






1、基础知识
LIama2 是 Meta 最新开源的语言大模型,训练数据集2万亿 token,上下文长度是由 LIama 的2048扩展到4096,可以理解和生成更长的文本,包括 7B、13B和70B三个模型,在各种基准集的测试上表现突出,最重要的是,该模型可用于研究和商业用途。
1.1 分词(tokenize)
语言模型是对文本进行推理。由于文本是字符串,但对模型来说,输入只能是数字,所以就需要将文本转成用数字来表达。最直接的想法,就是类似查字典,构造一个字典,包含文本中所有出现的词汇,比如中文,可以每个字作为词典的一个元素,构成一个列表;一个句子就可以转换成由每个词的编号(词在词典中的序号)组成的数字表达。
tokenize 就是分词,一般分成3种粒度:
第一、word(词)
词是最简单的方式,例如英文可以按单词切分。缺点就是词汇表要包含所有词,词汇表比较大;还有比如“have”,"had"其实是有关系的,直接分词没有体现二者的关系;且容易产生 OOV 问题(Out-Of-Vocabulary,出现没有见过的词)。
第二、char(字符)
用基础字符表示,比如英文用26个字母表示。比如 "China"拆分为"C","h","i","n","a",这样降低了内存和复杂度,但增加了任务的复杂度,一个字母没有任何语义意义,单纯使用字符可能导致模型性能的下降。
第三、subword(子词)
结合上述2个的优缺点,遵循“尽量不分解常用词,将不常用词分解为常用的子词”的原则。例如"unbelievable"在英文中是un+形容词的组合,表否定的意思,可以分解成un”+"believable"。通过这种形式,词汇量大小不会特别大,也能学到词的关系,同时还能缓解 OOV 问题。
subword分词主要有BPE,WorkdPiece,Unigram等方法。
BPE:字节对编码,就是是从字母开始,不断在语料库中找词频最高、且连续的token合并,直到达到目标词数。
WordPiece:WordPiece算法和BPE类似,区别在于WordPiece是基于概率生成新的subword而不是下一最高频字节对。
Unigram:它和 BPE 等一个不同就是,bpe是初始化一个小词表,然后一个个增加到限定的词汇量,而 Unigram 是先初始一个大词表,接着通过语言模型评估不断减少词表,直到限定词汇量。
当然,现在已经有很多预训练好的词汇表,如果需要扩充新的语言,比如中文,可以先收集好语料库(训练文本),然后用 SentencePiece 训练自己的分词模型。具体可以看【https://github.com/taishan1994/sentencepiece_chinese_bpe】。
1.2 Embedding
经过分词,文本就可以分解成用数字表示的 token 序列。对于一个句子,最直接的表示法就是 one-hot 编码。假如词汇表【我,喜,欢,吃,面】,此时词汇大小(vocab_size)大小为5,那句子“我喜欢”用one-hot编码如下图。当词汇表特别大时(LIama词汇大小是3万多),句子的向量(n*vocab_size)表示也就变的比较大;另外,“喜欢”这个词出现在一起的频率其实比较高,但 one-hot 编码也忽略了这个特性。

Embedding就是将句子的向量表示压缩,具体就是词汇表的每个词映射到一个高维(d维)的特征空间。
# 一般embedding在语言模型的最开始,也就是词token操作之后
# vocab_size 词汇表大小,hidden_size 隐藏层维度大小
word_embeddings= nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
# input_ids是句子分词后词id,比如上述的“我喜欢”可转换成为[0,1,2],数字是在词汇表【我,喜,欢,吃,面】中的索引,即token id
embeddings = word_embeddings(input_ids) # embeddings的shape为[b,s,d],b:batch,s:seq_len,d:embedding sizeEmbedding的每维特征都可以看出词的一个特征,比如人可以通过身高、体重、地址、年龄等多个特征表示,对于每个词 Embedding 的每个维度的具体含义,不用人为定义,模型自己去学习。这样,在d维空间上,语义相近的词的向量就比较相似了,同时Embedding还能起到降维的作用,将one-hot的[s,vocab_size]大小变成了[s,d]。
1.3 transformer
目前大语言模型都是基于transformer结构。
下图说明transformer的结构,第一张图代表 transformer 的结构,第二张图说明 position embedding。

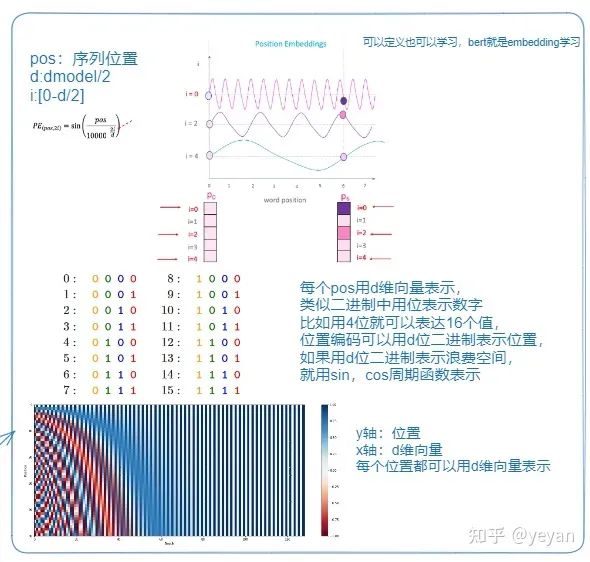
未完待续!















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









