









目录
[2015][ICCV] Ask Your Neurons A Neural-Based Approach to Answering Questions About Images
文章链接
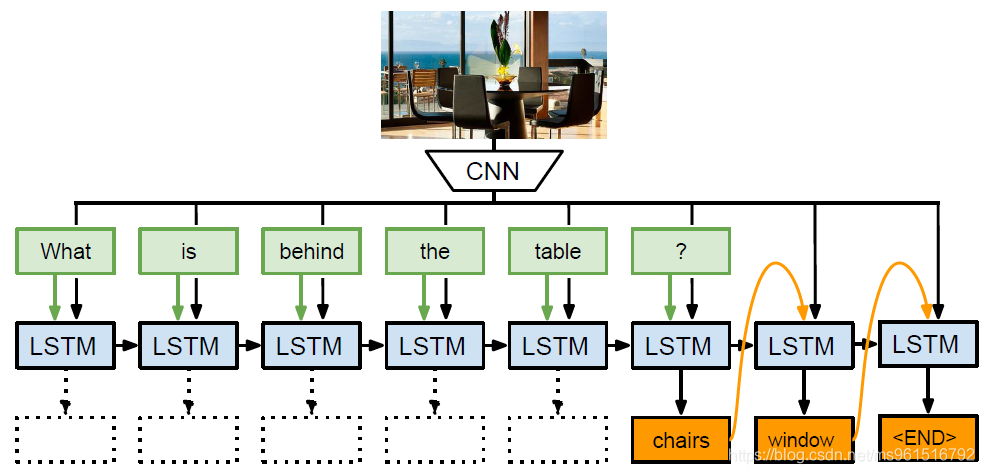
本文和NIPS2014那篇文章一样,出自马普所的Malinowski。2014那篇是依据语义解析器进行视觉问答,本文使用的是端到端的LSTM。作者还基于DAQUAR数据集搜集了额外的答案,构建了DAQUAR-Consensus数据集,并提出了两个新的metric。
用
x
x
x表示输入图片,用
q
q
q表示输入问题,用
a
a
a表示模型输出的答案。作者在第t个时间步时,将
v
t
=
[
x
,
[
q
,
a
]
]
v_t=[x,[q,a]]
vt=[x,[q,a]]输入LSTM模块,训练时,
a
a
a为gt,测试时,
a
=
[
a
1
,
.
.
.
,
a
t
−
1
]
a=[a_1,...,a_{t-1}]
a=[a1,...,at−1]。
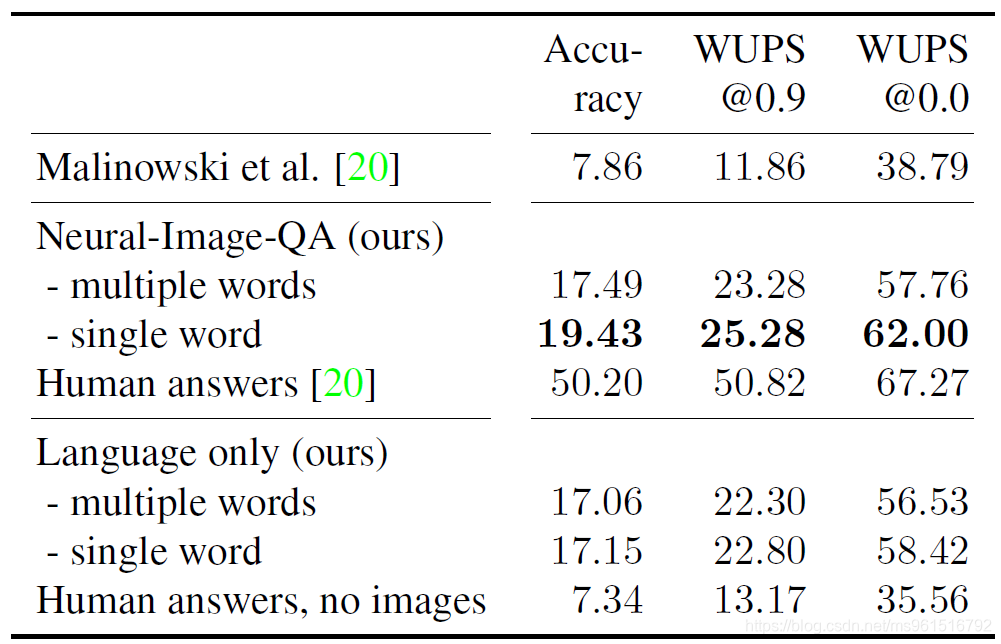
在DAQUAR数据集上的实验结果:
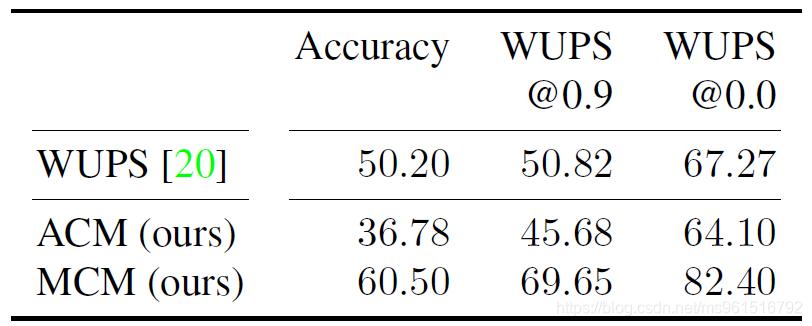
下图是在DAQUAR-Consensus数据集上的实验结果,其中ACM(Average Consensus Metric)和MCM(Min Consensus Metric)是本文提出的新metric,前者定义为
1
N
K
∑
i
=
1
N
∑
k
=
1
K
min
{
∏
a
∈
A
i
max
t
∈
T
k
i
μ
(
a
,
t
)
,
∏
t
∈
T
k
i
max
a
∈
A
i
μ
(
a
,
t
)
}
\frac{1}{NK} \sum_{i=1}^{N} \sum_{k=1}^{K} \text{min} \{ \prod_{a \in A^i} \text{max}_{t \in T_k^i} \mu(a,t), \prod_{t \in T_k^i} \text{max}_{a \in A^i} \mu(a,t) \}
NK1∑i=1N∑k=1Kmin{∏a∈Aimaxt∈Tkiμ(a,t),∏t∈Tkimaxa∈Aiμ(a,t)}。后者定义为
1
N
∑
i
=
1
N
max
k
=
1
K
(
min
{
∏
a
∈
A
i
max
t
∈
T
k
i
μ
(
a
,
t
)
,
∏
t
∈
T
k
i
max
a
∈
A
i
μ
(
a
,
t
)
}
)
\frac{1}{N} \sum_{i=1}^{N} \text{max}_{k=1}^K ( \text{min} \{ \prod_{a \in A^i} \text{max}_{t \in T_k^i} \mu(a,t), \prod_{t \in T_k^i} \text{max}_{a \in A^i} \mu(a,t) \})
N1∑i=1Nmaxk=1K(min{∏a∈Aimaxt∈Tkiμ(a,t),∏t∈Tkimaxa∈Aiμ(a,t)})。其中,
A
i
A^i
Ai是模型对第
i
i
i个问题的答案,
T
k
i
T^i_k
Tki是人类对第
i
i
i个问题的第
k
k
k中可能的回答,
μ
(
a
,
t
)
\mu(a,t)
μ(a,t)是一个评价指标,比如WUP。
[2015][ICCV] Visual Madlibs: Fill in the blank Description Generation and Question Answering
文章链接
本文作者出自北卡罗来纳大学,一作为Licheng Yu。本文主要是提出了两个新task,并构造了数据集Visual Madlibs。第一个task是targeted natural language generation,简称TNLG,第二个是multiple-choice question answering,简称MCQA。
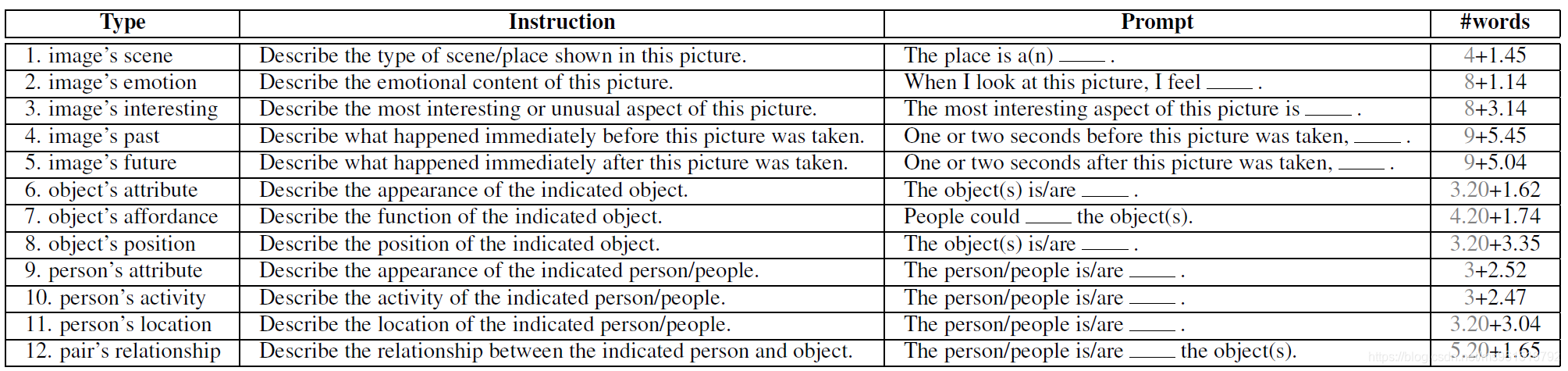
TNLG任务其实和image caption任务类似,不同的点在于,TNLG是填空式caption,输入是:一张图片、一个Instruction和一个Prompt,需要模型输出blank处的答案。MCQA任务的输入包含TNLG的输入,但多了许多个候选答案,模型需要选出最适合填入blank中的答案。
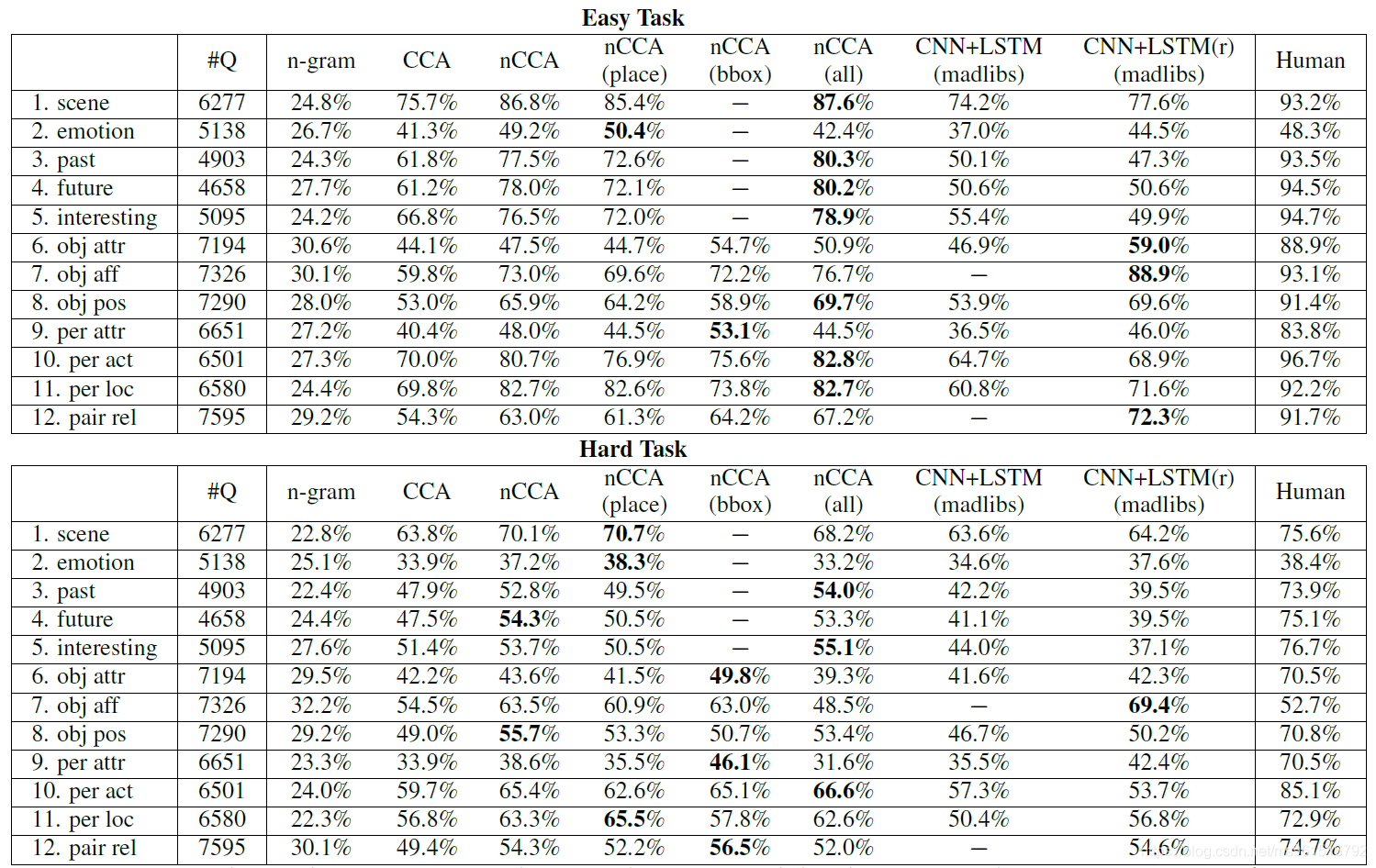
实验上,作者在一些baseline方法,还有一些简单的joint-embedding方法上进行了对比,下面是MCQA任务的实验结果。
[2015][ICCV] VQA: Visual Question Answering
文章链接
本文出自Virginia Tech和微软研究院,一作是Stanislaw Antol。本文是第一篇明确提出VQA(Visual Question Answering)任务的文章。VQA任务定义为:输入文本形式问题+一张图片,输出文本形式答案。且此任务是开放、自由的,不提供候选答案(虽然本文提到他们也提出了多选VQA任务),也不fill in blank。
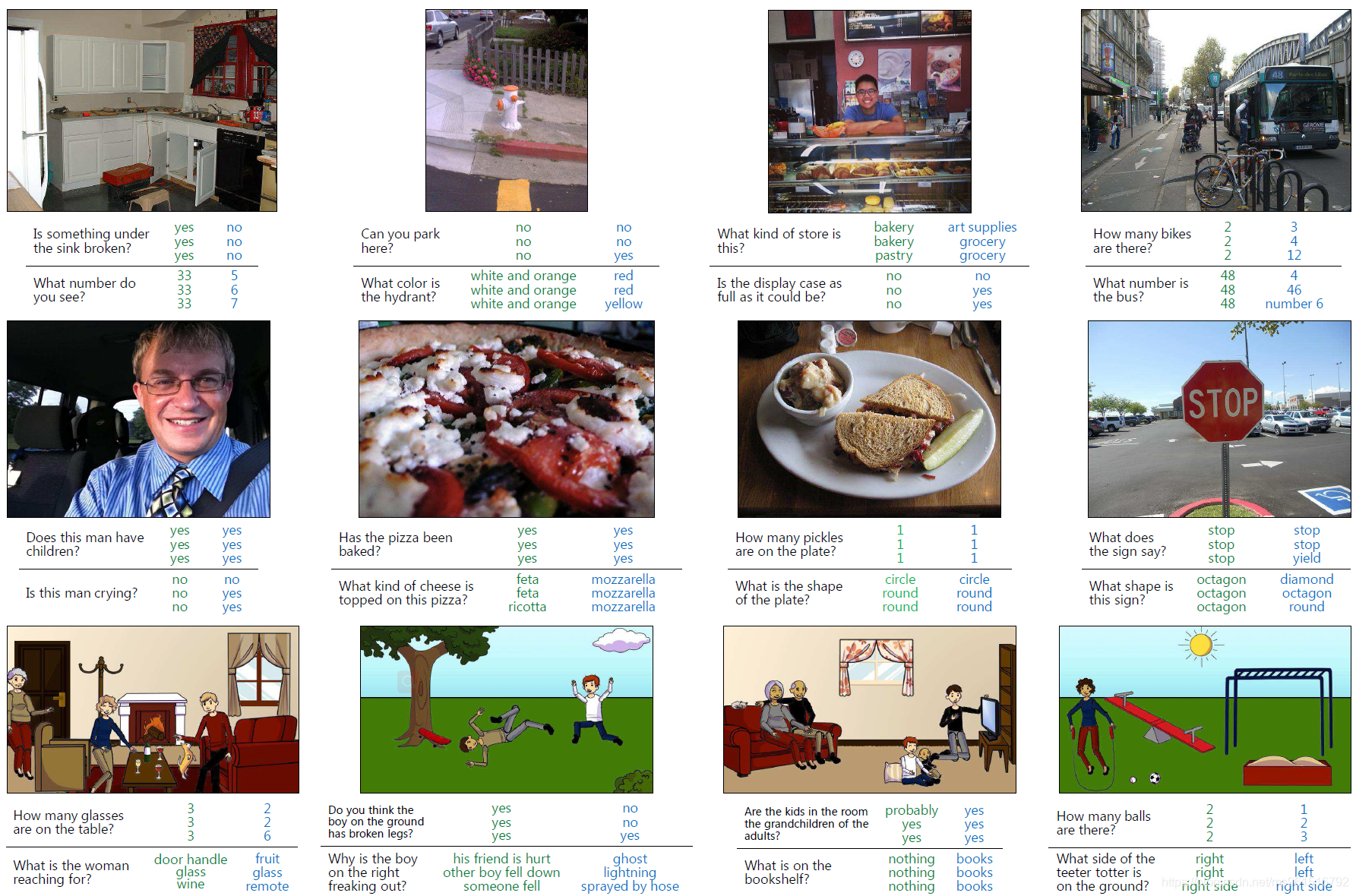
本文构造的数据集叫作VQA v1.0,包含265016张图片(来自COCO),每张图片有至少3个问题,每个问题有10个候选答案、3个假答案。
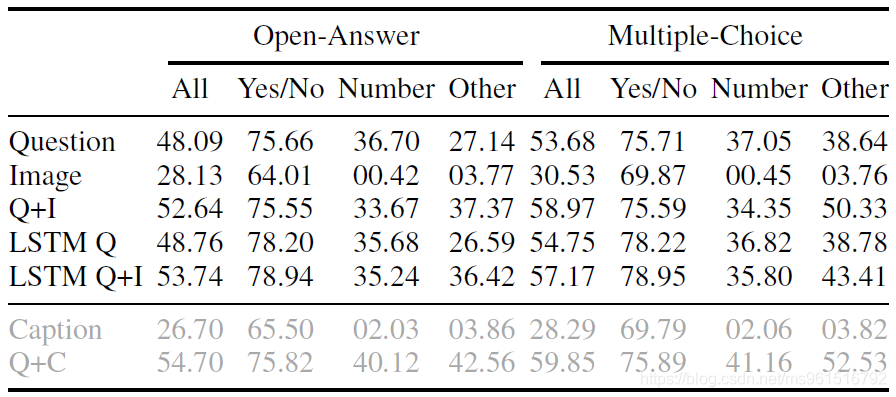
在实验部分,本文构建了两个简单的baseline model。首先,取数据集中最常见的1000中答案,作为备选(基本可以回答82.67%的问题)。分别训练一个MLP和LSTM+softmax模型,将VQA问题视为1000分类问题去训练,作为baseline。下图是实验结果,Q代表question,I代表image,C代表caption(图片的human caption结果),表示在不同的输入下,模型的结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









