






 本文介绍了LLM大模型的两种增强方式:RAG(检索增强生成)和Fine-tuning,特别是LoRA微调的应用。同时提供了免费直播,详细讲解大模型微调技术及知识图谱和学习路线,旨在帮助IT专业人士更好地理解和应用大模型技术。
本文介绍了LLM大模型的两种增强方式:RAG(检索增强生成)和Fine-tuning,特别是LoRA微调的应用。同时提供了免费直播,详细讲解大模型微调技术及知识图谱和学习路线,旨在帮助IT专业人士更好地理解和应用大模型技术。
▼最近直播超级多,预约保你有收获
今晚直播:《基于LoRA微调大模型应用实战》
—1—
如何对 LLM 大模型增强?
对 LLM 大模型能力增强在企业级有两种实践路线:RAG 和 Fine-tuning。接下来我们详细剖析下这两种增强实现方式。
第一:检索增强生成 RAG(Retrieval Augmented Generation)实现方式。
2020 年,Lewis et al. 的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》提出了一种更为灵活的技术:检索增强生成(RAG)。在这篇论文中,研究者将生成模型与一个检索模块组合到了一起;这个检索模块可以用一个更容易更新的外部知识源提供附加信息。
用大白话来讲:RAG 之于 LLM 就像开卷考试之于人类。在开卷考试时,学生可以携带教材和笔记等参考资料,他们可以从中查找用于答题的相关信息。开卷考试背后的思想是:这堂考试考核的重点是学生的推理能力,而不是记忆特定信息的能力。
类似地,事实知识与 LLM 大模型的推理能力是分开的,并且可以保存在可轻松访问和更新的外部知识源中:
参数化知识:在训练期间学习到的知识,以隐含的方式储存在神经网络权重之中。
非参数化知识:储存于外部知识源,比如向量数据库。
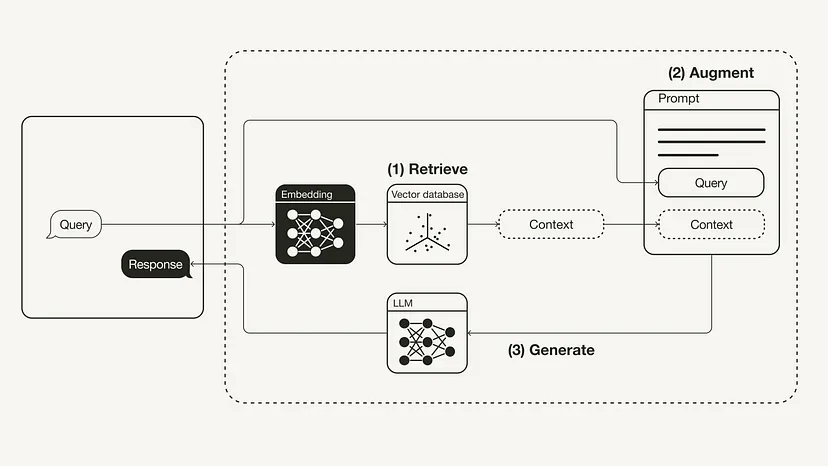
上图检索增强生成(RAG)的工作流程如下所示:
1、检索(Retrieval):将用户查询用于检索外部知识源中的相关上下文。为此,要使用一个嵌入模型将该用户查询嵌入到同一个向量空间中,使其作为该向量数据库中的附加上下文。这样一来,就可以执行相似性搜索,并返回该向量数据库中与用户查询最接近的 k 个数据对象。
2、增强(Augmented):然后将用户查询和检索到的附加上下文填充到一个 prompt 模板中。
3、生成(Generation):最后,将经过检索增强的 prompt 馈送给 LLM。
第二:微调(Fine-tuning) 实现方式。
通过微调模型,可以让神经网络适应特定领域的或专有的信息。
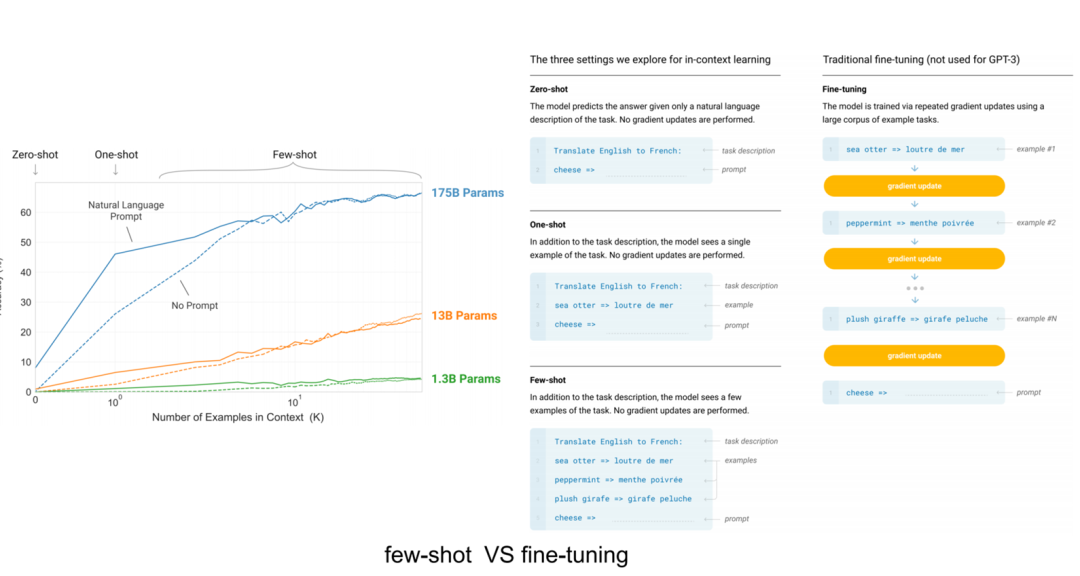
微调技术按照参数量不同,分为全参数微调和局部参数微调,由于全参数微调周期比较长,微调成本和一次预训练成本差别不大,因此全参数微调在实际企业级生产环境中基本不使用,更有效的微调方式是少参数量微调,比如:基于 LoRA、Prompt tuning、Prefix tuning、Adapter、LLaMA-adapter、P-Tuning V2 等微调技术。
基于 LoRA 可以高效进行微调,通过把微调参数量减少为万分之一,达成同样的微调效果。
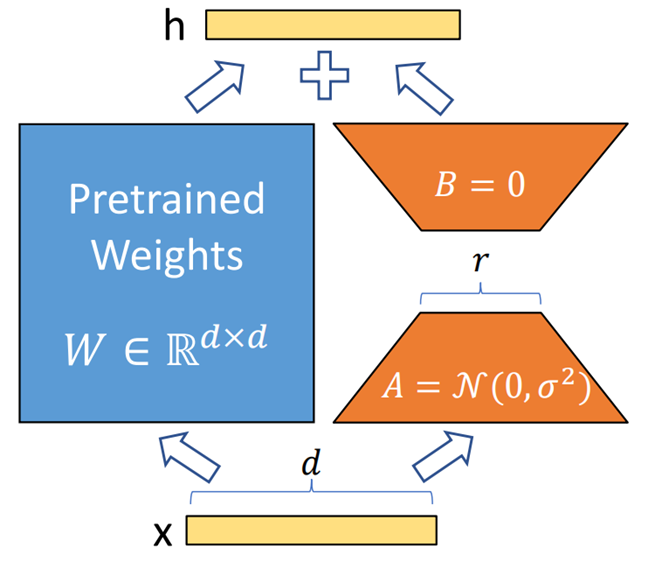
微调技术是有效的,但其需要密集的计算,成本高,还需要技术专家的支持,因此需要对微调技术有一定的认知和掌握,才能做好微调。
—2—
免费超干货大模型微调技术实战直播
为了帮助同学们掌握好 LLM 大模型微调技术架构和应用案例实战,今晚20点,我会开一场直播和同学们深度聊聊 LLM 大模型高效微调技术架构、高效微调案例实战、 基于 Transformen 架构的高效微调核心技术,请同学点击下方按钮预约直播,咱们今晚20点不见不散哦~~
近期直播:《大模型Transformer架构剖析以及微调应用实践》
—3—
关于《LLM 大模型技术知识图谱和学习路线》
最近很多同学在后台留言:“玄姐,大模型技术的知识图谱有没?”、“大模型技术有学习路线吗?”
我们倾心整理了大模型技术的知识图谱《最全大模型技术知识图谱》和学习路线《最佳大模型技术学习路线》快去领取吧!
LLM 大模型技术体系的确是相对比较复杂的,如何构建一条清晰的学习路径对每一个 IT 同学都是非常重要的,我们梳理了下 LLM 大模型的知识图谱,主要包括12项核心技能:大模型内核架构、大模型开发API、开发框架、向量数据库、AI 编程、AI Agent、缓存、算力、RAG、大模型微调、大模型预训练、LLMOps 等12项核心技能。

为了帮助每一个程序员掌握以上12项核心技能,我们准备了一系列免费直播干货,扫码一键免费全部预约领取!

END

















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









