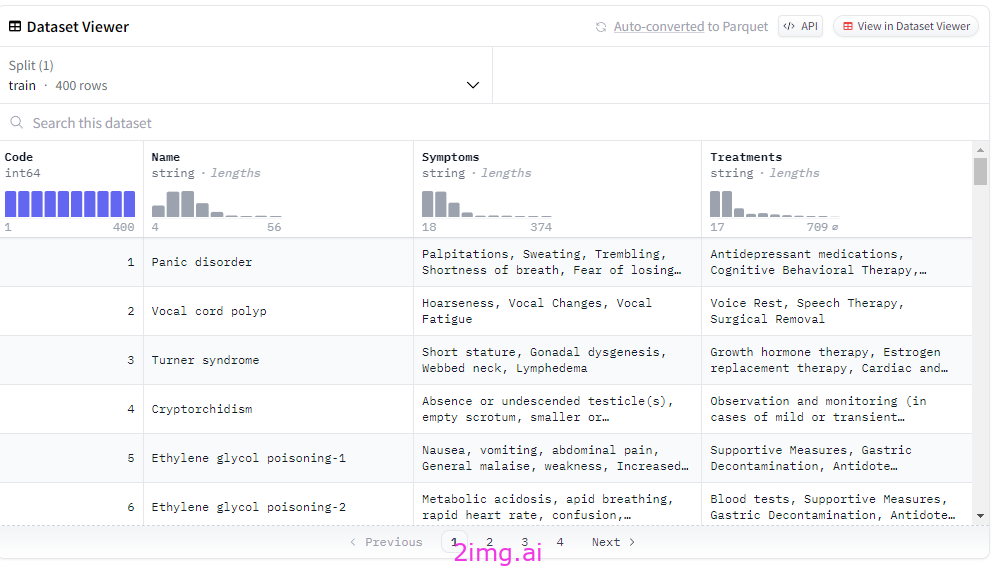
QuyenAnhDE/Diseases_Symptoms 数据集来自 Hugging Face。图片来源:Walid Soula
对于模型,我们将使用 GPT2:https://huggingface.co/distilbert/distilgpt2
DistilGPT2 是一个英语模型,在 1.24 亿个参数版本的 GPT-2 的监督下进行了预训练。DistilGPT2 拥有 8200 万个参数,是使用知识蒸馏开发的,旨在成为 GPT-2 的更快、更轻量级版本。
DistilGPT2 使用 OpenWebTextCorpus 进行训练,OpenWebTextCorpus 是 OpenAI 的 WebText 数据集的开源复制品,用于训练 GPT-2。
在开始之前,我们先来了解一下什么是小型语言模型?
小型语言模型是大型语言模型的缩小版,通常设计为具有更少的参数和更小的内存占用,同时仍保留生成连贯文本的能力。
这些较小的模型通常用于计算资源有限(尤其是在边缘设备)或实时性能至关重要的应用中。
我认为小语言模型 (SLM) 将在医疗保健领域发挥重要作用,指导患者,获得专家或特定医疗机构的问答,同时增强医疗保健边缘设备的功能,如血糖仪、张力计等,特别是在智能手表上可访问的移动应用程序的开发,也促进治疗监测和最佳患者护理!
开始吧
依赖项和库
第一步包括安装运行 SML 微调所需的依赖项
!pip install torch torchtext transformers sentencepiece pandas tqdm datasets from datasets import load_dataset, DatasetDict, Dataset import pandas as pd import ast import datasets from tqdm import tqdm import time
首先,我从datasets模块引入了load_dataset、DatasetDict和Dataset等函数和类,以便加载和使用数据集。此外,我还加入了pandas,这对于数据操作来说是必不可少的。
最后,ast模块帮助解析 P
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5672
5672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











