






 本文介绍了MyScaleAI数据库,一个高性能、SQL兼容的AI数据库,支持结构化和非结构化数据处理,特别强调了其在大模型开发中的应用,包括向量搜索、SQL查询的兼容性和生产级保障。作者还预告了一场关于大模型技术的直播课程和知识图谱的赠送。
本文介绍了MyScaleAI数据库,一个高性能、SQL兼容的AI数据库,支持结构化和非结构化数据处理,特别强调了其在大模型开发中的应用,包括向量搜索、SQL查询的兼容性和生产级保障。作者还预告了一场关于大模型技术的直播课程和知识图谱的赠送。
、▼最近直播超级多,预约保你有收获

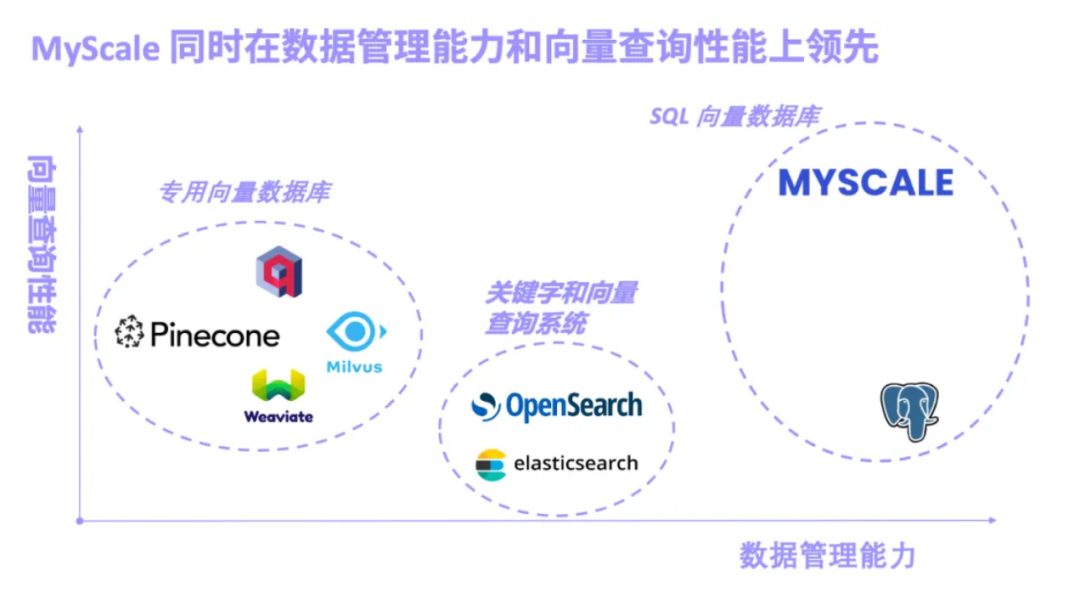
RAG 的出现使得大模型能从大规模的知识库中精确地抽取信息,并生成实时、专业、富有洞察力的答案。伴随而来的是 RAG 系统的核心功能向量数据库也得到了迅速发展,按照向量数据库的设计理念我们可以将其大致分为三类:专用向量数据库、关键字和向量结合的检索系统、SQL 向量数据库。
专用向量数据库以 Pinecone/Milvus 为代表。
关键字和向量检索系统以 Elasticsearch 为代表。
SQL向量数据库以 pgvector(PostgreSQL 的向量搜索插件)和 MyScale AI 数据库为代表。
接下我们详细介绍下开源的 MyScale AI 数据库。
—1—
MyScale AI 数据库是什么?
MyScaleDB 是一款高性能、可扩展且极具成本效益的 AI 数据库,旨在为构建和扩展 AI 应用程序提供坚实的数据底座。它将向量搜索和存储能力整合到一个可扩展的关系型数据库中,支持高效地存储和处理结构和非结构化数据,旨在减少工程复杂性,同时确保 AI 应用的最佳性能表现。
MyScaleDB 的重要特性之一是与 SQL 完全兼容,开发者可以很轻松地使用强大而熟悉的 SQL 查询来加速向量搜索和处理, 以构建生产级别的 AI 大模型应用。
得益于 SQL 数据库在海量结构化数据场景长期的打磨,MyScaleDB 同时支持海量向量和结构化数据,包括字符串、JSON、空间、时序等多种数据类型的高效存储和查询,并将在近期推出功能强大的倒排表和关键字检索功能,进一步提高 RAG 系统的精度并替代 Elasticsearch 等系统。
项目开源地址:https://github.com/myscale/myscaledb
—2—
MyScaleDB 架构设计剖析
AI 大模型新时代时代,MyScale 团队致力于提出新一代的大模型 + 大数据方案。以高性能的 SQL + 向量数据库为坚实的支撑,MyScaleDB 提供了大规模数据处理、知识查询、可观测性、数据分析和小样本学习的关键能力,构建了 AI 和数据闭环,成为下一代大模型 + 大数据 Agent 平台的关键基座,如下图所示:
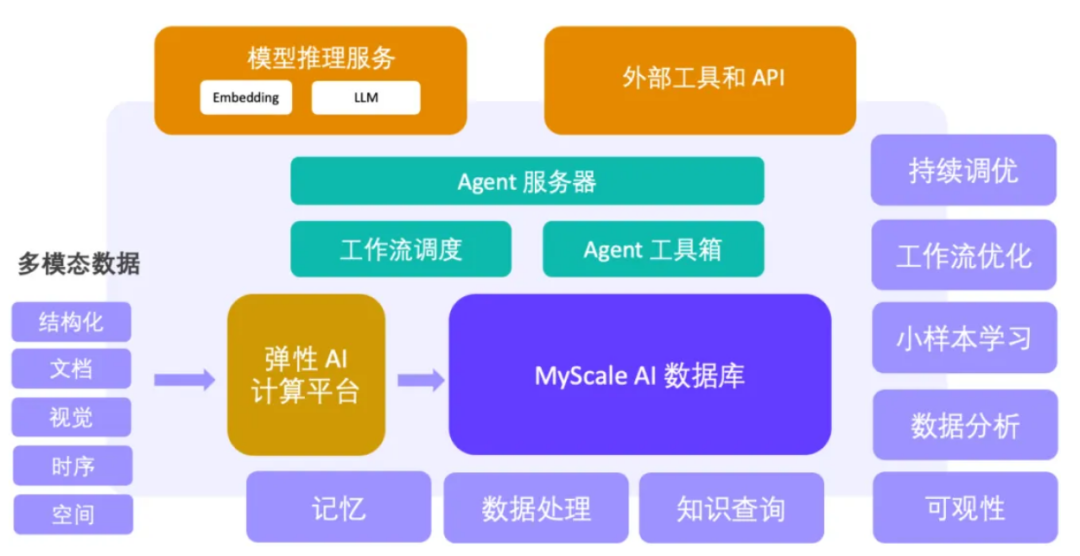
在架构落地过程中使用了如下的技术栈:

MyScaleDB 可以为轻松构建 AI 大模型应用,主要有以下3点优势:
第一、完全兼容 SQL
快速、强大、高效的向量搜索、过滤搜索和 SQL +向量联合查询。
使用 SQL 及向量相关的函数与 MyScaleDB 交互,无需学习复杂的新工具或框架。
第二、为 AI 大模型应用提供生产级别的特性和保障
以一个统一平台来管理和处理结构化数据和文本、向量、JSON、地理空间、时间序列等非结构化/半结构化数据。
通过将向量与丰富的元数据相结合,可以在任意比率下执行高精度、高效率的过滤搜索,提高了 RAG 系统的准确性。
第三、无与伦比的性能和可扩展性
MyScaleDB 利用先进 OLAP 数据库架构和高级向量算法,实现了快速的向量操作。
随着数据的增长,以轻松且具有成本效益的方式扩展你的应用程序。
为了帮助同学们彻底掌握大模型的向量数据库、 RAG、Agent 智能体、向量数据库、知识图谱的应用开发、部署、生产化,今晚20点我会开一场直播和同学们深度剖析,请同学们点击以下预约按钮免费预约。
—3—
!送!AI大模型开发直播课程
大模型的技术体系非常复杂,即使有了知识图谱和学习路线后,快速掌握并不容易,我们打造了大模型应用技术的系列直播课程,包括:通用大模型技术架构原理、大模型 Agent 应用开发、企业私有大模型开发、向量数据库、大模型应用治理、大模型应用行业落地案例等6项核心技能,帮助同学们快速掌握 AI 大模型的技能。
🔥即将开播
立即扫码,即可免费预约
进入直播,大佬直播在线答疑!


本期名额有限
高度起始于速度(手慢无!!)
—4—
!!再送!!《AI 大模型技术知识图谱》
最近很多同学在后台留言:“玄姐,AI 大模型技术的知识图谱有没?”、“AI 大模型技术有学习路线吗?”
我们倾心整理了 AI 大模型技术的知识图谱快来领取吧!

这份业界首创知识图谱和学习路线,今天免费送给大家一份!
只需要以下3步操作就可免费领取:
第一步:长按扫码以下我的视频号:玄姐谈AGI

第二步:扫码后,点击以下关注按钮,就可关注我。
第三步:点击"客服“按钮,回复“知识图谱”即可领取。
END















 1465
1465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









