







当大多数人都还在卷谁的大模型参数规模大的时候,聪明人已经开始搞“小模型”了(doge)。
这里的小模型指的小型语言模型(Small Language Model,简称SLM),通常用于解决资源受限或实时性要求较高的场景,比如一些边缘设备(智能手机、物联网设备和嵌入式系统等),大模型难以运行其上。
目前我们对大模型的探索已经到了瓶颈,因高能耗、巨大的内存需求和昂贵的计算成本,我们的技术创新工作受到了挑战与限制。而对比大模型,小模型耗资少、响应快、可移植性强、泛化能力高...在一些特定情况下,可以提供更高效、更灵活的选择。因此,更多人开始着眼于小巧且兼具高性能的小模型相关的研究。
我今天就帮同学们整理了目前效果不错的高性能小模型,以及一些优秀的小模型性能优化方案和应用成果,包括研究者们在大模型与小模型结合方面做出的尝试。原文共16篇。
这些模型与方案的配套论文和项目代码我全都打包完毕,需要的同学看看文末
高性能小模型
TinyLlama-1.1B
论文:TinyLlama: An Open-Source Small Language Model
一个开源的小型语言模型
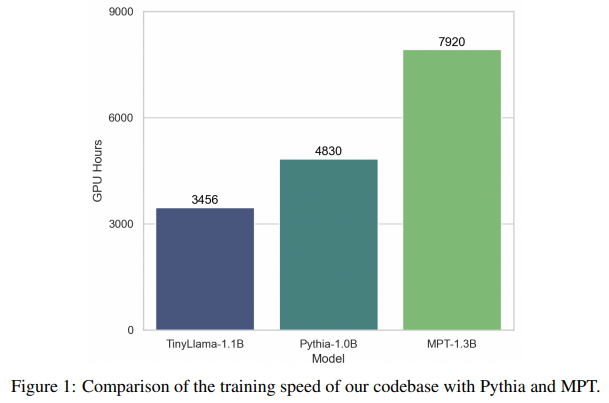
「模型简介:」本文介绍了TinyLlama小型语言模型,该模型在大约1万亿个标记上进行了约3个周期的预训练,具有紧凑的1.1B参数规模。TinyLlama基于Llama 2(Touvron等人,2023b)的架构和分词器构建,利用了开源社区贡献的各种先进技术(例如FlashAttention(Dao,2023)),实现了更好的计算效率。尽管其规模相对较小,但TinyLlama在一系列下游任务中表现出色,显著优于现有规模相当的开源语言模型。
LiteLlama
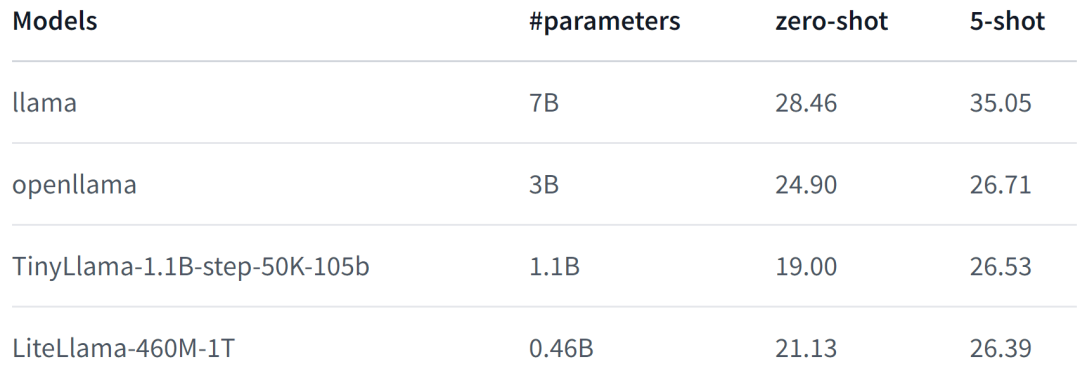
「模型简介:」SLM-LiteLlama是对 Meta AI 的 LLaMa 2 的开源复刻版本,但模型规模显著缩小。它有 460M 参数,由 1T token 进行训练。LiteLlama-460M-1T 在RedPajama数据集上进行训练,并使用 GPT2Tokenizer 对文本进行 token 化。作者在 MMLU 任务上对该模型进行评估,结果证明,在参数量大幅减少的情况下,LiteLlama-460M-1T 仍能取得与其他模型相媲美或更好的成绩。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1907
1907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









