






▼最近直播超级多,预约保你有收获
今晚直播:《LangChain智能问答架构设计与实现》
—1—
LangChain 构建知识问答架构设计
基于 LangChain 和大模型 in-context 能力构建企业级智能问答系统架构设计如下所示,包含了数据服务、在线 QA 服务、大模型推理服务3个核心模块。
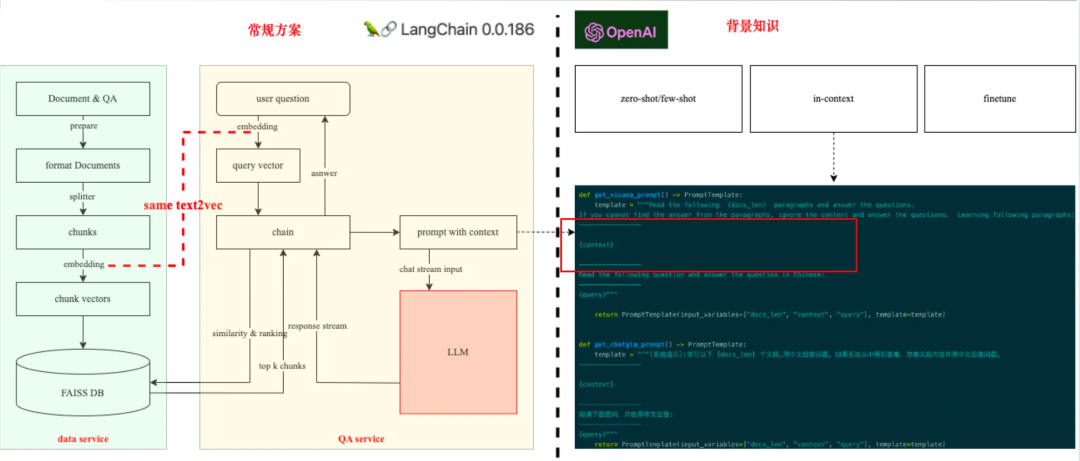
第一、数据服务
大模型 80% 的性能取决于数据,因此高质量的数据对大模型推理效果提升十分显著。但数据的处理是一个 CaseByCase 的非标准化过程,比如:文本、图片、表格、公式、超链接、附件、架构图、流程图、代码片段等处理方式各不相同。
数据处理最关注的是大模型的输入和格式,知识问答本质是 NLP 的一个任务,数据形态必须是文本,这是最基本的原则。
总体来讲,数据服务包括3个处理步骤:格式化(format)、切分(split)、向量化(vectorize)。
格式化(format):解析异构的源数据(csv、pdf、json、html、markdown、txt、jpg 等)到统一格式,并进行预处理与过滤。
切分(split):将格式化的长字符串按照一定策略切分为若干个切片(chunk)。
向量化(vectorize): 通过 embedding modle 将 text 的语义信息转为向量表达,存储在 Faiss 向量数据库中。
第二、在线 QA 服务
在线 QA 服务是大模型和向量数据库的连接桥梁,大模型不能将数据库中的所有数据拿去做 in-context,在线 QA 服务的核心就是挑选出 TopK 的 chunks 给到大模型。在线 QA 服务包含3个核心功能模块:用户问题向量化、Prompt 组装、筛选 chunks。
用户问题向量化:同数据服务 chunks 向量化一样,采用同一个 embedding model 对用户问题进行向量化。
Prompt 组装:将用户问题,筛选出的 chunks 组装成 Prompt,Prompt 即为大模型的输入,整个 Prompt 不超过大模型输入 tokens 长度的限制,比如:GPT-4 Turbo 支持 128K 上下文。
筛选 chunks :LangChain 通过计算向量的相似度(cos、BM25、knn、欧式距离等相似度算法),直接召回排序 Top5 chunks 给大模型进行 in-context 推理。
第三、大模型推理服务
在线 QA 服务使用了 LLM in-context 的推理能力,将筛选出来的若干个 chunks 传给大模型,让大模型基于这些 chunks 来回答用户问题,有个限制是整个 Prompt 的 tokens 长度不要超过 LLM 输入 tokens 限制,不然 GPU 会报 OOM。LLM in-context 的推理能力本质是其在阅读理解,因此,选择问答系统的 LLM 需要重点关注其在阅读理解任务上的性能,好的 LLM 可以非常精准的从一组 chunks 中寻找并总结出用户 Query 对应的答案。
基于上述架构,使用 OpenAI 全家桶以及开源 LLM 方案性能对比如下:
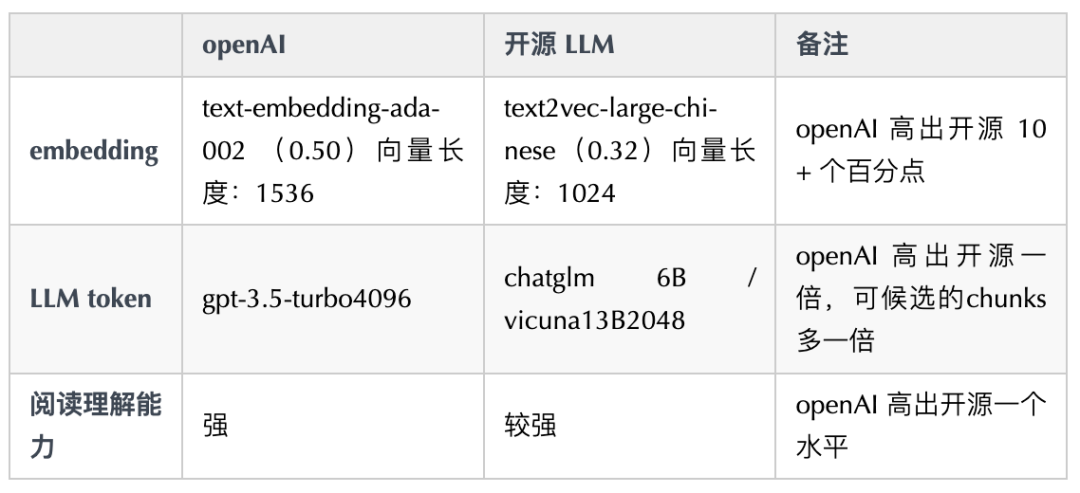
综上来看,选择目前开源最好的组合方案:LLaMA 的 Vicuna 13B 与中文领域开源最好的 embedding 模型 GanymedeNil/text2vec-large-chinese · Hugging Face,和采用 LangChain + OpenAI 技术框架相比,性能会下降很多。
今晚我们就这个问题详细剖析下 LangChain 技术架构、性能优化、线上资源部署、并发设计等,请同学点击下方按钮预约今晚直播。
重磅福利:2024年带你全面掌握 AIGC 技术体系:大模型架构内核、Fine-tuning 微调、LangChain 开发框架、Agent 开发、向量数据库、部署治理等核心技术,扫码免费一键全部预约干货直播!

END















 1818
1818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









