






大家好,我是玄姐。
正文开始之前,先给我自己打个广告,DeepSeek 爆火国之荣耀,为了回馈粉丝们的支持,原价199元的《基于 DeepSeek 打造的 AI Agent 智能体项目实战直播训练营》,直接降价到19元,今天再开放一天报名特权,仅限99名。
回到正题。
这个春节,DeepSeek 实在太火爆了。
在马斯克高调推出依托 20万 GPU 集群的 Grok-3,同时 Sam Altman 在开源策略上犹豫不决之时,DeepSeek 低调地又推出了一项可能颠覆行业的技术。
2月18日,DeepSeek 的首席执行官公布了由梁文锋亲自参与的最新研究成果——原生稀疏注意力(Native Sparse Attention, NSA)机制。这项由DeepSeek 团队研发的创新技术在稀疏注意力领域取得了突破,通过算法的革新和硬件的优化,旨在攻克长文本建模中的计算难题。

根据 DeepSeek 发布的论文(地址:https://arxiv.org/pdf/2502.11089),NSA 技术不仅将大语言模型处理64k长度文本的速度提升了最高11.6倍,而且在通用性能基准测试中超越了传统的全注意力模型。在全球 AI 竞争日益注重“硬核创新”的背景下,这家中国的低调企业展现了技术突破的新范例。
值得一提的是,NSA 技术还未被应用于 DeepSeek V3 模型的训练。这暗示了 DeepSeek 若将 NSA 技术融入模型训练,其基础模型性能有望得到显著增强。论文中明确提到:“经过 NSA 预训练的模型已经超越了全注意力模型。”
与此同时,与 DeepSeek 的路线形成鲜明对照的是,xAI 选择了追求工程规模的极致。2月18日,马斯克发布的 Grok-3 采用了20万 GPU 的集群,而即将推出的 Grok-4 更是计划使用高达百万 GPU、1.2GW 的超级集群。这种不惜成本的策略,展现了北美在 AI 领域一贯的“大力出奇迹”风格。
—1—
稀疏注意力:DeepSeek NSA 的创新之道
"AI 革命"迅猛推进,长文本建模在 AI 领域的地位愈发重要。无论是 OpenAI 的 o-series 模型、DeepSeek 的 R1,还是 Google 的 Gemini 1.5 Pro,都展现了处理超长文本的巨大潜力。
但是,传统的 Attention 机制计算复杂度随着序列长度的增加呈二次方增长,这成为了限制大语言模型(LLM)发展的主要障碍。
稀疏注意力机制被视为克服这一挑战的潜在解决方案。2月18日,DeepSeek 提出的 NSA 机制,是对去年5月 MLA(Multi-Layer Attention)研究的进一步补充。NSA 的精髓在于它将算法的创新与硬件的优化相融合,从而实现了高效的长文本建模。
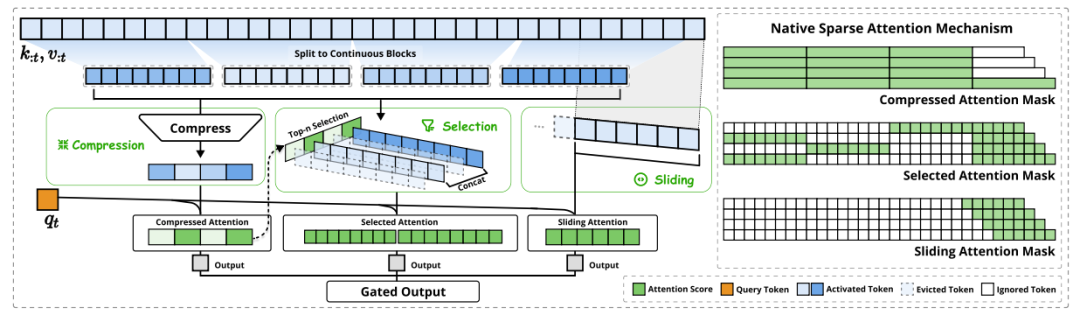
NSA 的三大创新亮点为:
第一、动态分层稀疏策略:通过粗粒度 Token 压缩与细粒度T oken 选择的结合,既保证了全局上下文的感知,又兼顾了局部信息的精确性。
第二、算术强度平衡设计:针对现代硬件特性进行优化,大幅提高了计算效率。
第三、端到端可训练性:支持端到端的训练模式,减少了预训练的计算需求,同时维持了模型的性能。
—2—
NSA 的核心组件:三位一体,逐层优化
NSA 架构实现了分层 Token 建模,通过三个平行的注意力分支来处理输入序列:
第一、压缩注意力(Compressed Attention):通过对 Token 块的压缩来捕捉全局信息,专注于粗粒度的模式识别。
第二、选择注意力(Selected Attention):专注于关键 Token 块,有选择性地保存细粒度的信息。
第三、滑动窗口注意力(Sliding Window Attention):负责处理局部上下文信息。
这三个分支的输出通过一个门控机制进行整合。为了提升效率,NSA 还特别设计了针对硬件优化的 Kernel。
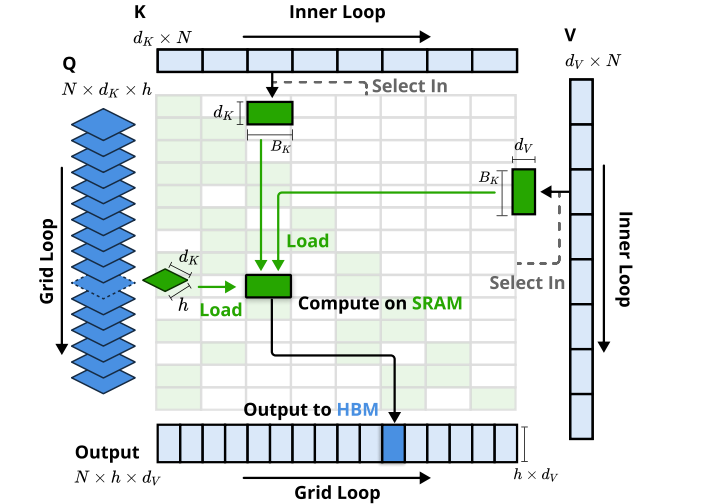
具体来说,在 Token 压缩阶段,NSA 采用基于 block 粒度的压缩计算,并融入位置信息编码。在选择注意力阶段,它巧妙利用压缩注意力的分数作为 block 的重要性评分,进行 top-N 筛选,以保留关键细粒度信息。滑动窗口部分则专注于处理局部上下文。最终,通过一个门控函数来综合这三种注意力的输出结果。
—3—
实验结果:性能与效率的双重飞跃
依据 DeepSeek 公布的实验结果,NSA 技术在众多领域均展现出非凡的性能。
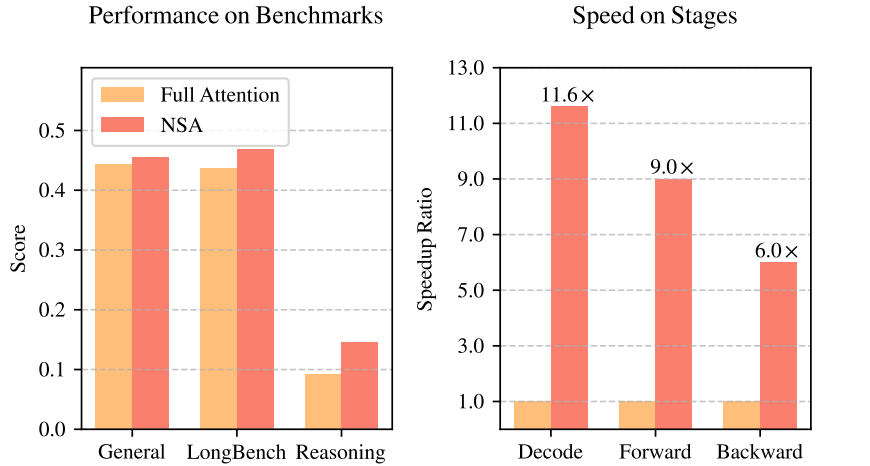
在一系列通用基准测试、长文本处理任务以及指令推理任务中,采用 NSA 技术预训练的模型不仅性能未减,反而超越了全注意力模型。更为关键的是,在处理高达 64k 字符长度的序列时,NSA 在解码、正向传播以及反向传播等多个环节均实现了明显的速度提升,最快可达到11.6倍的加速,充分证明了 NSA 在模型整个生命周期中各个阶段的高效性。
—4—
马斯克 Grok3:算力堆砌的“极致”
与 DeepSeek 的路线形成鲜明对照的是,Grok3 选择了截然不同的策略:追求工程规模的极限。Grok3 项目投入了 20万 GPU 的庞大集群,而即将问世的 Grok4 更是计划采用百万 GPU、1.2GW 的超级计算集群。这种“不惜成本”的方式,映射了北美在 AI 领域始终如一的“以规模求突破”的作风。
然而,根据信息平权的分析,尽管 Grok3 借助超大规模集群迅速超越了以往的 SOTA 模型,但其成本效益比并不令人满意。与 DeepSeek 的 V3 版本相比,Grok3 以高出50倍的成本仅实现了30%的性能增长。这一数据表明,仅仅在预训练阶段大量投入计算资源,其回报可能并不符合预期,而将资源集中于 RL (强化学习)的后续训练阶段或许更加物有所值。
总之,2025年一定是基于 DeepSeek 的应用爆发之年,其中最重要的应用形态就是 AI Agent 智能体,为了帮助大家快速掌握 AI Agent 智能体技术,我和团队落地大模型项目3年,帮助60多家企业落地近100个项目,根据我们企业级实战的项目经验,打造基于 DeepSeek 的 AI Agent 项目实战直播训练营,截至今天已经报名2万名学员,如此火爆!原价199元,DeepSeek 爆火,为了回馈粉丝的支持,价格直接降到 19元,再开放今天一天的报名权限,仅限99名,抢完立刻恢复到199元。
—5—
AI Agent 智能体为啥如此重要?
第一、这是大势所趋,随着 DeepSeek 春节期间的爆火,我们正在经历一场重大技术变革,还不像当年的互联网的兴起,这是一场颠覆性的变革,掉队就等于淘汰,因为未来所有应用都将被 AI Agent 智能体重写一遍;

第二、现在处于红利期,先入场的同学至少会享受4~5年的红利,拿高薪,并且会掌握技术的主动权和职业选择权。
第三、企业需求旺盛,越来越多的企业已经在 AI Agent 智能体领域进行落地,这为我们提供了丰富的岗位机会和广阔的发展空间。

第四、大厂都在战略布局的方向,不管是国外的微软、谷歌,还是国内的百度等大厂都在战略布局,随着春节期间 DeepSeek 火出圈,2025年必定是 AI Agent 智能体商业化的一年。
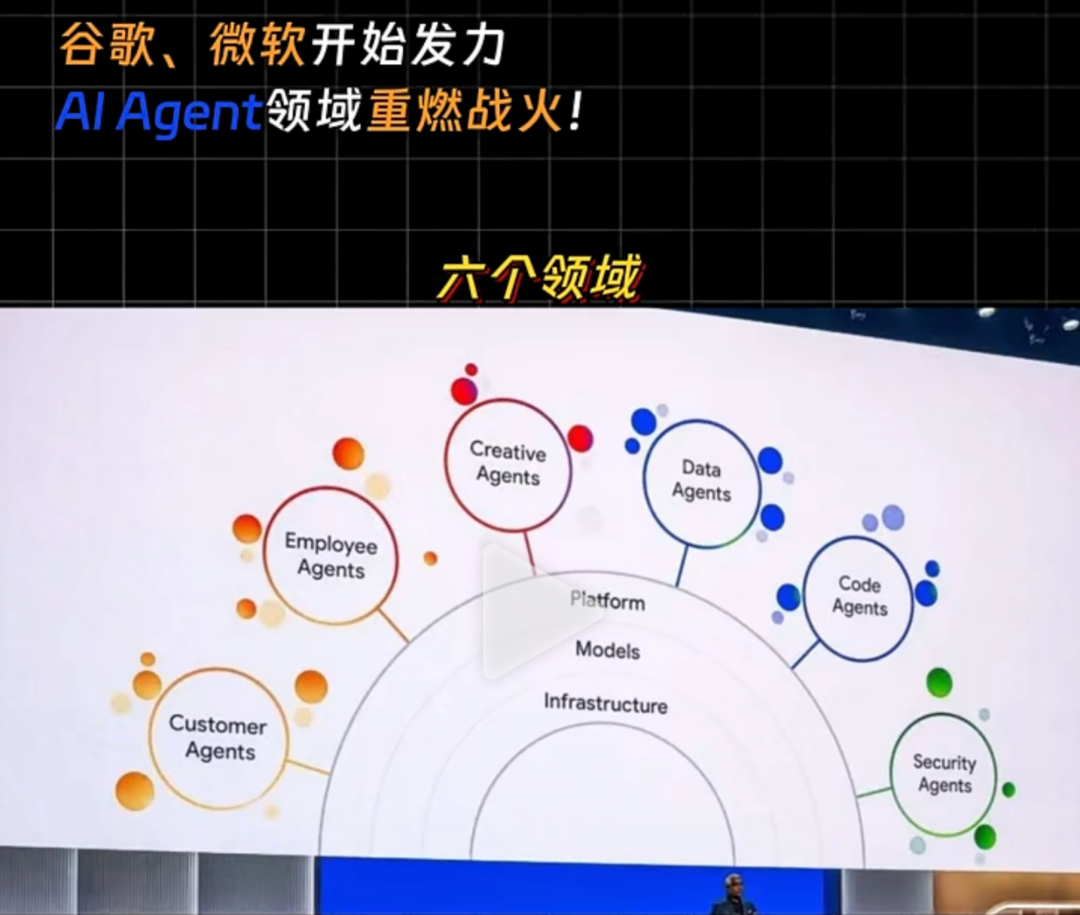
我和团队最近两年一直在研究大模型应用技术,我想说:大模型的价值太大了,AI Agent 智能体的潜力太大了!“未来所有应用都会被 AI Agent 智能体重写一遍”!这句话也是今年听到最多的一句话。我和团队这两年,尤其是最近3年已经帮助60多家企业落地了近100个 AI Agent 智能体的项目。我自己贴身感受:越来越多的企业的确都开始落地 AI Agent 智能体项目了。
因此 AI Agent 智能体足够重要,但也足够复杂,我这两年实践结论是,想开发出一个能够可靠稳定的 AI Agent 智能体应用实在太难了,大模型技术本身的复杂度,大模型推理的不确定性,响应速度性能问题等等,这些困难直接导致很多人对其望而却步,或是遇到问题无从下手。一般技术同学想要自己掌握 AI Agent 智能体着实很不容易!
为此我特意打造了一个为期3天的基于 DeepSeek 的 AI Agent 智能体企业实战训练营:这个训练营是我和团队落地大模型项目3年,根据我们企业级实战的项目经验,打造了基于 DeepSeek 的3天 AI Agent 项目实战直播训练营。

课程原价199元,DeepSeek 爆火,现在仅花19元就能拿下!文末再赠送5个报名福利!抢完立刻恢复199元!
—6—
3天直播训练营,你能收获什么?
3天的直播课,带你快速掌握基于 DeepSeek 的AI Agent 智能体核心技术和企业级项目实践经验。
模块一:AI Agent 智能体技术原理篇
全面拆解 AI Agent 智能体技术原理,深度掌握基于 DeepSeek 的 AI Agent 智能体三大能力及其运行机制。
模块二:AI Agent 智能体应用开发实战篇
深度讲解基于 DeepSeek 的 AI Agent 智能体技术选型及开发实践,学会开发 AI Agent 智能体核心技术能力。
模块三:AI Agent 智能体企业级案例实战篇
基于 DeepSeek,从需求分析、架构设计、架构技术选型、硬件资料规划、核心代码落地、服务治理等全流程实践,深度学习企业级 AI Agent 智能体项目全流程重点难点问题解决。

3天时间,你能学会什么?
在真实项目实践中,你会获得4项硬核能力:
第一、全面了解 DeepSeek 大模型、AI Agent 智能体的原理、架构和实现方法,掌握核心技术精髓。
第二、熟练使用 Dify/Coze 平台、DeepSeek、LangChain、AutoGen 等开发框架,为企业级技术实践打下坚实基础。
第三、通过企业级项目实战演练,能够独立完成基于 DeepSeek 的 AI Agent 智能体的设计开发和维护,学会解决企业级实际问题的能力。
第四、为职业发展提供更多可能性,无论是晋升加薪还是转行跳槽,提升核心技术竞争力。
限时优惠:
原价199元,DeepSeek 爆火,现在报名只需19元!文末再赠送5个报名福利!这是一个难得的机会,让我们一起踏上 AI Agent 智能技术之旅,开启技术新纪元!
—7—
今天报名再送5个配套福利
配套福利一:清华大学:DeepSeek 从入门到精通(2025),104 张页面,资料比较全,包括:DeeSeek 核心技术、DeepSeek 是什么?能做什么?如何使用 DeepSeek 等等。

配套福利二:AI Agent 智能体训练营配套学习资料,包括:PPT 课件、实战代码、企业级智能体案例和补充学习资料。

配套福利三:AI Agent 智能体训练营学习笔记,包含3天直播的所有精华。
配套福利四:AI Agent 智能体大厂面试真题100道!覆盖百度、阿里、腾讯、字节、美团、滴滴等大厂的100道真题,不论是跳槽还是升职加薪,参考意义都重大!

配套福利五:2024年中国 AI Agent 智能体行业研究报告!AI Agent 智能体是新的应用形态,大模型时代的“APP”,技术范式也发生了很大的变化, 此份研究报告探索新一代人机交互及协作范式,覆盖技术、产品、商业、企业落地应用等方面,非常值得一读!

原价199元,DeepSeek 爆火,现在19元就能拿下!
—8—
添加助教直播学习
购买后,添加助理进行直播学习👇

报名完添加助教二维码,立刻领取5重福利!
参考来源:
https://mp.weixin.qq.com/s/cSpdEqfuyyUaO17s4Fm_lg
⬇戳”阅读原文“,立即报名!
END

















 567
567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









