




▼最近直播超级多,预约保你有收获

RAG 检索增强生成由2部分构成:一是离线对异构的数据进行数据工程处理成知识,并存储在知识库中,二是基于用户的提问进行知识库的检索增强。如下图所示:
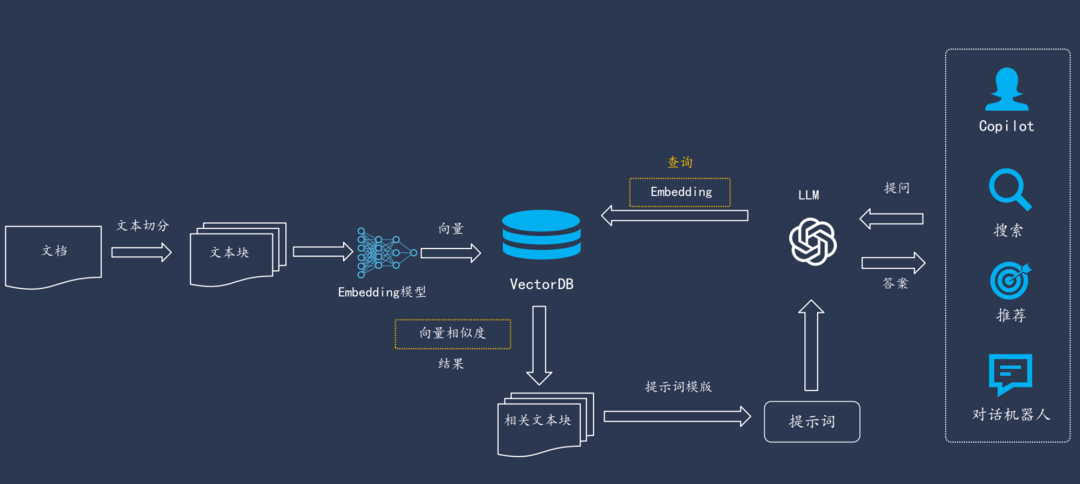
其中最关键的一个环节是 PDF 格式的文件如何提取成知识,下面详细剖析。
—1—
PDF 文件中文本数据如何提取?
能够处理文本提取的 Python 库有多个,其中较为知名的包括 pdfminer.six、PyMuPDF、PyPDF2 和 pdfplumber。在这些库中,PyMuPDF 因其出色的文本提取能力而备受推崇。特别是在处理双栏布局等复杂格式的 PDF 文件时,PyMuPDF 能够最大程度地保留 PDF 的阅读顺序,这对于确保文本内容的准确性和完整性至关重要。
下面我们将以双栏布局的 PDF 文件为例,展示使用 PyMuPDF 库进行文字提取的效果。

进行文本提取的代码如下所示:
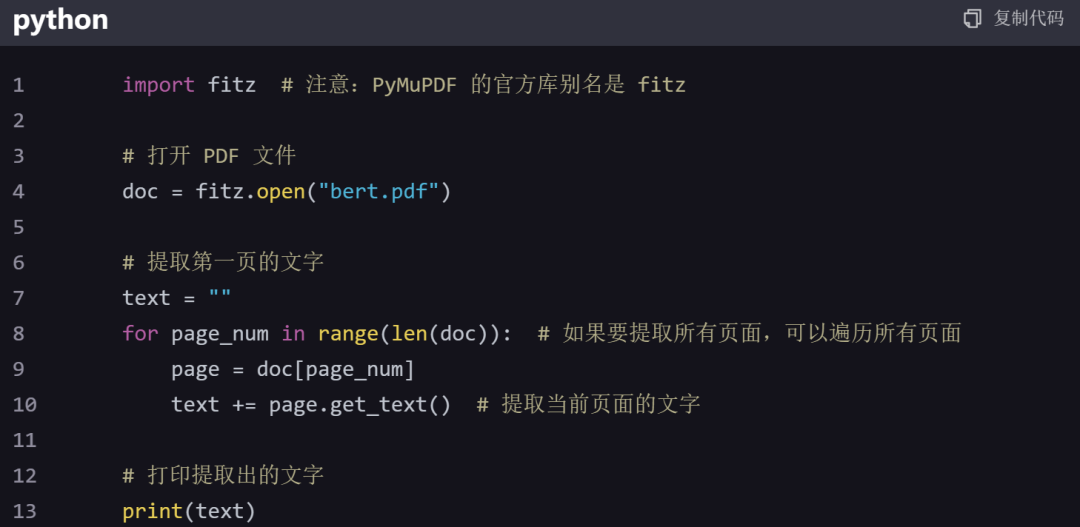
打印的结果如下所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 289
289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









