









RAG Foundry 是英特尔的一个开源框架。旨在简化检索增强生成 (RAG) 系统的实施和评估。它通过将数据创建、模型训练、推理和评估集成到单个工作流程中来简化流程。该框架已被证明可有效微调 LLM(如 Llama-3 和 Phi-3),通过提高各种知识密集型数据集的性能。

考虑到当前的语言模型状况,市场上已经开始形成几种产品和架构原则:
- 用于本地托管和推理的开源小型语言模型 ( SLM )。开源语言模型的可用性为针对高度细分的任务微调语言模型铺平了道路;例如 RAG 特定实现。
- 编排多个模型以构成解决方案。
- AI 代理/代理应用程序已成为主流,其工具也专注于快速创建可供 AI 代理使用的工具。
- AI 代理开始利用多模态语言模型/基础模型来解释和导航 GUI,包括手机、PC、浏览器等。
- 管道是通过无代码流程构建器工具创建的,这些工具通过 API 公开以充当代理工具。
- 语言模型微调是使用模拟模型需要表现出的行为的数据进行的。这些包括任务分解和推理与训练模型,以更好地适合代理使用。
- 由于微调的特定要求,对合成数据的研究和使用正在增加。为了创建高度精细的定制训练数据,语言模型用于生成数据。
- 目前正在开发各种方法来创建多样化、非重复性和有价值的合成训练数据。
- 为AI 代理特定微调创建数据包括将其纳入数据环境和规划任务,在这些规划任务上合成专家级分解和任务轨迹(动作-观察对序列)。并使用合成的轨迹数据对 LLM 进行指令调整。
- RAG功能不断发展,包括Agentic RAG、质量基准测试后生成等。图形数据方法以及本文中所示的 RAG 特定模型微调。
RAG 铸造厂
什么是 RAG Foundry?
RAG Foundry 是英特尔的一个开源框架,旨在增强检索增强生成 (RAG) 用例的大型语言模型。
RAG Foundry 将数据创建、训练、推理和评估集成到统一的工作流程中,从而简化了整个流程。
这有助于通过数据增强过程开发数据集,从而能够在 RAG 环境中更有效地训练和评估大型语言模型。
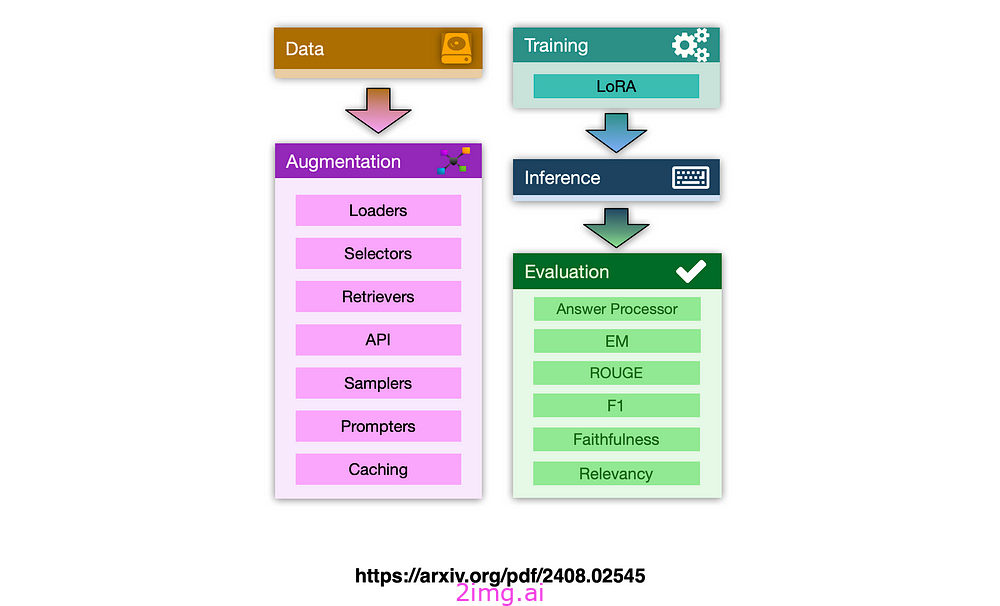
RAG Foundry 框架概述:数据增强模块将 RAG 交互存储在专用数据集中,然后用于训练、推理和评估。
为什么选择 RAG Foundry?
这种集成有助于快速进行原型设计和各种RAG 技术的实验。
使用户能够使用内部或专业知识源有效地生成数据集并训练 RAG 模型。
该框架的有效性通过使用不同的 RAG 配置增强和微调 Llama-3 和 Phi-3 模型来证明,从而实现三个知识密集型数据集的持续改进。
以下是用于插入相关文档作为上下文的模板……
Question: {query}
Context: {docs}
Answer this question using the information given in the context above. Here is things to pay attention to:
- First provide step-by-step reasoning on how to answer the question.
- In the reasoning, if you need to copy paste some sentences from the context, include them in
##begin_quote## and ##end_quote##. This would mean that things outside of ##begin_quote## and
##end_quote## are not directly copy paste from the context.
- End your response with final answer in the form <ANSWER>: $answer, the answer should be succinct.Ragas
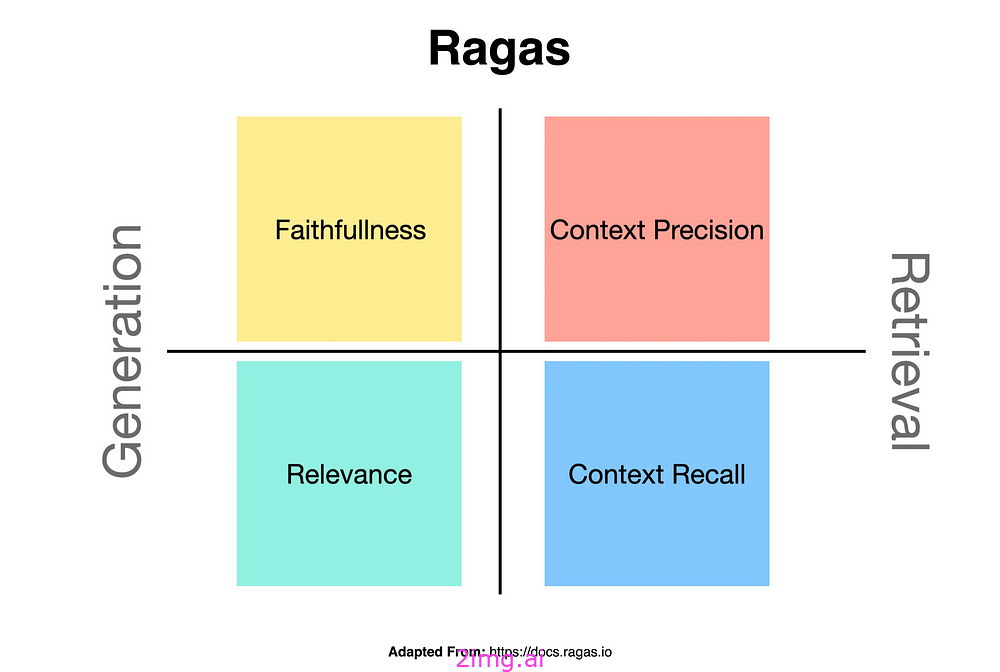
该团队评估了精确匹配(EM)、准确度和 F1 分数。
此外,他们还评估了两个 RAGAS 指标:忠诚度(衡量生成的文本与上下文之间的一致性)和相关性(评估生成的文本与查询的匹配程度)。
相关性评估需要嵌入器。
综上所述
正如我之前提到的,观察新技术如何发展以及建筑商如何遵循相同的原则来实施技术是很有趣的。
英特尔开发了具有多种 RAG 配置的微调模型,这是数据设计的最新趋势的一部分。数据以精细的方式设计,以紧密模拟模型的预期任务。
这一发展不仅注重改进 RAG 实施和微调模型,而且还通过全面的评估过程闭合反馈回路。
















 34
34

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











