







Semi-supervised Domain Adaptation based on Dual-level Domain Mixing for Semantic Segmentation
最近在看CVPR2021的Domain Adaptation的论文
概括
本文利用一个带标签的源数据集与一个含少量标签的目标数据集,训练一个基于区域尺度混合数据的“老师”模型和一个基于样本尺度混合数据的“老师”模型,然后共同指导训练一个“学生”模型,由“学生”输出未含标签图片的“虚假”标签,生成的结果再加到训练集中训练。
图片数据有三种:源数据集的图片Ds全部带有标签;目标数据集中,少量数据Dt打上标签,大量未含标签的图片Du。

Region-level data mixing
使用CutMix的图片混合方法,用于引导模型去关注对象中辨别能力较弱的部分,比如狗的腿部而不是狗的头部,从而使网络去有更强的概括能力,并且可以获得更好的object定位能力。
本文使用一个mask,白色区域保留target图片,黑色区域换成source图片的对应区域。目的是让模型学习domain-invariant representation,可以让模型在一张图片中学习到不同的特征分布。生成图片的GT也对应地调整。

MRL 表示一个在区域尺度混合的数据集上训练的teacher模型。以下是它的交叉熵损失函数。
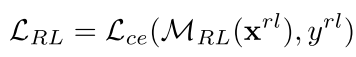
Sample-level data mixing
直接混合source与带标签的target,大量源图像的引入缓解了模型对少量目标图像的过拟合问题,样本层次混合有助于从整体的角度探索不同领域之间的中间决策边界。

训练时,选取从source一张Xs,也从有标签的taget中选取一张Xt,同时输入训练,得到一个在样本尺度混合的数据集上训练的teacher模型MSL,以下是交叉熵损失函数:
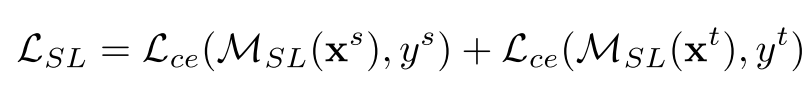

Multi-teacher Knowledge Distillation
训练得到两个teacher模型后,开始指导训练student模型,student模型与teacher模型有一样的结构,一开始输入的图片也是Ds,Dt,student的输出与两个teacher的输入平均值 作KL散度最小化,这称为知识蒸馏knowledge distillation (KD)。而且,student同时对target集的带标签的图片Xt进行训练。
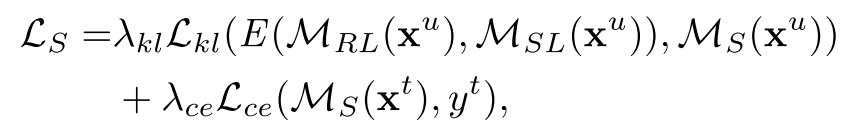

1.进行R轮训练:
2. 先准备mixing的数据集;
3. 同Ds、Dt训练两位teachers;
4. 用Ds、Dt训练student;
5. 用student生成“假”标签;
6. “假”标签加到Dt里面
















 648
648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









