









毫不怀疑,在过去的几十年里,没有什么比人工智能更能引起轰动。仔细观察后,我发现很多都只是噪音,只有少数几个很好的突破被大多数人完全忽略了。人工智能炒作周期并不是一个新现象,甚至不仅限于人工智能。我们在很多新兴技术中都看到过这种现象。
随着 ChatGPT 的发布,一切都发生了重大变化,人工智能成为每个企业的讨论焦点。但喧嚣并不总是一件好事,很多重要的事情在这种炒作中被忽略了。所以,今天,我们将研究人工智能在技术和商业方面的情况。在本文中,我们主要关注生成式人工智能,因为这是过去一年左右最受炒作的东西。
巨大的鸿沟
关于 LLM 主要有三类观点,让我们仔细看看。
立场一(怀疑论)
一些科学家,比如乔姆斯基LLM是一种非常先进的统计工具,根本不等同于智能。他们的观点是,这些机器已经看过太多数据,它们可以回答我们可能提出的任何问题。从数学上讲,它们已经为我们可能提出的每个问题计算了条件概率。
我的观点:这里的缺陷可能是低估了数据建模模仿认知某些方面(尽管不是真正的理解)的细微差别。我们怎么知道人类没有做同样的事情呢?我们不断从不同的感官中获取数据。因此,区分理解和模仿理解可能还需要开发其他类型的智能。
本文阐明了 LLM 行为的很大一部分可以通过 N-gram 统计规则来解释:通过 N-gram 统计理解 Transformers
立场 II (充满希望的洞察)
Ilya Sutskever(ChatGPT 的创建者)和 Hinton 似乎认为 LLM 已经开发出了反映人类经验的内部模型。他们的立场是,由于互联网上的文本是人类思想和经验的代表,并且通过训练来预测这些数据中的下一个标记,这些模型在某种程度上建立了对人类世界和经验的理解。它们已经变得真正智能,或者至少看起来是智能的,并且已经像人类一样创建了世界模型。
我的观点:这可能夸大了LLM的深度,误将复杂的数据处理当成真正的理解,并忽视了这些模型中缺乏有意识的体验或自我意识。此外,如果他们已经建立了这些内部世界模型,那么为什么他们会在一些应该与这些内部世界模型一致的相当简单的任务上惨败呢?
立场三(实用主义)
许多科学家,比如 LeCun 和 Kambhampati, 认为 LLM 是强大的辅助工具,但并不具备人类智能,甚至在经验或内部世界模型方面,也并不接近人类智能。虽然 LLM 的记忆和检索能力令人印象深刻,但在真正的推理和理解方面却有所欠缺。他们认为,LLM 不应被拟人化或被误认为具有人类智能。它们作为“认知矫正器”表现出色,有助于完成写作等任务,但缺乏类似于人类系统 2思维的更深层次的推理过程。
注意:我们认为当前的 LLM 是系统 1 智能,这就是为什么每个问题都需要几乎相同的时间来解决,无论是线性、二次还是指数。
LLM 类似于人类系统 1(反射行为),但缺少系统 2(深思熟虑的推理)部分。它们不具备从第一原理进行深入、深思熟虑的推理和解决问题的能力。
他们认为,未来人工智能的发展将依赖于完全不同的原则,而通用人工智能的出现不能仅仅通过规模化来实现。勒昆甚至还说:“不要去读LLM。”
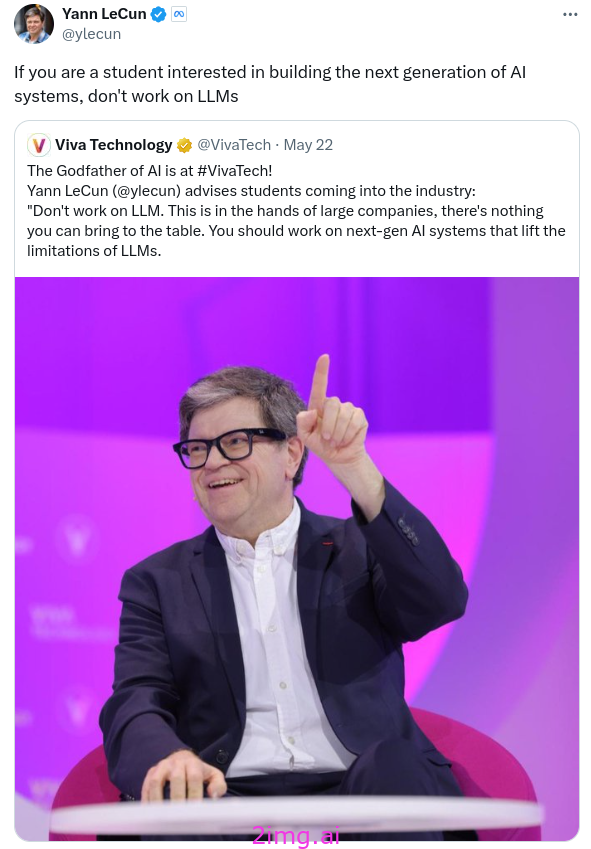
LeCun 反对攻读LLM学位
我的观点:LLM (LLM) 的所有发展中的一些组成部分肯定会成为下一代系统的一部分。我不知道未来系统究竟会包含哪些内容,但过去进步的一些残余肯定会成为其中的一部分。
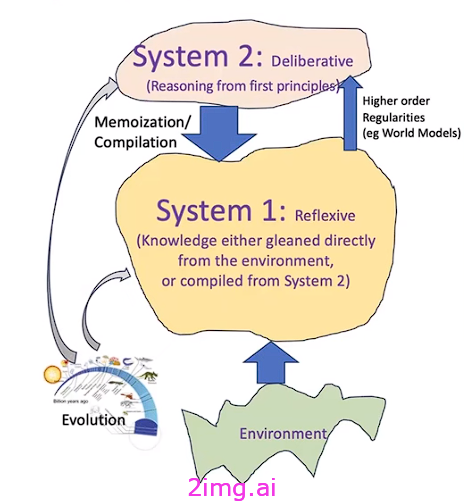
系统 2 (图片来源)
推断趋势是毫无根据的猜测
每个指数都是一个伪装的 S 形函数。
这句话概括了整个领域。人工智能与其他领域并无不同。我们可以肯定,没有任何指数趋势可以无限期地持续下去。但很难预测技术趋势何时会停滞。当增长突然停止而不是逐渐停止时尤其如此。趋势线本身并不包含即将停滞的线索。
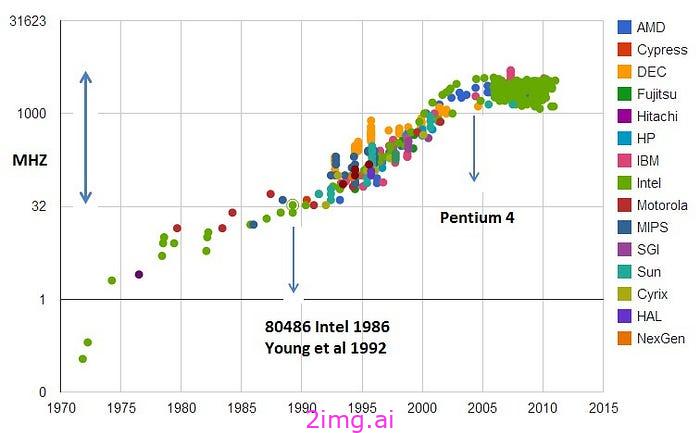
CPU 时钟速度随时间的变化。y 轴为对数。[来源]
两个著名的例子是 2000 年代的 CPU 时钟速度和 1970 年代的飞机速度。CPU 制造商认为进一步提高时钟速度成本太高,而且几乎没有意义(因为 CPU 不再是整体性能的瓶颈),因此干脆决定停止在这个维度上的竞争,这突然消除了时钟速度的上升压力。对于飞机来说,情况更为复杂,但归根结底是市场优先考虑燃油 效率而不是速度。
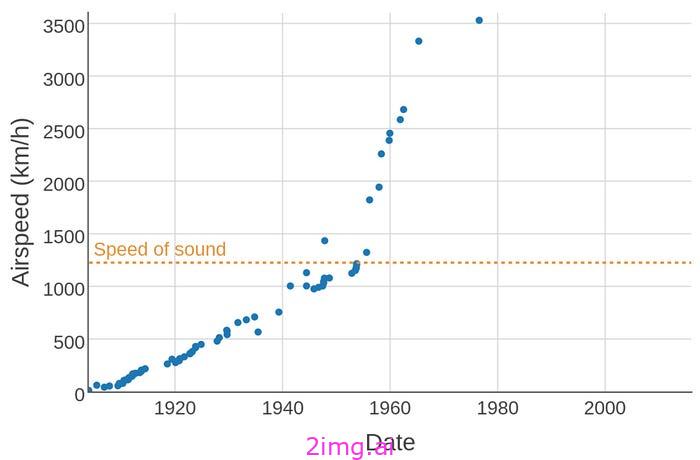
飞行速度随时间变化的记录。1976 年 SR-71 黑鸟的记录至今仍未改变。[来源]
合成数据通常被认为是继续扩展的途径。换句话说,也许当前的模型可以用来为下一代模型生成训练数据。
但我们认为这是基于一种误解——我们认为开发人员不会使用(或可以使用)合成数据来增加训练数据量。本文列出了合成数据用于训练的大量用途,这些用途都是为了弥补特定缺陷,并针对数学、代码或低资源语言等特定领域进行改进。同样,Nvidia 最近的Nemotron 340B模型也适用于合成数据生成,其主要用例是对齐。还有一些次要用例,但替换当前的预训练数据源并不是其中之一。简而言之,盲目生成合成训练数据不太可能产生与拥有更多高质量人工数据相同的效果。
合成训练数据曾取得过巨大成功,比如2016 年击败围棋世界冠军的AlphaGo ,以及它的继任者 AlphaGo Zero 和AlphaZero。这些系统通过与自己对弈来学习;后两者没有使用任何人类游戏作为训练数据。他们使用大量计算来生成质量略高的游戏,并使用这些游戏来训练神经网络,然后结合计算,神经网络可以生成质量更高的游戏,从而形成一个迭代改进循环。但并不是每个问题都是如此。
我们不知道当前的系统到底有多好或多坏?
不控制成本的 AI 代理准确度测量是无用的。
当前最先进的代理架构既复杂又昂贵,但并不比在某些情况下成本低 50 倍的极其简单的基线代理更准确。
如果我们的目标是找出最适合特定任务的系统,那么参数数量等成本指标就容易产生误导。我们应该直接衡量美元成本。
LLM 是随机的。只需多次 调用模型并输出最常见的答案即可提高准确率。
在某些任务上,可以提高准确性的推理计算量似乎是没有限制的。3 Google Deepmind 的AlphaCode提高了自动编码评估的准确性,它表明,即使调用 LLM 数百万次,这种趋势仍然成立。
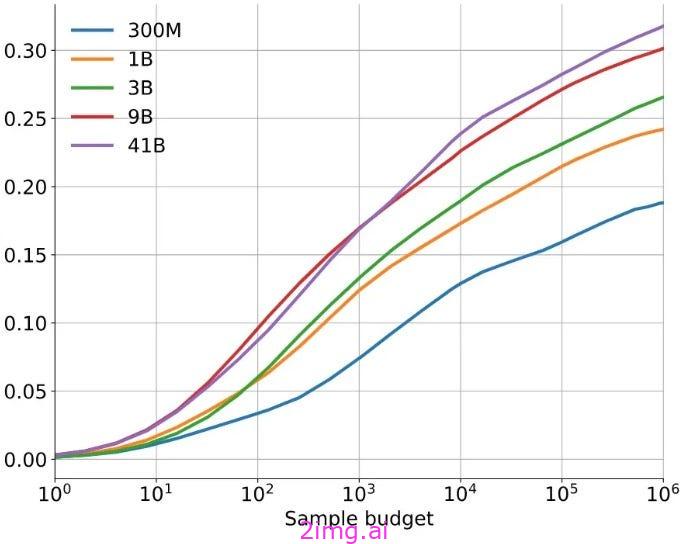
即使对底层模型进行了一百万次调用, AlphaCode在编码任务上的准确率仍会持续提高(不同的曲线代表不同的参数数量)。准确率是通过模型生成的前 10 个答案中有一个正确的频率来衡量的。
因此,对药物进行有用的评估必须问:它的成本是多少?如果我们不进行成本控制比较,就会鼓励研究人员开发极其昂贵的药物,只是为了声称它们位居排行榜首位。
事实上,当研究人员评估去年提出的用于解决编码任务的代理时,他们发现可视化成本和准确性之间的权衡可以产生令人惊讶的见解。
最引人注目的结果是,尽管成本更高,但 HumanEval 的代理架构并没有超越我们更简单的基线。事实上,代理在成本方面差异很大:对于基本相似的准确度,成本可能相差近两个数量级!然而,运行这些代理的成本并不是这些论文中报告的首要指标。
许多数据污染论文已经存在。https ://arxiv.org/pdf/2405.00332
根本问题是其他问题,我们没有科学理论

人工智能的早期创始人认为,一旦解决了这 5 个问题,我们就能解决智能问题。所有这些问题都基本解决了,但我们的系统仍然会犯一些基本错误。
请不要误会我的意思,目前的系统在它们能做的事情上已经很出色了。我每天都对神经网络的工作原理感到敬畏,它们本来不应该这么好用。甚至 Illya Sutskever 也说过同样的话。一堆矩阵乘法就能完成所有这些令人惊叹的事情。
但现在我们意识到,智能的根本问题并非这五点所能解决的。如果数据和计算是智能的唯一必需品,那么我们早在 2010 年代初就解决了智能问题。
问题是我们只是在建立一个类似的系统,而对于什么将带来实际进展,我们并没有理论上的理解。只有少数几篇论文真正讨论了LLM的性质和内部运作。其中一篇论文是:
我们严重缺乏一种理论来理解这些系统,因此大多数关于大语言模型 (LLM) 的研究论文对于实际推动该领域的发展几乎毫无用处。
我认为,如果不了解这些系统的固有机制,我们就无法制造出真正智能的系统。
我们想知道为什么深度学习如此有效,以及它的数学基础是什么。那么我们一定要研究对称性。
我相信,一个能够发现新类型对称性、结合神经符号方法、通过形式验证和其他机制正确整合信息、并使用某种形式的世界模型(如 JEPA)进行预测的系统将真正接近我们称之为 AGI 的机器。
我认为没有任何一种算法可以做到所有这些,但是配备不同类型的工具和流程以在不同类型的场景中运行的智能设计的机器或算法将把我们带到更高的智能水平。
财务问题
人工智能最大的问题是财务,很多人不了解制造这些系统和利用这些技术制造产品的经济学。
许多公司公开宣称他们的目标是实现 AGI。你还记得 Sam Altman 的荒谬言论吗?他想筹集 7 万亿美元来打造 AGI。但现在如果你看看他们的使命,就会发现它略有改变。没有一个系统是凭空而来的,如果没有合适的用例,我们就不能仅仅投入资金来希望打造出能够改变人类的东西。
让我们再分析一下财务方面,想象一下,在给我们亲爱的 Sam Altman 7 万亿美元之后,我们就有了一个 AGI。根据定义,它将能够完成大多数人类所做的各种任务。现在,如果部署了这样一个系统,人类会做什么呢?他们将没有任何东西可以买卖。假设你使用这个 AGI 制造出最好的产品,没有人有钱购买这些产品,如果没有人有钱购买,这些系统将无法生存。即使是这些系统也需要大量资源。
我知道你们中的一些人可能会对全民基本收入 (UBI) 提出质疑,但即使要做到这一点,我们也需要出售服务和产品,如果没有人有工作,他们如何纳税并为 UBI 创造足够的资金?如果 AGI 大规模部署,大多数人将失去工作,从而导致整个国家的金融周期崩溃。
除非机器人成为有欲望的消费者,否则全球经济体系将会崩溃。
忘掉假设的 AGI 用例吧,即使是现在,公司也在以 AI 的名义出售一切。最近,我开玩笑说,告诉我什么不是以 AI 的名义出售的。

一半的初创公司只是 OpenAI API 的包装器,它们没有业务,只是在烧风险投资的钱,而这种变化趋势已经显现出来。
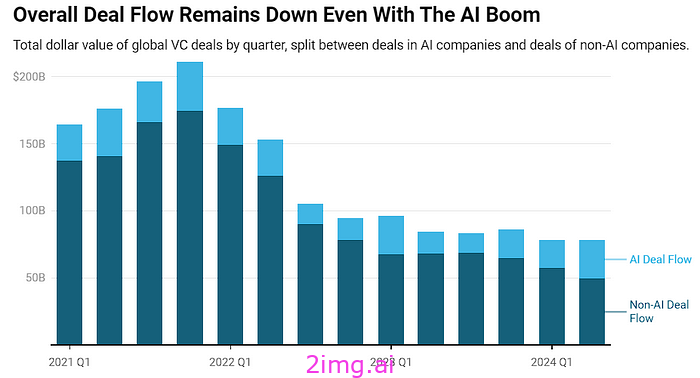
人工智能的魔力正在慢慢消退
我相信您可以展示不同的图表,其中人工智能似乎正在增长,但绝不是呈指数级增长。
什么可能导致人工智能泡沫破裂?
有几个因素可能导致人工智能泡沫破裂,其中包括:
-
估值不可持续。估值过高的人工智能公司可能没有足够的盈利或增长潜力来证明其高估值的合理性。
-
缺乏盈利收入来源。许多人工智能公司未能从其人工智能投资中获得显著的收入增长。如果没有明确的货币化战略,持续的巨额支出可能会变得难以为继。
-
监管挑战。与人工智能安全、道德和数据隐私相关的审查和监管力度不断加强,可能会减缓人工智能发展的势头并影响公司估值。
-
经济衰退。更广泛的经济衰退可能导致对人工智能的投资减少,从而进一步加剧股价下跌。
我绝不是说公司不会从人工智能中赚钱,但能赚钱的公司将寥寥无几。像 NVIDIA 和其他正在开发核心技术的关键公司将获得巨额利润,其余公司将在几年内消亡。除非你真正用人工智能解决问题,否则你不会赚钱。目前,许多公司处于这样的状态:他们有技术,但没有问题。要建立一个成功的企业,就应该采用另一种方式。并非每家企业都会创造类别。
还有一点要记住,每项技术也受到其适应性的限制。人们能够多快掌握它并用它来创造新产品和服务。

https://www.forbes.com/sites/bryanrobinson/2024/07/23/employees-report-ai-increased-workload/
最近,Upwork 研究所采访了 2,500 名全球高管、全职员工和自由职业者。结果表明,对人工智能影响的乐观预期与许多员工面临的现实不符。研究发现,管理者的高期望与员工使用人工智能的实际体验之间存在脱节。
尽管 96% 的高管希望 AI 能够提高生产力,但研究显示,77% 使用 AI 的员工表示,这增加了他们的工作量,并给实现预期的生产力增长带来了挑战。AI 不仅增加了全职员工的工作量,而且还妨碍了生产力并导致员工倦怠。
更糟糕的是,近一半(47%)使用人工智能的员工表示,他们不知道如何实现雇主期望的生产力增长,40% 的人认为公司在人工智能方面对他们要求过高。员工们感受到了生产力需求不断上升带来的压力,三分之一的全职员工表示,他们可能会在未来六个月内辞职,原因是工作过度和精疲力竭。
现在我不知道这项研究有多准确,或者它是否足够大到可以得出具体的统计数据,但我想传达的是,技术的能力受到大众使用范围的限制。我们在数学方面取得了重大进展,但这并不意味着更多的人掌握了数学知识。每一项技术都会受到其用户的限制。
人工智能领域的下一步是什么?
一个迹象表明,我们可能不会通过扩展看到更多的能力提升,那就是首席执行官们一直在大大压低AGI 的预期。不幸的是,他们非但没有承认自己天真的“3 年内实现 AGI”预测是错误的,反而决定通过淡化 AGI 的含义来挽回面子,以至于现在 AGI 已经毫无意义。AGI从一开始就没有明确的定义,这很有帮助。
我们可以将通用性视为一个频谱,而不是二元对立。从历史上看,让计算机编写新任务所需的工作量已经减少。我们可以将此视为通用性的增加。这一趋势始于从专用计算机转向图灵机。从这个意义上说,大语言模型的通用性并不是新鲜事物。
因此,人工智能领域可能出现的下一个阶段是人们对人工智能及其相关产品和服务的兴趣逐渐淡化。许多进入该领域以赚快钱的人很快就会发现自己处于非常糟糕的境地。他们中的许多人将再次转向其他领域。只有少数真正对该领域感兴趣的人会留下来构建可控的人工智能系统,他们将开发一种针对特定问题且可解释的新型系统。我个人希望看到我们不仅可以理解和预测其行为,还可以控制的系统。
我真心希望我们在算法理解这些系统方面取得更多进展。当前的系统太脆弱了,我们根本不知道它们什么时候才足够可靠。
我再次提出一些在这些努力中取得重大进展的有趣的论文。
对于很多应用来说,信任是一个重要因素,除非机器能够正确解释其决定,否则其使用将受到限制。除了信任之外,还有很多问题。当机器做出意外行为时,你会怎么做?如何控制它?如果发生机器事故,谁应该负责?这些问题并不容易回答。
老实说,我们不需要通用人工智能,我们需要的是人类增强智能,它能让我们更有效率,让我们更多地反思生活,让我们感觉与世界更加紧密相连而不是脱节。
人工智能产品和服务的无意义扩散所造成的问题比其旨在解决的问题还要多。
我只想用两个例子来结束这篇博客,人工智能朋友和女朋友。这是人工智能最无用的用例。它永远不应该被正常化,只应该在极端心理健康问题的情况下才推荐使用。这种不受监管的空间将创造出一种精神上更加痛苦和脱节的品种,这将需要其他人工智能解决方案,要求他们再次回归人类和自然。
第二个是教育领域的人工智能,尽管有那么多人工智能工具,人们并没有变得更聪明,相反,他们的注意力持续时间变得更短,花在学习上的时间更少,他们的思想被分散了。现在,我知道只有少数人可以极其有效地使用这些工具。但对于大多数人来说,额外节省的时间并没有花在做更有成效的事情上,而是浪费在做更多无用的事情和娱乐上。人工智能工具节省的时间和精力主要用于分散注意力。所以,总而言之,实际上什么都没有改变。自从GPT发布以来,大多数人并没有成为优秀的作家或小说家,事实恰恰相反,人们甚至失去了语言和写作的基本知识。


















 80
80

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}