






▼最近直播超级多,预约保你有收获

Transformer 大模型,一种基于自注意力机制的神经网络架构,已被广泛应用于各种自然语言处理任务,比如:机器翻译、文本摘要、生成问答等。
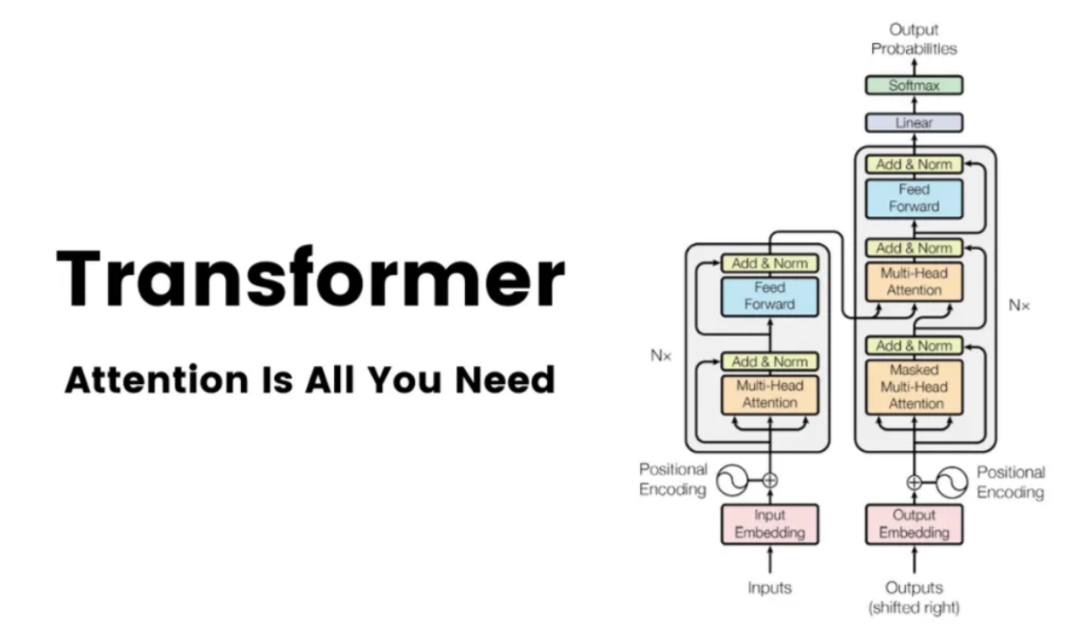
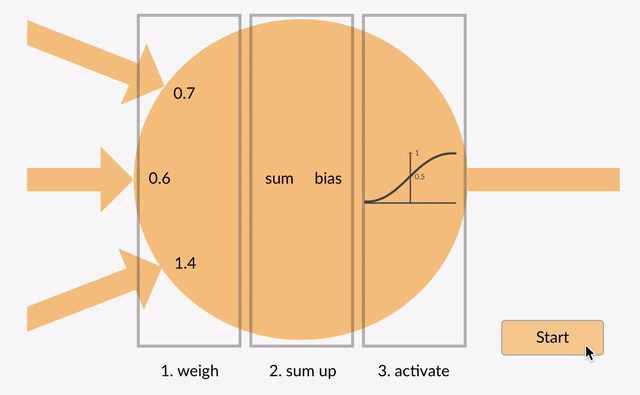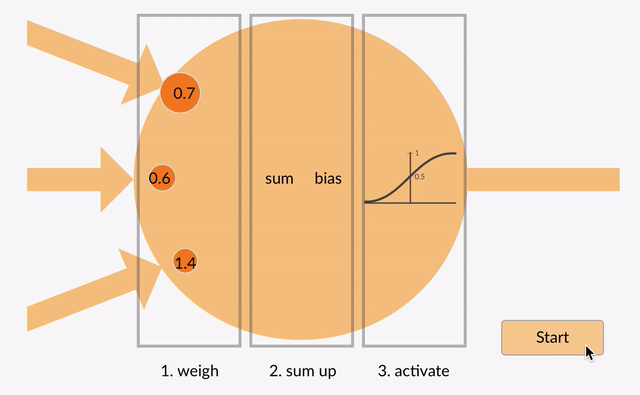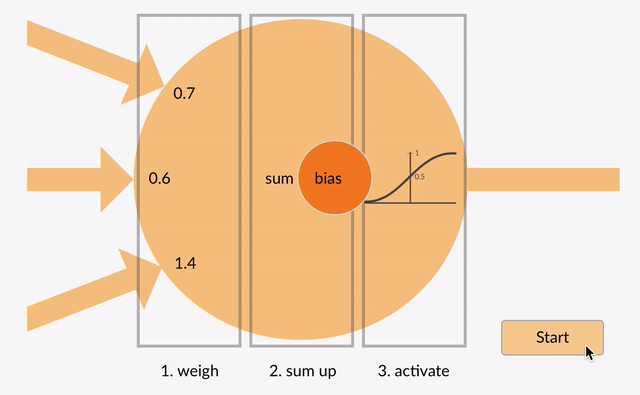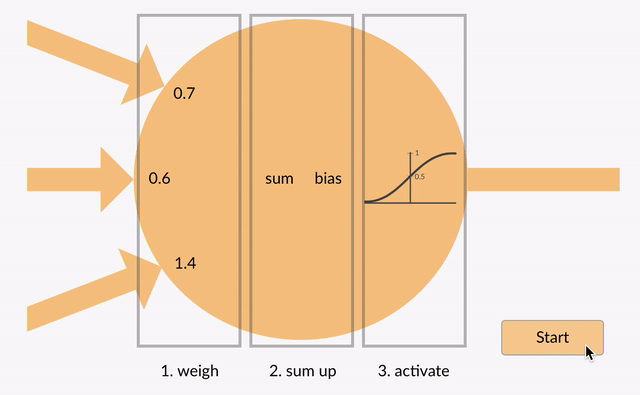
从端到端的角度来看,Transformer 大模型中数据的处理流程主要包括四个阶段:首先是嵌入阶段(Embedding),随后是注意力机制阶段(Attention),然后是通过多层感知机(MLPs)进行处理,最后是从模型的表示转换到最终输出的解嵌入阶段(Unembedding),如下图所示:
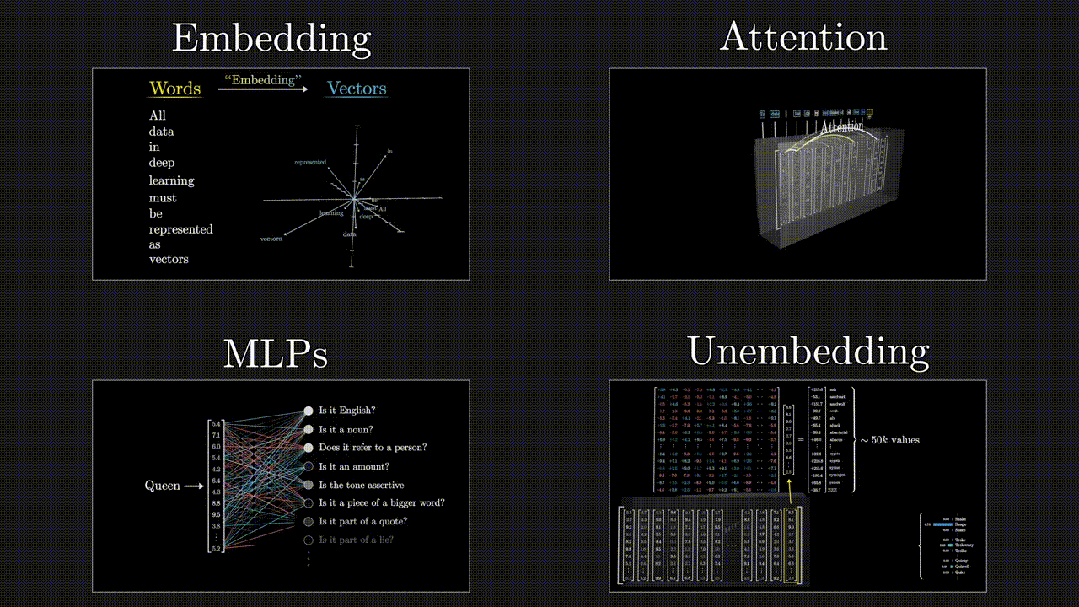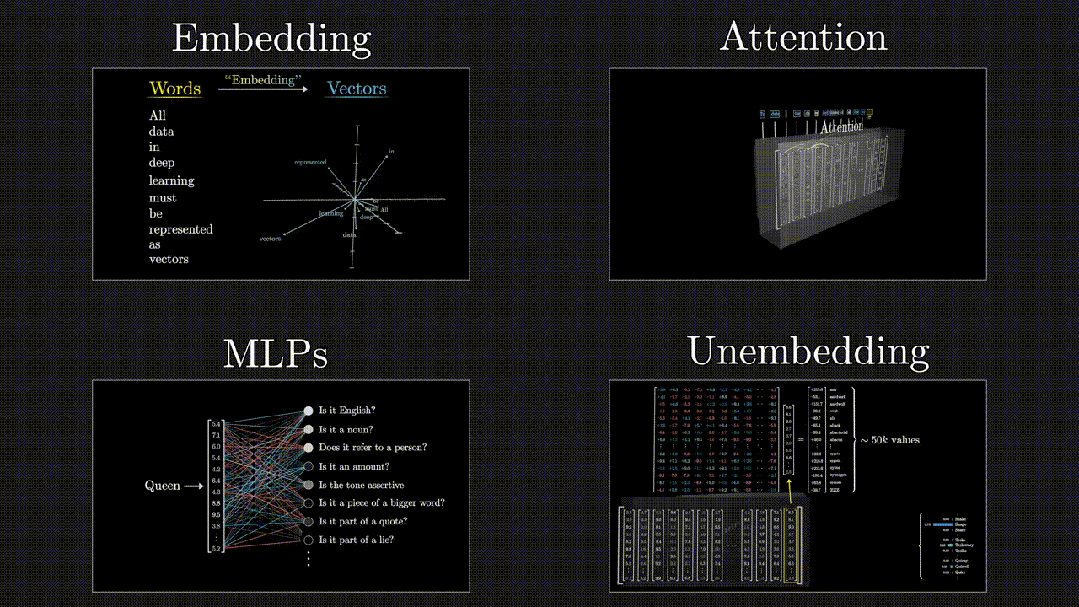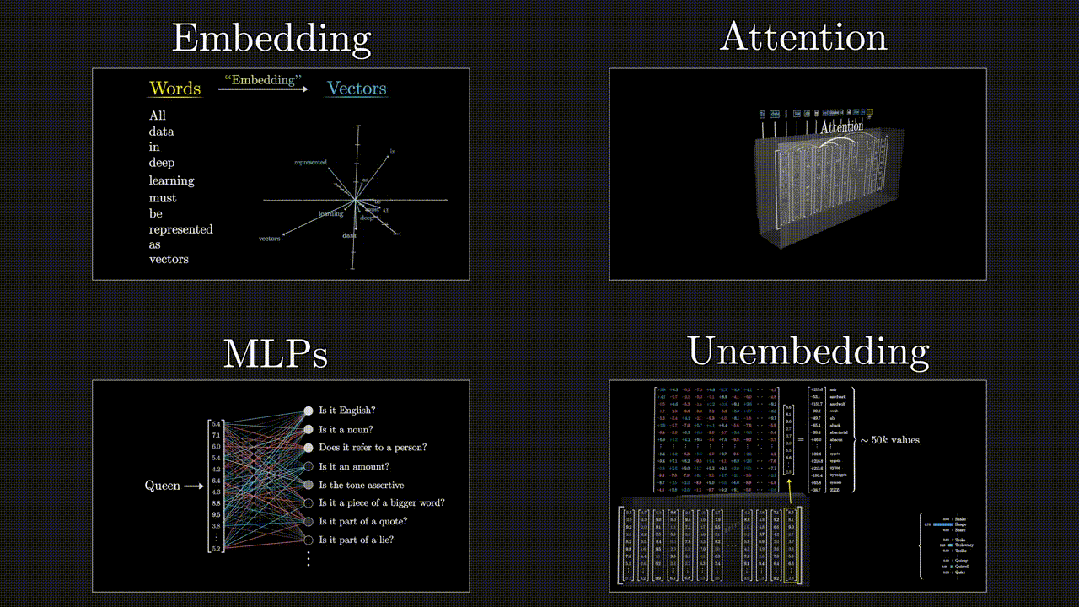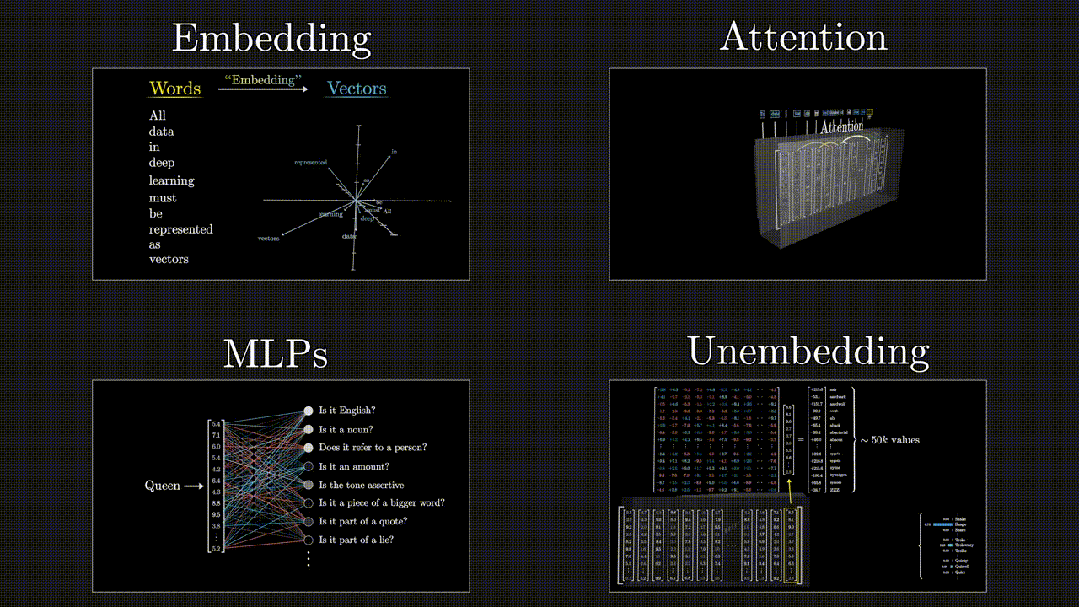
图:Embedding -> Attention -> MLPs -> Unembedding
下面是对这四个阶段的简要介绍。
—1—
Embedding(嵌入)阶段
大模型的输入通常由离散的词汇或符号组成(比如:在英文文本中,每个单词或标点符号都是一个单独的符号)。嵌入层的作用是将这些离散的符号转换成连续的、具有固定维度的向量(通常称为词嵌入)。这些向量能够捕获符号的语义以及上下文信息。

在Transformer 大模型中,无论是编码器(Encoder)还是解码器(Decoder),都包含一个嵌入层。此外,在解码器中,还会添加一个位置嵌入(Positional Embedding)层,用于记录序列中单词的位置信息,这是因为 Transformer 大模型不通过 RNN 或 CNN 等传统结构来直接捕捉序列的顺序信息。
—2—
Attention (注意力机制)阶段
注意力机制构成了 Transformer 大模型的基石,它使得大模型能够在产生当前输出时聚焦于输入序列中的各个部分。Transformer 大模型采用了多种类型的注意力机制,其中包括自注意力(Self-Attention)、编码器-解码器注意力(Encoder-Decoder Attention)以及掩码多头注意力(Masked Multi-Head Attention)。
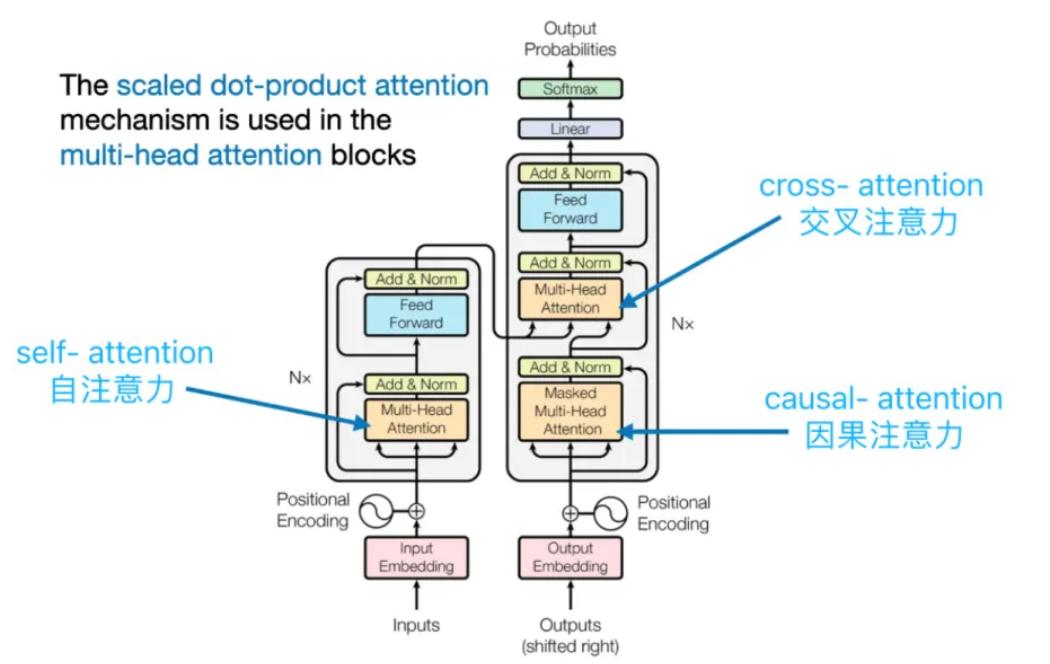
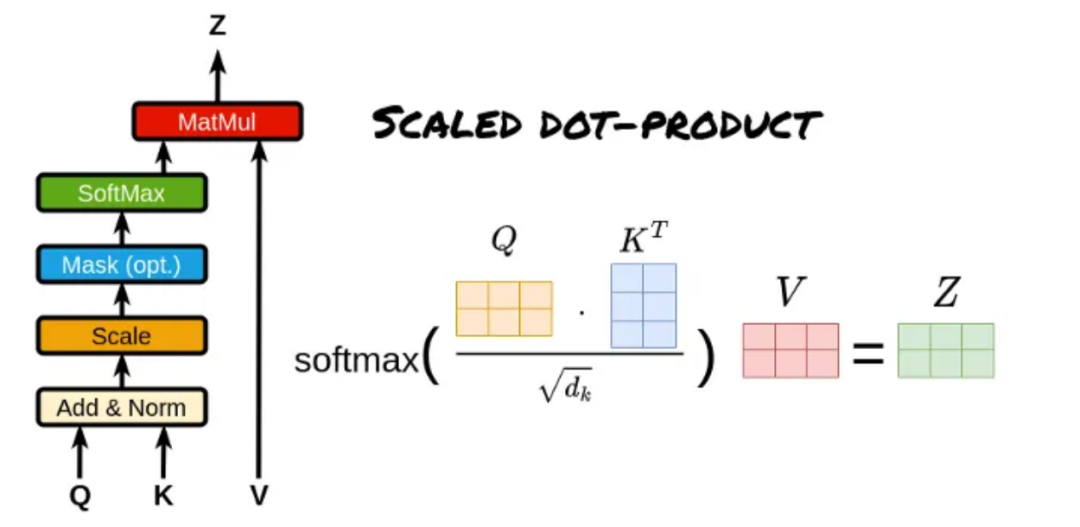
自注意力机制使得大模型能够识别序列内不同位置之间的相互关系,进而把握序列的内在结构。编码器-解码器注意力机制则使得大模型在输出生成过程中能够针对输入序列的特定部分给予关注。在注意力机制的运算过程中,会生成一个注意力权重矩阵,该矩阵揭示了输入序列中每个位置对于当前位置的贡献程度。
—3—
MLPs(多层感知机,也称为前馈神经网络)阶段
在注意力机制处理之后,大模型会利用一个或多个全连接层(也称为前馈网络或 MLPs)来进行更深层次的变换和特征提取。
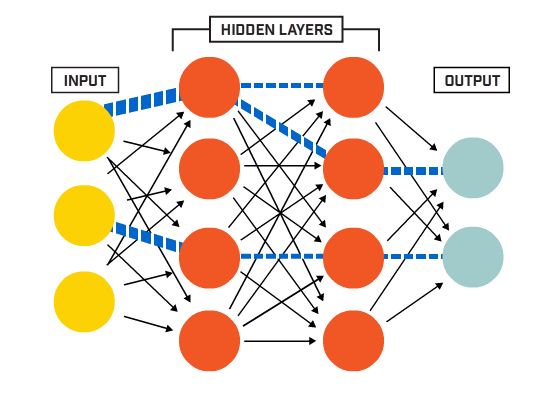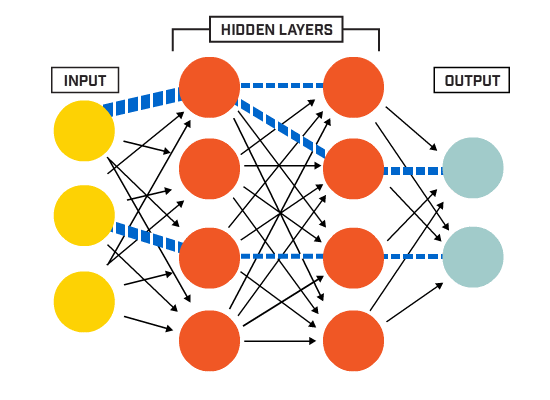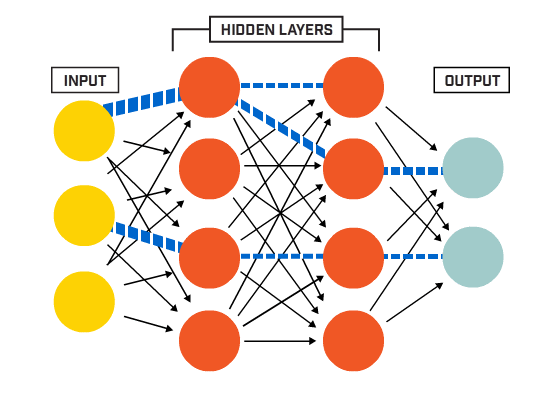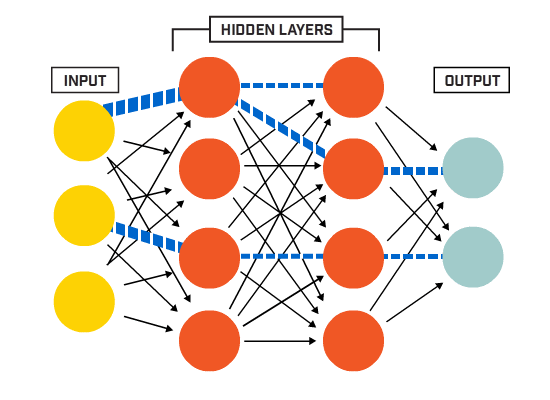
这些全连接层能够捕捉输入数据中的非线性关系,并辅助模型识别更复杂的模式。在 Transformer 大模型中,MLPs 一般被置于自注意力层和归一化层之间,共同构成了所谓的“编码器块”或“解码器块”。
—4—
Unembedding(从模型表示到最终输出)阶段
这一过程可以被视作从大模型的内部表示到最终输出格式的转换。
在文本生成任务中,比如:机器翻译,解码器的输出将通过一个线性层和一个 Softmax 函数,以产生一个概率分布,该分布反映了下一个输出词(token)的概率。

而在其他类型的任务中,比如:文本分类,解码器的输出可能直接用于损失函数的计算(比如:交叉熵损失),或者通过其他方法转换成最终的预测结果。
为了帮助同学们彻底掌握 AI 大模型 Agent 智能体、知识库、向量数据库、 RAG、微调私有大模型的应用开发、部署、生产化,今天我会开场直播和同学们深度剖析,请同学们点击以下预约按钮免费预约。
—5—
领取 AI 大模型学习资料
 不会吧,都2024年了,还有人在网盘、B站上爬学习资源?
不会吧,都2024年了,还有人在网盘、B站上爬学习资源?
 今天给大家搞到的是一份大厂内部都在用的『AI 大模型学习资源』:
今天给大家搞到的是一份大厂内部都在用的『AI 大模型学习资源』:
▶形式:直播公开课
▶费用:原价299,本号用户0元白嫖
▶内容:大模型原理、Agent、LangChain、Spring AI、RAG、向量数据库、知识库、私有大模型、算力评估...
扫码预约报名
👇『AI 大模型学习资源』👇
堪称资源界的YYDS!
“得此资源,堪比1000G网盘资源”
👇👇👇

本期名额有限

—6—
领取《AI 大模型技术知识图谱》

这份业界首创知识图谱和学习路线,今天免费送了!
第一步:长按扫码以下视频号,你身边需要一个 AI 专家。

第二步:点击"关注按钮",就可关注。
第三步:点击"客服“按钮,回复“知识图谱”即可领取。
—7—
每日精选 AI 大模型知识
END















 305
305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









